AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事の主な著者は Huang Yichong です。 Huang Yichong はハルビン工業大学のソーシャル コンピューティングおよび情報検索研究センターの博士課程の学生であり、Pengcheng Laboratory のインターンとして Qin Bing 教授と Feng Xiaocheng 教授の下で勉強しています。研究の方向性には、大規模言語モデルのアンサンブル学習と多言語大規模モデルが含まれており、自然言語処理のトップカンファレンスである ACL、EMNLP、および COLING で関連論文が発表されています。 大規模言語モデルが驚くべき言語知能を実証する中、大手 AI 企業は独自の大規模モデルを立ち上げました。これらの大規模なモデルは通常、さまざまな分野やタスクにおいて独自の強みを持っており、それらを統合して相互補完的な可能性を引き出す方法は、AI 研究の最前線のトピックとなっています。 最近、ハルビン工業大学と彭城研究所の研究者らは、「トレーニング不要の異種大規模モデルアンサンブル学習フレームワーク」DeePEnを提案しました。 複数のモデルによって生成された応答をフィルタリングおよび融合するように外部モジュールをトレーニングする以前の方法とは異なり、DeePEn はデコード プロセス中に複数のモデル出力の確率分布を融合し、各ステップの出力トークンを共同で決定します。比較すると、この方法はあらゆるモデルの組み合わせに迅速に適用できるだけでなく、統合されたモデルが相互に内部表現 (確率分布) にアクセスできるようになり、より深いモデルのコラボレーションが可能になります。 結果は、DeePEn が複数の公開データセットで大幅な改善を達成し、大規模モデルのパフォーマンス限界を効果的に拡張できることを示しています: 
- 論文タイトル: ディープ並列コラボレーションによる異種大言語モデルのためのアンサンブル学習
- 論文アドレス: https://arxiv.org/abs/2404.12715
- コードアドレス: https://github.com/OrangeInSouth/DeePEn
異種大規模モデル統合の中核となる困難は、モデル間の語彙の違いの問題をどのように解決するかです。この目的を達成するために、DeePEn は、相対表現理論に基づいて、複数のモデル語彙間の共有トークンで構成される統一相対表現空間を構築します。デコード段階では、DeePEn は、さまざまな大規模モデルによって出力された確率分布をこの空間にマッピングして融合します。 プロセス全体でパラメーターのトレーニングは必要ありません。 下の写真はDeePEnのメソッドを示しています。アンサンブル用の N 個のモデルが与えられると、DeePEn はまず変換行列 (つまり、相対表現行列) を構築し、複数の不均質な絶対空間から確率分布を統一された相対空間にマッピングします。各復号化ステップで、すべてのモデルが順方向計算を実行し、N 個の確率分布を出力します。これらの分布は相対空間にマッピングされ、集約されます。最後に、集約結果はあるモデル (マスター モデル) の絶対空間に変換されて戻され、次のトークンが決定されます。
図1:概略図。このうち、相対表現変換行列は、語彙内の各トークンとモデル間で共有されるアンカートークンとの単語埋め込み類似度を計算することで得られます。 統合される N モデルが与えられた場合、DeePEn は最初にすべてのモデル語彙の共通部分、つまり共有語彙を見つけます。 、そして、サブセット A⊆C を抽出するか、すべての共有単語をアンカー単語セット A=C として使用します。 各モデル について、DeePEn は語彙内の各トークンとアンカー トークンの間の埋め込み類似性を計算し、相対表現行列 を取得します。最後に、外れ値単語の相対表現劣化問題を克服するために、論文の著者は相対表現行列に対して行正規化を実行し、行列の各行に対してソフトマックス演算を実行して正規化された相対表現行列 を取得します。 各復号ステップで、モデルが確率分布を出力すると、DeePEnは正規化された相対表現行列を使用してを相対表現に変換します。 dan lakukan purata wajaran semua perwakilan relatif untuk mendapatkan perwakilan relatif terkumpul:
di mana ialah berat kerjasama model . Penulis mencuba dua kaedah untuk menentukan nilai berat kolaboratif: (1) DeepPEn-Avg, yang menggunakan pemberat yang sama untuk semua model; (2) DeePEn-Adapt, yang menetapkan pemberat untuk setiap model secara berkadar berdasarkan prestasi set pengesahannya.
Pemetaan songsang perwakilan relatifUntuk memutuskan token seterusnya berdasarkan perwakilan relatif terkumpul, DeePEn menukarnya daripada ruang relatif kembali kepada ruang mutlak model utama (model berprestasi terbaik pada set pembangunan ). Untuk mencapai transformasi songsang ini, DeepPEn menggunakan strategi berasaskan carian untuk mencari perwakilan mutlak yang perwakilan relatifnya adalah sama dengan perwakilan relatif terkumpul:
di mana mewakili ruang mutlak model , dan ialah ukuran perwakilan relatif fungsi kehilangan (KL divergence) antara jarak. DeePEn menggunakan kecerunan fungsi kehilangan berkenaan dengan perwakilan mutlak untuk membimbing proses carian dan melakukan carian secara berulang. Secara khususnya, DeepPEn memulakan titik permulaan carian kepada perwakilan mutlak asal model induk dan mengemas kininya:
Di mana η ialah hiperparameter yang dipanggil kadar pembelajaran ensemble relatif, dan T ialah bilangan langkah lelaran carian. Akhir sekali, gunakan perwakilan mutlak yang dikemas kini untuk menentukan token yang akan dikeluarkan dalam langkah seterusnya.
