
ホームページ >テクノロジー周辺機器 >AI >北京大学の身体化インテリジェンスチームは、人間のニーズを調整し、ロボットをより効率的にするためのデマンド駆動型ナビゲーションを提案します
北京大学の身体化インテリジェンスチームは、人間のニーズを調整し、ロボットをより効率的にするためのデマンド駆動型ナビゲーションを提案します

- WBOYオリジナル
- 2024-07-16 11:27:391134ブラウズ
ロボットがあなたのニーズを理解し、それに応えるために一生懸命働くことができたら、素晴らしいと思いませんか?
ロボットに手伝ってもらいたい場合は、通常、より正確なコマンドを与える必要がありますが、コマンドの実際の実装は理想的ではない可能性があります。現実の環境を考慮すると、ロボットが特定のアイテムを見つけるように求められたとき、そのアイテムは現在の環境に実際には存在しない可能性があり、いずれにしてもロボットはそれを見つけることができませんが、環境内に関連する別のアイテムが存在する可能性があります。要求されたアイテムは同様の機能を備え、ユーザーのニーズを満たすことができますか?これは、タスクの指示として「要件」を使用する利点です。
最近、北京大学のドンハオ氏のチームは、新しいナビゲーションタスクであるデマンド駆動型ナビゲーション(DDN)を提案し、NeurIPS 2023によって承認されました。このタスクでは、ロボットはユーザーの要求指示に基づいて、ユーザーのニーズを満たすアイテムを見つける必要があります。同時に、Dong Hao 氏のチームは、要求命令に基づいてアイテムの属性特性を学習することも提案しました。これにより、ロボットのアイテム発見の成功率が効果的に向上しました。

