
ホームページ >テクノロジー周辺機器 >AI >Google チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。
Google チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-07-19 21:45:12578ブラウズ

編集者 | ScienceAI
現代の医療システムは、肺機能マップ、光電脈波計 (PPG)、心電図 (ECG) 記録、CT スキャン、MRI 画像などの大量の高次元臨床データ (HDCD) を生成します。データを単一の 2 進数または連続数値で要約することはできません。
私たちのゲノムと HDCD の関係を理解することは、この病気に対する理解が深まるだけでなく、この病気の治療法の開発にも重要です。
最近、Google Research のゲノミクス チームは、HDCD を使用して病気や生物学的特徴を特徴付けることで進歩を遂げました。
研究チームは、遺伝的変異とHDCDの間の関連性を発見するために、教師なし深層学習モデル、低次元埋め込み遺伝子発見のための表現学習(REGLE)を提案しました。
REGLE は、新しい遺伝子発見手法として、高次元の臨床データに隠された情報を活用でき、計算効率が高く、疾患ラベルを必要とせず、専門家が定義した知識からの情報を統合できます。
全体として、REGLE には既存の専門家が定義したシグネチャで捕捉される情報を超える臨床関連情報が含まれており、遺伝子発見と疾患予測の向上が可能になります。
関連研究は「高次元臨床データ上の教師なし表現学習によりゲノム発見と予測が向上」と題され、7月8日付けの「Nature Genetics」に掲載されました。

論文リンク: https://www.nature.com/articles/s41588-024-01831-6
HDCDの隠された情報を明らかにする
遺伝子とHDCD Aの関係に関する研究簡単なアプローチは、各データ座標に対して GWAS を実行することです。たとえば、医療画像の各ピクセルの値の変化を調べることができます。このアプローチは計算コストが高く、隣接する座標間の相関性が高く、複数のテスト負荷が大きいため、重要な関連性を検出する能力が低くなります。
より一般的なアプローチは、GWAS のターゲット特徴または表現型として HDCD から抽出された少数の専門家定義特徴 (EDF) に焦点を当てることです。 EDF には、肺活量測定による努力肺活量 (FVC) や 1 秒努力呼気量 (FEV1) などの臨床的に知られている機能を含めることができます。
これらの EDF は専門家によって発見された重要な機能ですが、HDCD でエンコードされた信号を完全にはキャプチャできない可能性があると想定されているため、これらの信号に対して GWAS を実行しても HDCD の可能性を最大限に活用できない可能性があります。
REGLE は、変分オートエンコーダー (VAE) モデルを使用してこれらの制限を克服することを目的としています。この方法は 3 つの主要なステップで構成されます:
(1) VAE を通じて HDCD の非線形、低次元、もつれの解いた表現 (つまり、エンコードまたは埋め込み) を学習します。
(2) エンコードされた座標ごとに個別に GWAS を実行します。
(3) コード座標からの多遺伝子リスク スコア (PRS) を一般的な生物学的機能の遺伝スコアとして使用し、これらのスコアを組み合わせて特定の疾患または形質 (少数の疾患ラベルが与えられた場合) の PRS を作成する可能性があります。 注目すべきことに、REGLE では、修正された VAE アーキテクチャのデコーダの入力に関連する EDF を選択的に含めることもできるため、エンコーダは EDF によって表されていない残留信号のみを学習することができます。
肺と循環機能の新規遺伝子座の検出
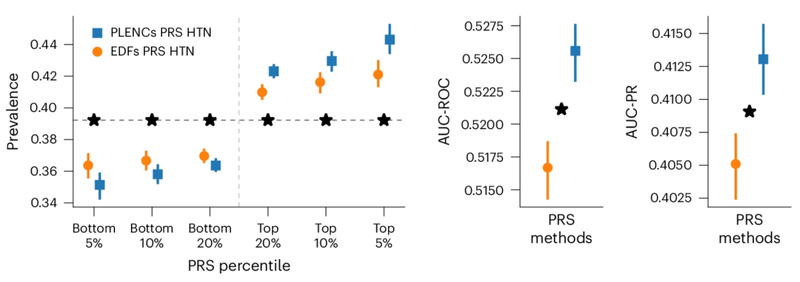
研究者らは、肺機能を測定するスパイロメトリーと心血管機能を測定するスパイロメトリーという 2 つの高次元臨床データモダリティを使用して、REGLE の能力を実証しました。 .PPG。どちらも診療所または消費者向けウェアラブル デバイスで非侵襲的かつ比較的安価に収集でき、両方のモダリティにはよく知られた特徴があります)。 同じ次元のスパイロメトリーとPPGシグネチャーを用いたゲノムワイド関連研究と比較して、REGLEの学習されたコーディングの研究は、肺と循環機能に関連する既知の遺伝子座(遺伝子座)の大部分を回復し、同時に他の部位(例えば、 、PPG の重要なサイトは 45% 増加しました)。これらの部位がさらなる分析やウェットラボ実験で検証されれば、新しい薬剤の標的となる可能性があります。 遺伝的リスクスコアの改善多遺伝子リスクスコア (PRS) は、特定の形質に対する多くの遺伝的変異の推定影響を単一の数値で表したものです。 REGLE 埋め込みに関するゲノムワイド関連研究によって作成された PRS は、少数の疾患シグネチャのみを使用して結合され、その特定の疾患の PRS を生成できます。研究者らは、スパイロメトリーのコーディングから作成された肺機能 PRS は、専門家が定義した特徴量、PCA、PRS などの既存の方法と比較して COPD と喘息の予測を改善し、リスク スペクトルの両端で特徴量 PRS を上回っていることを観察しました。以下に示すように、喘息および COPD に関する複数の独立したデータセット (COPDGene、eMERGE III、Indiana Biobank、EPIC-Norfolk) にわたる複数の指標 (AUC-ROC、AUC-PR、および Pearson 相関) における統計的に有意な改善が見られます。

同様に、PPG の REGLE 埋め込みから派生した PRS は、高血圧と収縮期血圧 (SBP) の予測を改善します。 PPG エンコードおよび PPG シグネチャによって生成された高血圧および SBP PRS は、3 つの独立したデータセット (COPDGene、eMERGE III、EPIC-Norfolk) および英国バイオバンクが保有するテスト セットで評価されました。
