
ホームページ >テクノロジー周辺機器 >AI >KDD 2024|香港のルバーブチャオチームがグラフ機械学習分野の大規模モデルの「未知の境界」を深く分析
KDD 2024|香港のルバーブチャオチームがグラフ機械学習分野の大規模モデルの「未知の境界」を深く分析

- PHPzオリジナル
- 2024-07-22 16:54:341178ブラウズ

AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事の主な著者は香港大学のデータ インテリジェンス研究室の出身です。著者のうち、第1著者のRen Xubinと第2著者のTang Jiabinはともに香港大学データサイエンス学部の博士課程1年生で、指導教員はData Intelligence Lab@HKUのHuang Chao教授です。香港大学のデータ インテリジェンス研究室は、人工知能とデータ マイニングに関連する研究に特化しており、大規模言語モデル、グラフ ニューラル ネットワーク、情報検索、推奨システム、時空間データ マイニングなどの分野をカバーしています。これまでの研究には、一般的なグラフ大規模言語モデル GraphGPT、HiGPT、スマートシティ大規模言語モデル UrbanGPT、解釈可能な大規模言語モデル推奨アルゴリズム XRec などが含まれます。
今日の情報爆発の時代において、膨大なデータの海から深いつながりをどのように探索すればよいでしょうか?
これに関して、香港大学、ノートルダム大学、その他の機関の専門家や学者が、グラフ学習と大規模言語モデルの分野に関する最新のレビューで答えを明らかにしてくれました。
グラフは、現実世界のさまざまな関係を表す基本的なデータ構造として、その重要性は自明です。これまでの研究では、グラフ ニューラル ネットワークがグラフ関連のタスクで素晴らしい結果を達成したことが証明されています。しかし、グラフ データのアプリケーション シナリオが複雑になるにつれて、グラフ機械学習のボトルネック問題がますます顕著になってきています。近年、自然言語処理の分野では大規模言語モデルが注目を集めており、その優れた言語理解力と要約能力が注目を集めています。このため、大規模な言語モデルをグラフ学習テクノロジと統合して、グラフ学習タスクのパフォーマンスを向上させることが、業界で新たな研究のホットスポットとなっています。
このレビューでは、モデルの汎化能力、堅牢性、複雑なグラフデータを理解する能力など、グラフ学習の現在の分野における主要な技術的課題の詳細な分析を提供し、大規模モデルの将来のブレークスルーを期待しています。 「未知のフロンティア」という意味での可能性。

論文アドレス: https://arxiv.org/abs/2405.08011
プロジェクトアドレス: https://github.com/HKUDS/Awesome-LLM4Graph-Papers
HKU Data Intelligenceラボ: https://sites.google.com/view/chaoh/home
このレビューでは、グラフ学習に適用される最新の LLM を詳細にレビューし、フレームワーク設計に基づいた新しい分類方法を提案します。既存の技術を体系的に分類しています。これは 4 つの異なるアルゴリズム設計アイデアの詳細な分析を提供します。1 つはグラフ ニューラル ネットワークをプレフィックスとして使用し、2 つ目は大規模言語モデルをプレフィックスとして使用し、3 つ目は大規模言語モデルとグラフを統合するもので、4 つ目は大規模言語モデルのみを使用します。各カテゴリーについて、私たちは核となる技術的手法に焦点を当てています。さらに、このレビューはさまざまなフレームワークの長所とその限界についての洞察を提供し、将来の研究の潜在的な方向性を特定します。
香港大学データインテリジェンス研究所のHuang Chao教授率いる研究チームは、KDD 2024カンファレンスで、グラフ学習分野の大規模モデルが直面する「未知の境界」について徹底的に議論する予定です。
1 基礎知識
コンピュータサイエンスの分野において、グラフ(Graph)は重要な非線形データ構造であり、ノードセット(V)とエッジセット(E)から構成されます。各エッジはノードのペアを接続し、有向 (明確な始点と終点を持つ) または無向 (方向が指定されていない) の場合があります。特に注目すべき点は、テキスト属性グラフ (TAG) がグラフの特殊な形式として、文などのシリアル化されたテキスト機能を各ノードに割り当てることです。この機能は、大規模な言語モデルの時代には特に重要です。不可欠。テキスト属性グラフは、ノード セット V、エッジ セット E、およびテキスト特徴セット T から構成されるトリプレットとして正規に表すことができます。つまり、G * = (V, E, T) です。