論文アドレス: https://arxiv.org/pdf/2309.08138.pdf
-
プロジェクトホームページ: https://sites.google.com/view/demand-driven-navigation/home robotロボットは、「私はおなかがすいている」、「私は喉が渇いている」などの需要コマンドを受け取ります。ロボットは、出会うことができるシーンでアイテムを見つける必要があります。必要。したがって、デマンド駆動型ナビゲーションは本質的にアイテムを見つけるタスクです。これより前にも、ビジュアル オブジェクト ナビゲーション (Visual Object Navigation) という同様のタスクがありました。これら 2 つのタスクの違いは、前者はロボットに「自分のニーズは何ですか」を伝えることであり、後者はロボットに「どのアイテムが欲しいか」を伝えることであるということです。
ニーズを指示として使用するということは、ユーザーのニーズを満たすアイテムを見つける前に、ロボットが指示の内容を推論し、現在のシーン内のアイテムの種類を探索する必要があることを意味します。この観点から見ると、デマンド駆動型ナビゲーションは、視覚的なアイテム ナビゲーションよりもはるかに困難です。難易度は上がっていますが、ロボットが要求の指示に従ってアイテムを見つけることを学習すれば、依然として多くの利点があります。例:
自然言語で記述された要件は、より大きな記述スペースを持ち、より正確で正確な要件を提示できます。
 そのようなロボットを訓練するには、環境が訓練信号を与えることができるように、要求命令とアイテムの間のマッピング関係を確立する必要があります。コストを削減するために、Dong Hao 氏のチームは大規模な言語モデルに基づく「半自動」生成方法を提案しました。まず GPT-3.5 を使用して、シーン内に存在するアイテムによって満たされるニーズを生成し、次にそれらのニーズを手動でフィルタリングします。要件を満たしていないもの。
そのようなロボットを訓練するには、環境が訓練信号を与えることができるように、要求命令とアイテムの間のマッピング関係を確立する必要があります。コストを削減するために、Dong Hao 氏のチームは大規模な言語モデルに基づく「半自動」生成方法を提案しました。まず GPT-3.5 を使用して、シーン内に存在するアイテムによって満たされるニーズを生成し、次にそれらのニーズを手動でフィルタリングします。要件を満たしていないもの。
-
同じニーズを満たすアイテムは似た属性を持っていると考えると、そのアイテムの属性の特徴を学習できれば、ロボットはその属性の特徴を利用してアイテムを見つけることができそうです。例えば、「喉が渇いた」という要件の場合、必須アイテムには「喉の渇きを潤す」という属性が必要であり、「ジュース」と「お茶」は両方ともこの属性を持っています。ここで注意する必要があるのは、アイテムはさまざまなニーズの下でさまざまな属性を示す可能性があるということです。たとえば、「水」は「衣類を洗う」という要件の下で「衣類を洗う」という属性と、「衣類を洗う」という属性を示す両方の属性を示す可能性があります。 「喉の渇きを癒す」(「喉が渇いている」という要件の下で)。
属性学習段階