複数のデータセットにわたって、高血圧とSBPの両方について、専門家が定義した特徴からのPRSを使用するよりも、PPGコーディングからのPRSを使用する方が一貫した改善傾向があることが観察されました。

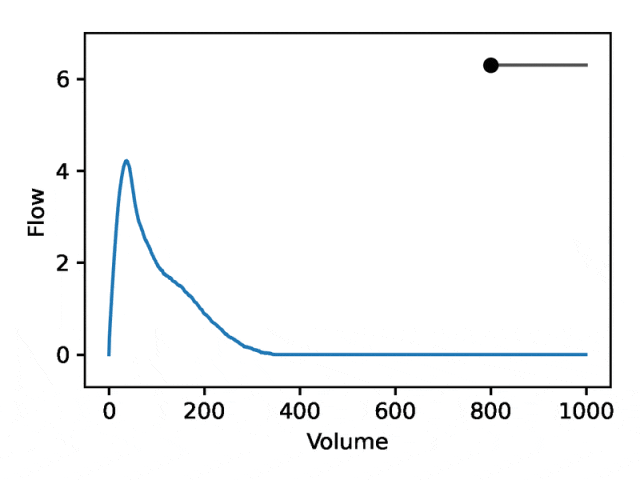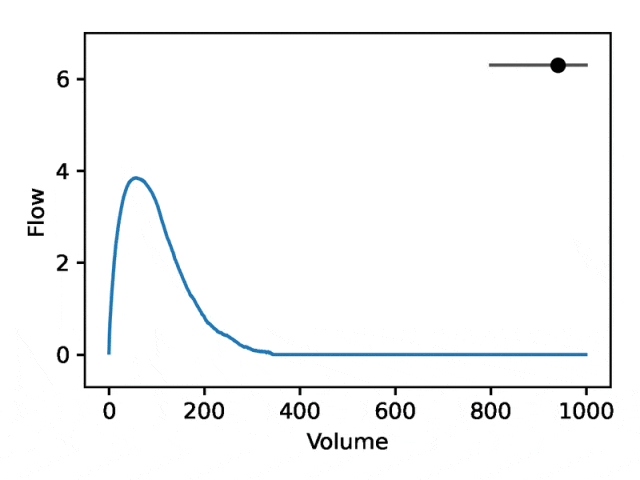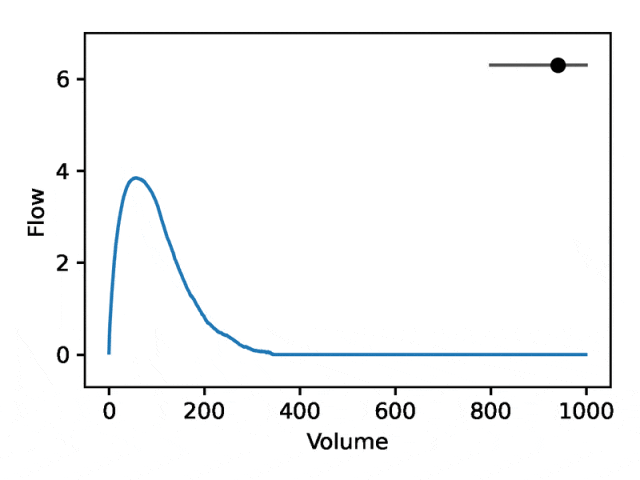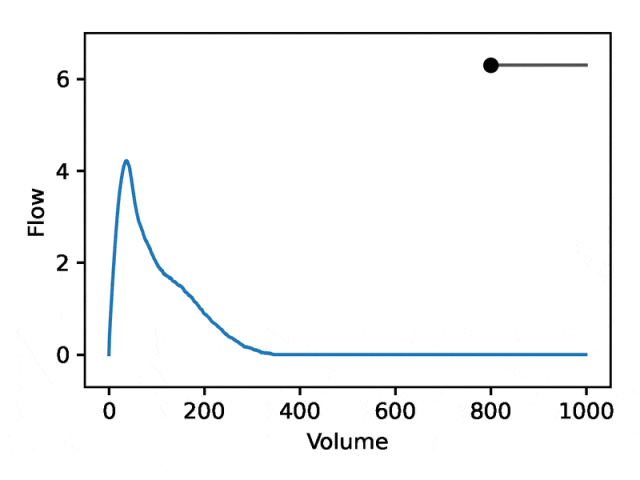
部分的に解釈可能な埋め込み
REGLE の生成特性を利用して、専門家が定義した特徴量の値を固定し、一方のエンコード座標を変更しながらもう一方のエンコード座標を変更することで、肺活量測定におけるエンコード座標の影響を研究します。エンコード座標はゼロです。次に、トレーニングされたモデルのデコーダー部分のみを使用して、対応する肺活量測定マップが生成されます。
典型的な流量肺活量測定は、次の 2 つの異なる部分で構成されます: (1) 流量が体積の増加とともに単調増加する、ピーク流量に達するまでの比較的短いセクション (2) 流量が減少する肺活量測定セクションの主要部分。単調に。
下の画像は、最初の座標を変更すると、最初の部分を相対的に固定したまま 2 番目の部分を拡大または縮小 (負の傾き) することと同等であることを示しています。実際、呼吸器科医がディップと呼ぶ曲線の 2 番目の部分の凹みは、標準の EDF では十分に表現されていない気道閉塞の指標です。
ヒトの形質と病気の遺伝的基盤を解明する
REGLE は、遺伝子解析、改善された新規遺伝子座の発見、およびリスク予測を実行する教師なし学習手法です。 EDF を手動で大規模に発見するのは難しいため、HDCD 表現の教師なし学習はゲノム発見にとって魅力的です。
REGLE フレームワークは、従来の VAE アーキテクチャを変更することで、モデリングにおけるこれらの機能の原則的な使用もサポートしています。 REGLE は 2 つの臨床データ モダリティ (肺活量測定と PPG) で実証されており、臨床現場で日常的に測定することも、スマートフォンやウェアラブル デバイスを介して受動的かつ非侵襲的に測定することもできます。
REGLE は、ラベル付きデータなしで臓器機能に対する遺伝的影響を特定するメカニズムを提供し、専門家の特徴をモデルに組み込むことができます。また、少数のラベルを使用して疾患および形質に固有の PRS を作成する方法も提供します。将来的には、人間の形質や病気の遺伝的基盤をさらに解明するために、このようなアプローチがますます利用されることになるでしょう。
参考コンテンツ:https://research.google/blog/harnessing-hidden-genetic-information-in-clinical-data-with-regle/
以上がGoogle チームは、高効率でラベルを必要とせず、AI を使用して臨床データをマイニングし、遺伝子発見と疾患予測を改善し、その成果が Nature サブジャーナルに掲載されました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。