グラフ ニューラル ネットワーク (GNN) は、グラフ構造データ用に設計された深層学習フレームワークです。隣接するノードからの情報を集約することにより、ノードの埋め込み表現を更新します。具体的には、GNN の各層は、現在のノードの埋め込みステータスと周囲のノードの埋め込み情報を包括的に考慮して次の層のノード埋め込みを生成する特定の関数を通じてノード埋め込み h を更新します。
Model Bahasa Besar (LLM) ialah model regresi yang berkuasa. Penyelidikan terkini telah menunjukkan bahawa model bahasa yang mengandungi berbilion parameter berfungsi dengan baik dalam menyelesaikan pelbagai tugas bahasa semula jadi, seperti terjemahan, penjanaan ringkasan dan pelaksanaan arahan, dan oleh itu dipanggil model bahasa besar. Pada masa ini, kebanyakan LLM termaju dibina berdasarkan blok Transformer menggunakan mekanisme query-key-value (QKV), yang menyepadukan maklumat dengan cekap dalam jujukan token. Mengikut arah aplikasi dan kaedah latihan perhatian, model bahasa boleh dibahagikan kepada dua jenis utama:
Pemodelan Bahasa Bertopeng (MLM) ialah sasaran pra-latihan yang popular untuk LLM. Ia melibatkan secara terpilih menutup token tertentu dalam urutan dan melatih model untuk meramalkan token bertopeng ini berdasarkan konteks sekeliling. Untuk mencapai ramalan yang tepat, model akan mempertimbangkan secara menyeluruh persekitaran kontekstual unsur-unsur perkataan bertopeng.
Pemodelan Bahasa Bersebab (CLM) ialah satu lagi objektif pra-latihan arus perdana untuk LLM. Ia memerlukan model untuk meramalkan token seterusnya berdasarkan token sebelumnya dalam jujukan. Dalam proses ini, model hanya bergantung pada konteks sebelum unsur perkataan semasa untuk membuat ramalan yang tepat.
2 Pembelajaran graf dan model bahasa besar
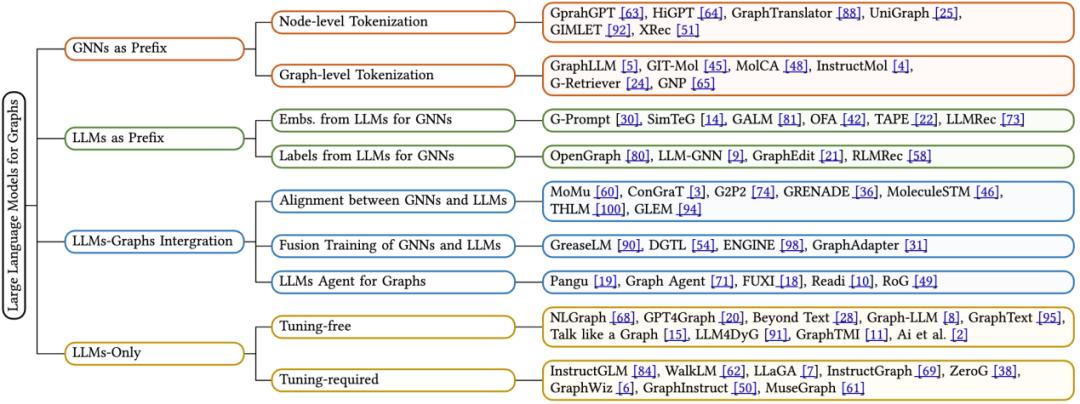
Dalam artikel ulasan ini, penulis bergantung pada proses inferens model - iaitu pemprosesan data graf, data teks dan model bahasa besar (LLMs) ) Kaedah interaktif, kaedah pengelasan baru dicadangkan. Secara khusus, kami meringkaskan empat jenis reka bentuk seni bina model utama, seperti berikut:
GNN sebagai Awalan: Dalam kategori ini, rangkaian saraf graf (GNN) berfungsi sebagai komponen utama, bertanggungjawab untuk memproses data dan menyediakan LLM teg kesedaran struktur (seperti teg tahap nod, tahap tepi atau tahap graf) untuk inferens seterusnya.
