大規模言語モデル (LLM) はさまざまな分野でますます使用されています。ただし、テキスト生成プロセスは高価で時間がかかります。この非効率性は、自己回帰デコードのアルゴリズムに起因します。各単語 (トークン) の生成には前方パスが必要であり、数十億から数千億のパラメータを持つ LLM へのアクセスが必要です。その結果、従来の自己回帰デコードが遅くなります。 最近、ウォータールー大学、カナダベクトル研究所、北京大学、その他の機関が共同で EAGLE をリリースしました。これは、モデル出力テキストの一貫した配布を確保しながら、大規模な言語モデルの推論速度を向上させることを目的としています。この方法は、LLM の 2 番目のトップレベルの特徴ベクトルを外挿し、生成効率を大幅に向上させることができます。 
- 技術レポート: https://sites.google.com/view/eagle-llm
- コード (商用 Apache 2.0 をサポート): https://github.com/SafeAILab/EAGLE
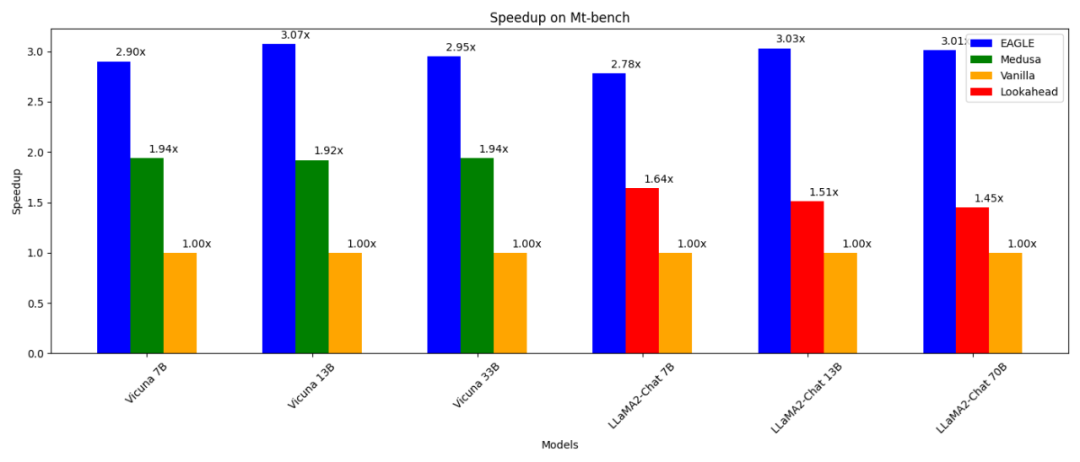
- 通常の自己回帰デコード (13B) よりも 3 倍高速です。
-
Lookahead デコード (13B) よりも 2 倍高速です。 メデューサデコードより(13B) 1.6 倍高速;
-
は、生成されたテキストの配布で通常のデコードと一致していることが証明でき、RTX 3090 でテストできます。
vLLM、DeepSpeed、Mamba、FlashAttendant、量子化、ハードウェア最適化などの他の並列テクノロジと組み合わせて使用できます。
自己回帰デコードを高速化する 1 つの方法は、投機的サンプリングです。この手法では、より小さなドラフト モデルを使用して、標準の自己回帰生成によって次の複数の単語を推測します。元の LLM は、これらの推測された単語を並行して検証します (検証に必要な前方パスは 1 つだけです)。ドラフト モデルが α ワードを正確に予測する場合、元の LLM の 1 回の順方向パスで α+1 ワードを生成できます。
この制限は EAGLE の開発にインスピレーションを与えました。 EAGLE は、元の LLM によって抽出されたコンテキスト特徴 (つまり、モデルの 2 番目の最上層によって出力された特徴ベクトル) を利用します。 EAGLE は次の第一原則に基づいて構築されています: 特徴ベクトル シーケンスは圧縮可能であるため、以前の特徴ベクトルに基づいて後続の特徴ベクトルを予測することが容易になります。 EAGLE は、自動回帰ヘッドと呼ばれる軽量プラグインをトレーニングします。このプラグインは、単語埋め込み層と連携して、現在の特徴シーケンスに基づいて、元のモデルの 2 番目の最上層から次の特徴を予測します。次に、元の LLM の凍結された分類頭部を使用して、次の単語が予測されます。特徴には単語シーケンスよりも多くの情報が含まれるため、特徴を回帰するタスクは単語を予測するタスクよりもはるかに簡単になります。要約すると、EAGLE は小さな自己回帰ヘッドを使用して特徴レベルで外挿し、次に凍結分類ヘッドを利用して予測単語シーケンスを生成します。 Speculative Sampling、Medusa、Lookahead などの同様の作業と同様に、EAGLE はシステム全体のスループットではなく、キューごとの推論のレイテンシーに焦点を当てています。 EAGLE - 大規模言語モデル生成の効率を高める方法
上の図は、EAGLE と標準の投機的サンプリング、Medusa および Lookahead の間の入出力の違いを示しています。 EAGLEのワークフローを以下の図に示します。元の LLM の順方向パスで、EAGLE は 2 番目の最上層から特徴を収集します。自己回帰ヘッドは、これらの特徴と、以前に生成された単語の単語埋め込みを入力として受け取り、次の単語の推測を開始します。その後、凍結分類ヘッド (LM ヘッド) を使用して次の単語の分布を決定し、EAGLE がこの分布からサンプリングできるようにします。 EAGLEはサンプリングを複数回繰り返すことで、下図の右側に示すようなツリー状の生成処理を行います。この例では、EAGLE のトリプル フォワード パスは 10 単語のツリーを「推測」しました。