それでは、「喉の渇きを癒す」と「衣服をきれいにする」というニーズをモデルに理解させるにはどうすればよいでしょうか?特定のニーズの下でアイテムによって表示される属性に注目することは、比較的安定した常識です。近年、大規模言語モデル (LLM) の台頭により、LLM が示す人間社会の常識の理解には驚くべきものがあります。そこで、北京大学ドンハオ氏のチームは、LLM からこの常識を学ぶことにしました。彼らはまず、LLM に多くの要求命令 (図では言語グラウンディング要求、LGD と呼ばれます) を生成するように依頼し、次に LLM にこれらの要求命令 (図では言語グラウンディング オブジェクト、LGO と呼ばれます) を満たすことができるアイテムはどれかを尋ねました。
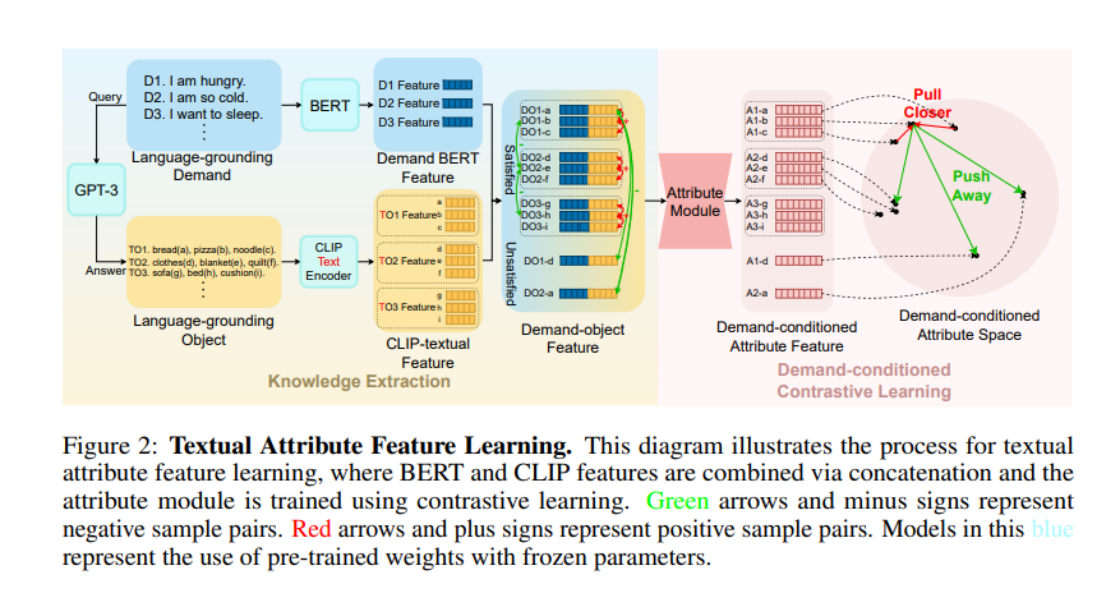
ここで、接頭語 Language-grounding は、これらの要求/オブジェクトが LLM から取得でき、特定のシナリオに依存しないことを強調していることに注意してください。下の図の World-grounding は、これらの要求/オブジェクトがオブジェクトであることを強調しています。特定の環境 (ProcThor、レプリカ、その他のシーン データ セットなど) と緊密に統合されています。
次に、LGD の下で LGO のプロパティを取得するために、著者らは BERT を使用して LGD をエンコードし、CLIP-Text-Encoder を使用して LGO をエンコードし、それらを結合して需要オブジェクトの特徴を取得しました。最初にアイテムの属性を導入したときに「類似性」があることに注目し、著者らはこの類似性を利用して「陽性サンプルと陰性サンプル」を定義し、次に対照学習を使用して「アイテム属性」をトレーニングしました。具体的には、結合された 2 つの需要オブジェクト フィーチャについて、2 つのフィーチャに対応するアイテムが同じ要件を満たすことができる場合、2 つのフィーチャは互いの正のサンプルになります (たとえば、図内のアイテム a とアイテム b は両方とも要件 D1 を満たすことができる場合、DO1-a と DO1-b は互いに正のサンプルになります)、その他のスプライシングは互いに負のサンプルになります。著者は、需要オブジェクトの特徴を TransformerEncoder アーキテクチャの属性モジュールに入力した後、InfoNCE Loss でトレーニングしました。
ナビゲーション戦略学習フェーズ
比較学習を通じて、属性モジュールは LLM によって提供される常識を学習しました。ナビゲーション戦略学習フェーズでは、属性モジュールのパラメーターが直接インポートされ、A* アルゴリズムがインポートされます。模倣学習を使用して学習しました。特定のタイム ステップで、作成者は DETR モデルを使用して現在の視野内の項目をセグメント化し、World-grounding Object を取得します。これは CLIP-Visual-Endocer によってエンコードされます。他のプロセスは属性学習段階と同様です。最後に、必要な命令の BERT 特徴、グローバル イメージ特徴、および属性特徴が結合され、Transformer モデルに入力され、最後にアクションが出力されます。