LLM sebagai Awalan: Dalam kategori ini, LLM memproses data graf pertama disertai dengan maklumat teks dan seterusnya menyediakan pembenaman nod atau label yang dijana untuk latihan rangkaian saraf graf.
LLMs-Graphs Integration (LLMs and Graphs Integration): Kaedah dalam kategori ini berusaha untuk mencapai penyepaduan yang lebih mendalam antara LLM dan data graf, seperti melalui latihan gabungan atau penjajaran dengan GNN. Selain itu, ejen berasaskan LLM telah dibina untuk berinteraksi dengan maklumat graf.
LLM-Sahaja (hanya menggunakan LLM): Kategori ini mereka bentuk pembayang dan teknik praktikal untuk membenamkan data berstruktur graf ke dalam jujukan token untuk memudahkan inferens oleh LLM. Pada masa yang sama, beberapa kaedah turut menggabungkan penanda berbilang modal untuk memperkayakan lagi keupayaan pemprosesan model.
2.1 GNN sebagai Awalan
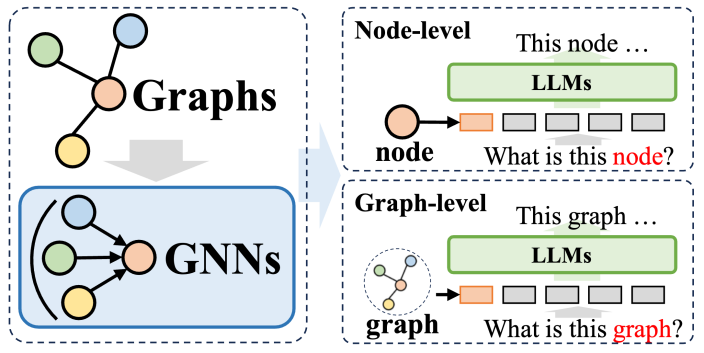
Dalam sistem kaedah di mana rangkaian neural graf (GNN) digunakan sebagai awalan, GNN memainkan peranan sebagai model pengekod bahasa struktur (LLM) dengan ketara meningkatkan prestasi pada struktur graf Keupayaan penghuraian data, dengan itu memanfaatkan pelbagai tugas hiliran. Dalam kaedah ini, GNN terutamanya berfungsi sebagai pengekod, yang bertanggungjawab untuk menukar data graf kompleks kepada jujukan token graf yang mengandungi maklumat struktur yang kaya, kemudiannya dimasukkan ke dalam LLM, yang konsisten dengan proses pemprosesan bahasa semula jadi.
Kaedah ini boleh dibahagikan secara kasar kepada dua kategori: Yang pertama ialah tokenisasi peringkat nod, iaitu, setiap nod dalam struktur graf dimasukkan secara individu ke dalam LLM. Tujuan pendekatan ini adalah untuk membolehkan LLM memahami dengan mendalam maklumat struktur peringkat nod dan mengenal pasti korelasi dan perbezaan antara nod yang berbeza dengan tepat. Yang kedua ialah tokenisasi peringkat graf, yang menggunakan teknologi pengumpulan khusus untuk memampatkan keseluruhan graf ke dalam urutan token panjang tetap, bertujuan untuk menangkap keseluruhan semantik peringkat tinggi struktur graf.