EAGLE は、軽量の自己回帰ヘッドを使用して、元の LLM の特徴を予測します。生成されたテキスト配布の一貫性を確保するために、EAGLE は予測されたツリー構造を検証します。この検証プロセスは、フォワード パスを使用して完了できます。この予測と検証のサイクルを通じて、EAGLE はテキスト単語を迅速に生成できます。 自己回帰ヘッドをトレーニングするコストは非常にわずかです。 EAGLE は、70,000 弱の対話ラウンドを含む ShareGPT データセットを使用してトレーニングされています。自己回帰ヘッドのトレーニング可能なパラメータの数も非常に少ないです。上の画像の青で示されているように、ほとんどのコンポーネントがフリーズされています。追加で必要なトレーニングは自己回帰ヘッドだけです。これは、0.24B ~ 0.99B のパラメーターを持つ単層の Transformer 構造です。自己回帰ヘッドは、GPU リソースが不十分な場合でもトレーニングできます。たとえば、Vicuna 33B の自己回帰は、8 カードの RTX 3090 サーバーで 24 時間でトレーニングできます。 なぜ単語埋め込みを使用して特徴を予測するのでしょうか? Medusa は、次の単語、次の単語を予測するために 2 番目の最上層の機能のみを使用します... Medusa とは異なり、EAGLE は、現在サンプリングされている単語の埋め込みを自己回帰ヘッド部分への入力として動的に使用して予測を行います。この追加情報は、EAGLE がサンプリング プロセスで避けられないランダム性を処理するのに役立ちます。プロンプト単語が「I」であると仮定して、下の画像の例を考えてみましょう。 LLM は、「I」の後に「am」または「always」が続く確率を示します。 Medusa は、「am」と「always」のどちらがサンプリングされるかを考慮せず、「I」の下にある次の単語の確率を直接予測します。したがって、メデューサの目標は、「私」だけが与えられた場合に、「私は」または「私はいつも」の次の単語を予測することです。サンプリング プロセスのランダム性により、Medusa への同じ入力「I」でも、次の単語の出力「ready」または「begin」が異なる場合があり、その結果、入力と出力の間の一貫したマッピングが欠如します。対照的に、EAGLE への入力にはサンプリングされた結果の単語埋め込みが含まれており、入力と出力の間の一貫したマッピングが保証されます。この区別により、EAGLE はサンプリング プロセスによって確立されたコンテキストを考慮して、後続の単語をより正確に予測できるようになります。
投機的サンプリング、Lookahead、Medusaなどの他の推測検証フレームワークとは異なり、EAGLEは「単語を推測する」段階でツリー状の生成構造を採用しています。より高いデコード効率を実現します。図に示すように、標準の投機的サンプリングと先読みの生成プロセスは線形または連鎖的です。推測段階ではコンテキストを構築できないため、Medusa の方法ではデカルト積を通じてツリーが生成され、隣接するレイヤー間に完全に接続されたグラフが生成されます。このアプローチでは、「I am begin」などの無意味な組み合わせが生じることがよくあります。対照的に、EAGLE はスパースなツリー構造を作成します。この疎なツリー構造は、意味のないシーケンスの形成を防ぎ、より合理的な単語の組み合わせにコンピューティング リソースを集中させます。
標準的な推測的サンプリング方法では、「単語の推測」のプロセス中に分布の一貫性が維持されます。ツリー状の単語推測シナリオに適応するために、EAGLE はこのメソッドをマルチラウンド再帰形式に拡張します。複数ラウンドの投機的サンプリングの疑似コードを以下に示します。ツリー生成プロセス中に、EAGLE はサンプリングされた各単語に対応する確率を記録します。 EAGLE は、複数回の投機的サンプリングを通じて、最終的に生成された各単語の分布が元の LLM の分布と一致していることを保証します。
下图展示了 EAGLE 在 Vicuna 33B 上关于不同任务中的加速效果。涉及大量固定模板的 “编程”(coding)任务显示出最佳的加速性能。
欢迎大家体验 EAGLE,并通过 GitHub issue 反馈建议:https://github.com/SafeAILab/EAGLE/issues以上が大規模モデルの推論効率を損失なく 3 倍向上させた EAGLE をウォータールー大学、北京大学などがリリースしました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



 推測的サンプリングでは、ドラフト モデルのタスクは、現在の単語シーケンスに基づいて次の単語を予測することです。パラメーターの数が大幅に少ないモデルを使用してこのタスクを実行することは非常に困難であり、最適とはいえない結果が得られることがよくあります。さらに、標準的な投機的サンプリング アプローチのドラフト モデルは、元の LLM によって抽出された豊富な意味情報を利用せずに次の単語を独立して予測するため、潜在的に非効率になります。
推測的サンプリングでは、ドラフト モデルのタスクは、現在の単語シーケンスに基づいて次の単語を予測することです。パラメーターの数が大幅に少ないモデルを使用してこのタスクを実行することは非常に困難であり、最適とはいえない結果が得られることがよくあります。さらに、標準的な投機的サンプリング アプローチのドラフト モデルは、元の LLM によって抽出された豊富な意味情報を利用せずに次の単語を独立して予測するため、潜在的に非効率になります。 