Jadual 1: Keputusan eksperimen utama. Bahagian pertama ialah prestasi model tunggal, bahagian kedua ialah pembelajaran ensemble model top-2 pada setiap set data, dan bahagian ketiga ialah penyepaduan model top-4. . Seperti yang ditunjukkan dalam Jadual 1, terdapat perbezaan yang ketara dalam prestasi model besar yang berbeza pada set data yang berbeza. Sebagai contoh, LLaMA2-13B mencapai keputusan tertinggi pada set data TriviaQA dan NQ, tetapi tidak berada dalam kedudukan empat teratas dalam empat tugasan yang lain. Penyatuan pengedaran telah mencapai peningkatan yang konsisten
pada pelbagai set data. Seperti yang ditunjukkan dalam Jadual 1, DeePEn-Avg dan DeePEn-Adapt mencapai peningkatan prestasi pada semua set data. Pada GSM8K, digabungkan dengan pengundian, peningkatan prestasi +11.35 telah dicapai. Jadual 2: Prestasi pembelajaran ensemble di bawah bilangan model yang berbeza. Apabila bilangan model bersepadu meningkat, prestasi penyepaduan mula-mula meningkat dan kemudian menurun
. Pengarang menambah model pada ensemble mengikut urutan dari tinggi ke rendah mengikut prestasi model, dan kemudian memerhatikan perubahan prestasi. Seperti yang ditunjukkan dalam Jadual 2, apabila model dengan prestasi lemah diperkenalkan secara berterusan, prestasi penyepaduan mula-mula meningkat dan kemudian menurun.
s dan model pakar terjemahan pada set data terjemahan mesin berbilang bahasa Flores.
(4) Sepadukan model besar dan model pakar untuk meningkatkan prestasi tugasan secara berkesan
. Penulis juga menyepadukan model besar LLaMA2-13B dan model terjemahan pelbagai bahasa NLLB pada tugas terjemahan mesin. Seperti yang ditunjukkan dalam Jadual 3, penyepaduan antara model besar umum dan model pakar khusus tugasan boleh meningkatkan prestasi dengan ketara. Kesimpulan
Terdapat aliran model besar yang tidak berkesudahan, tetapi sukar bagi satu model untuk menghancurkan model lain secara menyeluruh pada semua tugas. Oleh itu, cara memanfaatkan kelebihan pelengkap antara model yang berbeza telah menjadi hala tuju penyelidikan yang penting. Rangka kerja DeepPEn yang diperkenalkan dalam artikel ini menyelesaikan masalah perbezaan perbendaharaan kata antara model besar yang berbeza dalam gabungan pengedaran tanpa sebarang latihan parameter. Sebilangan besar percubaan menunjukkan bahawa DeepPEn telah mencapai peningkatan prestasi yang stabil dalam tetapan pembelajaran ensemble dengan tugasan yang berbeza, nombor model yang berbeza dan seni bina model yang berbeza. 以上がLLama+Mistral+…+Yi=? トレーニング不要の異種大規模モデル統合学習フレームワーク DeePEn が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






 、そして、サブセット A⊆C を抽出するか、すべての共有単語をアンカー単語セット A=C として使用します。
、そして、サブセット A⊆C を抽出するか、すべての共有単語をアンカー単語セット A=C として使用します。  について、DeePEn は語彙内の各トークンとアンカー トークンの間の埋め込み類似性を計算し、相対表現行列
について、DeePEn は語彙内の各トークンとアンカー トークンの間の埋め込み類似性を計算し、相対表現行列 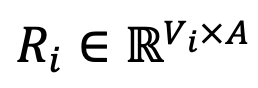 を取得します。最後に、外れ値単語の相対表現劣化問題を克服するために、論文の著者は相対表現行列に対して行正規化を実行し、行列の各行に対してソフトマックス演算を実行して正規化された相対表現行列
を取得します。最後に、外れ値単語の相対表現劣化問題を克服するために、論文の著者は相対表現行列に対して行正規化を実行し、行列の各行に対してソフトマックス演算を実行して正規化された相対表現行列 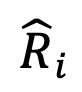 を取得します。
を取得します。  が確率分布
が確率分布 を出力すると、DeePEnは正規化された相対表現行列を使用して
を出力すると、DeePEnは正規化された相対表現行列を使用して を相対表現
を相対表現 に変換します。
に変換します。 
 di mana
di mana  ialah berat kerjasama model
ialah berat kerjasama model 
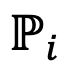 mewakili ruang mutlak model
mewakili ruang mutlak model 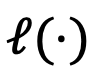 ialah ukuran perwakilan relatif fungsi kehilangan (KL divergence) antara jarak.
ialah ukuran perwakilan relatif fungsi kehilangan (KL divergence) antara jarak.  berkenaan dengan perwakilan mutlak
berkenaan dengan perwakilan mutlak 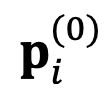 kepada perwakilan mutlak asal model induk dan mengemas kininya:
kepada perwakilan mutlak asal model induk dan mengemas kininya: 
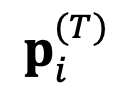 untuk menentukan token yang akan dikeluarkan dalam langkah seterusnya.
untuk menentukan token yang akan dikeluarkan dalam langkah seterusnya. 