Untuk tokenisasi peringkat nod, ia amat sesuai untuk tugas pembelajaran graf yang memerlukan pemodelan maklumat struktur halus peringkat nod, seperti pengelasan nod dan ramalan pautan. Dalam tugasan ini, model perlu dapat membezakan perbezaan semantik halus antara nod yang berbeza. Rangkaian saraf graf tradisional menjana perwakilan unik untuk setiap nod berdasarkan maklumat nod jiran, dan kemudian melakukan pengelasan atau ramalan hiliran berdasarkan ini. Kaedah tokenisasi peringkat nod boleh mengekalkan ciri-ciri struktur unik setiap nod pada tahap yang paling besar, yang memberi manfaat besar kepada pelaksanaan tugas hiliran.
Sebaliknya, tokenisasi peringkat graf adalah untuk menyesuaikan diri dengan tugasan peringkat graf yang memerlukan pengekstrakan maklumat global daripada data nod. Di bawah rangka kerja GNN sebagai awalan, melalui pelbagai operasi pengumpulan, tokenisasi peringkat graf boleh mensintesis banyak perwakilan nod ke dalam perwakilan graf bersatu, yang bukan sahaja menangkap semantik global graf, tetapi juga meningkatkan lagi prestasi pelbagai tugas hiliran Kesan pelaksanaan.
2.2 LLM sebagai Awalan
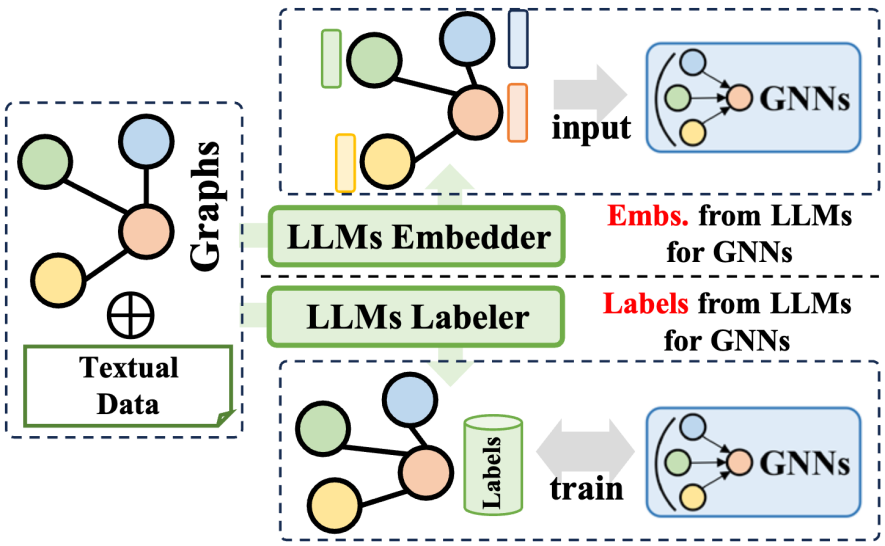
大規模言語モデル (LLM) プレフィックス メソッドは、大規模言語モデルによって生成された豊富な情報を利用して、グラフ ニューラル ネットワーク (GNN) のトレーニング プロセスを最適化します。この情報には、LLM によって生成されたテキスト コンテンツ、タグ、埋め込みなどのさまざまなデータが含まれます。この情報がどのように適用されるかに応じて、関連テクノロジーは 2 つの主要なカテゴリに分類できます。1 つは LLM によって生成された埋め込みを使用して GNN のトレーニングを支援するもので、もう 1 つは LLM によって生成されたラベルを GNN のトレーニング プロセスに統合するものです。 。
LLM エンベディングの利用 に関して、GNN の推論プロセスにはノード エンベディングの転送と集約が含まれます。ただし、初期ノードの埋め込みの品質と多様性は、レコメンダー システムの ID ベースの埋め込みや引用ネットワークのバッグ オブ ワード モデルの埋め込みなど、ドメインによって大きく異なり、明瞭さと豊富さに欠ける可能性があります。この埋め込み品質の欠如により、GNN のパフォーマンスが制限されることがあります。さらに、ユニバーサル ノード埋め込み設計の欠如は、さまざまなノード セットを扱うときの GNN の汎化能力にも影響します。幸いなことに、言語の要約とモデリングにおいて大規模言語モデルの優れた機能を活用することで、GNN に意味のある効果的な埋め込みを生成することができ、それによってトレーニング パフォーマンスを向上させることができます。
LLM ラベルの統合 に関して、別の戦略は、これらのラベルを監視信号として使用して、GNN のトレーニング効果を高めることです。ここでの教師ありラベルには従来の分類ラベルに限定されず、埋め込み、グラフ、その他の形式も含まれることに注意してください。 LLM によって生成された情報は、GNN の入力データとして直接使用されませんが、より洗練された最適化監視信号を構成するため、GNN がさまざまなグラフ関連タスクでより良いパフォーマンスを達成できるようになります。
2.3 LLMとグラフの統合
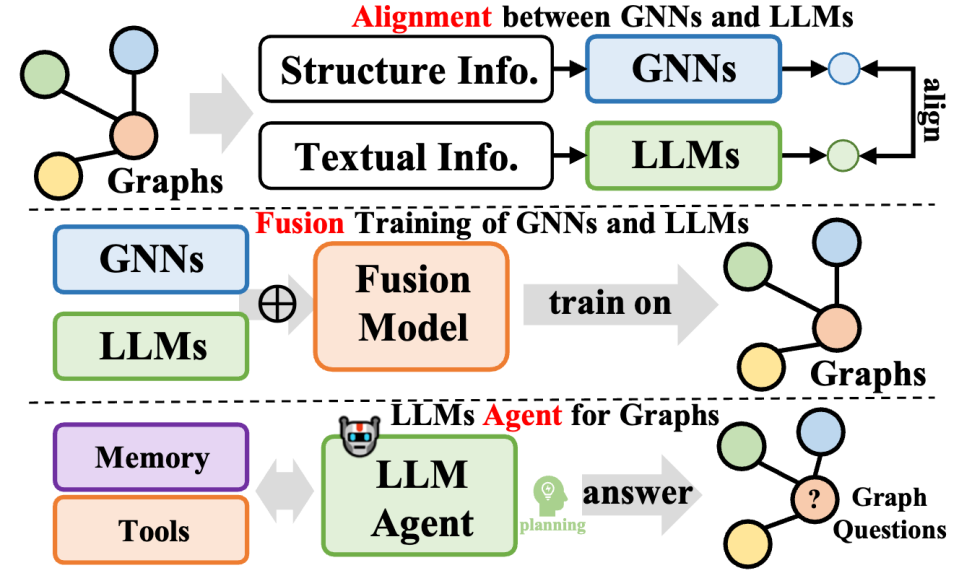
このタイプの方法は、大規模な言語モデルとグラフデータをさらに統合し、多様な方法論をカバーし、グラフ処理タスクにおける大規模言語モデル(LLM)の機能を向上させるだけでなく、同時に、グラフ ニューラル ネットワーク (GNN) のパラメーター学習も最適化されます。これらの方法は 3 つのタイプに要約できます。1 つは GNN と LLM の融合であり、モデル間の深い統合と共同トレーニングを実現することを目的としています。もう 1 つは、2 つのモデルの表現またはタスク レベルに焦点を当てた GNN と LLM 間の調整です。 3 つ目は、LLM に基づいて自律エージェントを構築し、グラフ関連のタスクを計画および実行することです。
GNN と LLM の融合に関しては、通常、GNN は構造化データの処理に重点を置き、LLM はテキスト データの処理に優れており、その結果、2 つは異なる特徴空間を持つことになります。この問題に対処し、GNN と LLM の学習における両方のデータ モダリティの共通の利益を促進するために、一部の方法では、対照学習や期待値最大化 (EM) 反復トレーニングなどの手法を採用して、2 つのモデルの特徴空間を調整します。このアプローチにより、グラフとテキスト情報のモデリングの精度が向上し、さまざまなタスクのパフォーマンスが向上します。
GNN と LLM の調整に関しては、表現の調整により両方のモデルの共同最適化と埋め込みレベルの調整が実現されますが、推論段階では依然として独立しています。 LLM と GNN の間のより緊密な統合を実現するために、一部の研究では、LLM のトランスフォーマー層と GNN のグラフ ニューラル層を組み合わせるなど、より深いモジュール アーキテクチャの融合の設計に焦点を当てています。 GNN と LLM を共同でトレーニングすることにより、グラフ タスクの両方のモジュールに双方向のゲインをもたらすことが可能になります。
最後に、LLM ベースのグラフ エージェント に関して、命令の理解と問題解決のための自己計画における LLM の優れた能力の助けを借りて、新しい研究の方向性は、処理または研究するための LLM に基づいた自律エージェントを構築することです。 -関連のタスク。通常、このようなエージェントには、記憶、知覚、および行動の 3 つのモジュールが含まれており、特定のタスクを解決するための観察、記憶の想起、および行動のサイクルを形成します。グラフ理論の分野では、LLM に基づくエージェントはグラフ データと直接対話し、ノード分類やリンク予測などのタスクを実行できます。
2.4 LLMのみ
このレビューでは、LLMのみ、いわゆる「のみ」LLMに関する章で、さまざまなグラフ指向タスクへの大規模言語モデル(LLM)の直接適用について詳しく説明します。カテゴリー。これらのメソッドの目的は、LLM がグラフ構造情報を直接受け入れて理解し、この情報を組み合わせてさまざまな下流タスクについて推論できるようにすることです。これらの方法は主に 2 つのカテゴリに分類できます。i) LLM が理解できるキューを設計することを目的とした微調整を必要とせず、事前トレーニングされた LLM にグラフ指向のタスクの実行を直接促す方法。ii) 微調整を必要とする方法。 -チューニング、に焦点を当てる グラフは特定の方法でシーケンスに変換され、グラフのトークンのシーケンスと自然言語のトークンのシーケンスは微調整方法によって調整されます。
微調整不要のアプローチ: グラフ データの固有の構造特性を考慮すると、2 つの重要な課題が生じます。1 つ目は、自然言語形式でグラフを効果的に構築すること、2 つ目は、大規模言語モデル (LLM) が正確に理解できるかどうかを判断することです。言語形式はグラフ構造を表します。これらの問題に対処するために、研究者のグループは、純粋なテキスト空間でグラフをモデル化および推論するためのチューニング不要の手法を開発し、それによって構造的理解を強化するための事前トレーニング済み LLM の可能性を探りました。
微調整が必要な手法: グラフの構造情報を平文で表現することには限界があるため、グラフを入力する際にノードトークン列や自然言語トークン列としてグラフを利用する方法が最近の主流となっています。大規模言語モデル (LLM) の調整。前述のプレフィックス方式としての GNN とは異なり、調整が必要な唯一の LLM 方式は、グラフ エンコーダーを放棄し、代わりにグラフ構造を反映する特定のテキスト記述を使用し、プロンプト内で慎重に設計されたプロンプトを使用します。これは、さまざまなダウンストリームに関連します。ミッションでは期待できるパフォーマンスが達成されました。
3 将来の研究の方向性
このレビューでは、グラフの分野における大規模言語モデルのいくつかの未解決の問題と潜在的な将来の研究方向性についても説明します:
マルチモーダル グラフと大規模言語モデル (LLM) の融合。 最近の研究では、大規模な言語モデルが、画像やビデオなどのマルチモーダル データの処理と理解において並外れた能力を実証していることが示されています。この進歩により、LLM を複数のモーダル フィーチャを含むマルチモーダル マップ データと組み合わせる新たな機会が提供されます。このようなグラフデータを処理できるマルチモーダルLLMを開発することで、文字、視覚、聴覚などの複数のデータを総合的に考慮してグラフ構造をより正確かつ網羅的に推論することが可能になります。
効率を向上させ、コンピューティングコストを削減します。 現在、LLM のトレーニングと推論フェーズにかかる高い計算コストが開発の大きなボトルネックとなっており、数百万のノードを含む大規模なグラフ データを処理する能力が制限されています。 LLM をグラフ ニューラル ネットワーク (GNN) と組み合わせようとすると、2 つの強力なモデルが融合するため、この課題はさらに深刻になります。したがって、LLM と GNN のトレーニングの計算コストを削減するための効果的な戦略を発見して実装することが急務となっています。これにより、現在の制限が緩和されるだけでなく、グラフ関連のタスクにおける LLM の適用範囲がさらに拡大されます。これにより、データ サイエンスにおける実際的な価値と影響力が向上します。
多様なグラフタスクに対処します。 現在の調査方法は、リンク予測やノード分類などの従来のグラフ関連タスクに主に焦点を当てています。ただし、LLM の強力な機能を考慮すると、グラフ生成、グラフ理解、グラフベースの質問応答など、より複雑で生成的なタスクの処理における LLM の可能性をさらに探る必要があります。これらの複雑なタスクをカバーするために LLM ベースの手法を拡張することで、さまざまな分野で LLM を適用するための新たな機会が無数に開かれます。たとえば、創薬の分野では、LLM は新しい分子構造の生成を容易にすることができ、ソーシャル ネットワーク分析の分野では、LLM はナレッジ グラフ構築の分野で複雑な関係パターンに対する深い洞察を提供できます。より包括的で文脈的に正確な知識ベース。
ユーザーフレンドリーなグラフエージェントを構築します。 現在、グラフ関連タスク用に設計された LLM ベースのエージェントのほとんどは、単一タスク用にカスタマイズされています。これらのエージェントは通常、シングルショット モードで動作し、問題を一度に解決するように設計されています。ただし、理想的な LLM ベースのエージェントは、ユーザーが使いやすく、ユーザーが提示する多様な自由形式の質問に応じて、グラフ データ内の回答を動的に検索できる必要があります。この目標を達成するには、柔軟性と堅牢性を兼ね備え、ユーザーとの反復的な対話が可能で、複雑なグラフ データの処理に熟達して正確で関連性の高い回答を提供するエージェントを開発する必要があります。これには、エージェントが高い適応性を備えているだけでなく、強力な堅牢性を実証する必要もあります。
4 概要
このレビューでは、グラフ データ用にカスタマイズされた大規模言語モデル (LLM) について詳細な議論を行い、モデルベースの推論フレームワークに基づいて、さまざまなモデルを 4 つのタイプに注意深く分類する分類方法を提案しました。 . ユニークなフレームデザイン。各設計には、独自の強みと制限があります。それだけでなく、このレビューではこれらの機能について包括的に説明し、グラフ データ処理タスクを扱う際の各フレームワークの可能性と課題を深く調査しています。この研究作業は、グラフ関連の問題を解決するために大規模な言語モデルを探索および適用することに熱心な研究者に参考リソースを提供することを目的としており、最終的にはこの研究を通じて、言語モデルのアプリケーションのより深い理解を促進することが期待されています。 LLMとグラフデータ、さらにはこの分野に技術革新とブレークスルーを生み出します。
以上がKDD 2024|香港のルバーブチャオチームがグラフ機械学習分野の大規模モデルの「未知の境界」を深く分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。