著者が属性学習段階では CLIP-Text-Encoder を使用し、ナビゲーション ポリシー学習段階では CLIP-Visual-Encoder を使用したことは注目に値します。ここでは、CLIP モデルの強力なビジュアルおよびテキスト配置機能を巧みに使用して、LLM から学習したテキストの常識を各タイム ステップのビジョンに転送します。
実験結果
この実験は、AI2Thor シミュレーターと ProcThor データセットで行われました。実験結果は、この方法がさまざまなビジュアル アイテム ナビゲーション アルゴリズムや大規模な言語モデルでサポートされているアルゴリズムの以前のバージョンよりも大幅に優れていることを示しています。

VTN は、プリセット項目に対してのみナビゲーション タスクを実行できるクローズドボキャブラリー ナビゲーション アルゴリズムです。著者らはアルゴリズムのいくつかのバリエーションを作成しましたが、必要な命令の BERT 機能が入力として使用されるか、命令の GPT 解析結果が入力として使用されるかにかかわらず、アルゴリズムの結果はあまり理想的ではありません。オープン語彙ナビゲーション アルゴリズムである ZSON に切り替えると、デマンド命令と画像の間の CLIP の位置合わせ効果が不十分なため、ZSON のいくつかのバリアントはデマンド ナビゲーション タスクを適切に完了できません。ヒューリスティック検索 + LLM に基づく一部のアルゴリズムは、Procthor データセットのシーン領域が大きいため探索効率が低く、成功率はあまり高くありません。 GPT-3-Prompt や MiniGPT-4 などの純粋な LLM アルゴリズムは、シーン内の目に見えない場所に対する推論機能が不十分であり、その結果、要件を満たすアイテムを効率的に検出できなくなります。
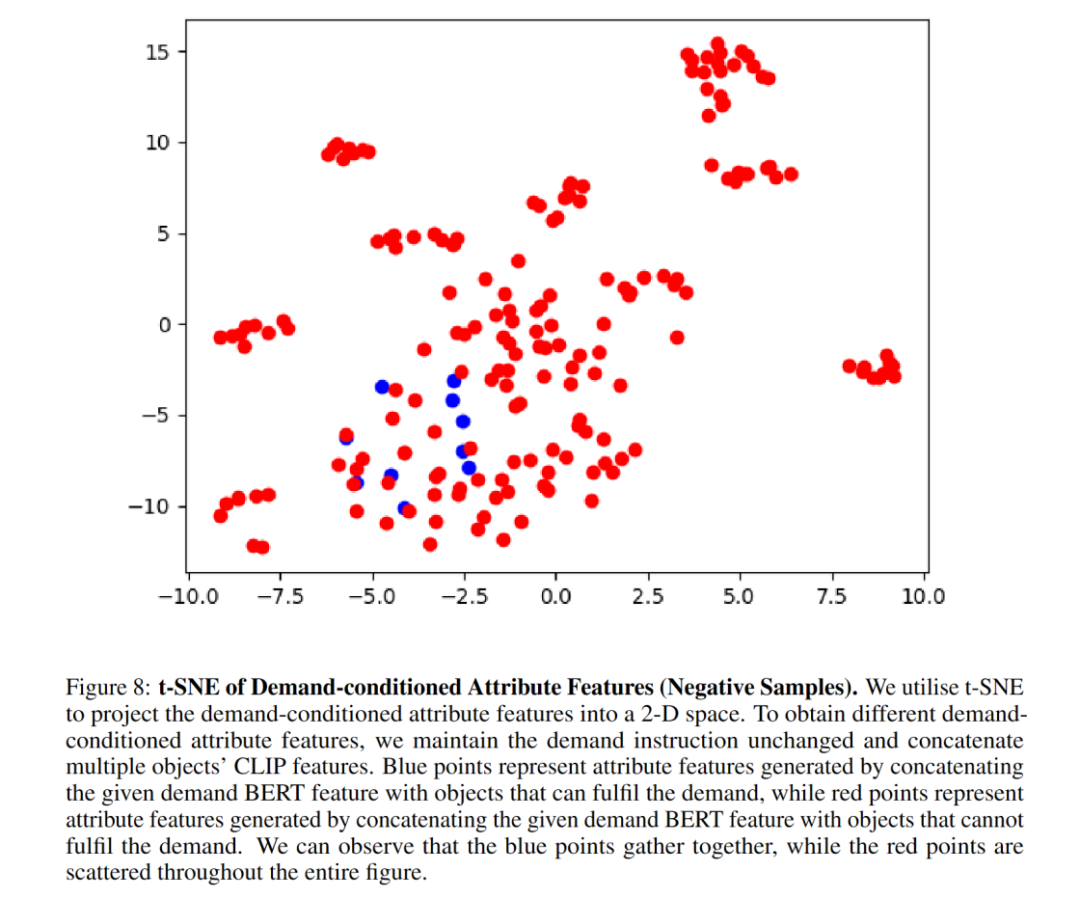
アブレーション実験により、属性モジュールがナビゲーションの成功率を大幅に向上させることが示されました。著者らは、t-SNE グラフが、属性モジュールが要求条件付き対比学習を通じてアイテムの属性特徴を首尾よく学習していることをよく示していることを示しています。属性モジュール アーキテクチャを MLP に置き換えた後、パフォーマンスが低下しました。これは、TransformerEncoder アーキテクチャが属性特性のキャプチャにより適していることを示しています。 BERT は必要な命令の特徴を適切に抽出できるため、目に見えない命令の一般化が向上します。

ここにいくつかの視覚化があります:




この研究の責任著者である Dong Hao 博士は、現在、北京のフロンティア コンピューティング研究センターの助教授です。大学、博士課程の指導教官、リベラルアーツの青少年学者および知的学者である彼は、2019 年に北京大学ハイパープレーン研究所を設立し、率いています。NeurIPS、ICLR、CVPR、ICCV などの主要な国際会議/ジャーナルに 40 以上の論文を発表しています。 、ECCV など。Google Scholar 4,700 回以上引用されており、ACM MM Best Open Source Software Award と OpenI Outstanding Project Award を受賞しています。また、NeurIPS、CVPR、AAAI、ICRA などの主要な国際会議のフィールドチェアマンおよび副編集委員を何度も務め、多くの国家および地方プロジェクトに携わり、科学技術省の新世代会議の議長を務めてきました。人工知能 2030 の主要プロジェクト。

この論文の筆頭著者であるWang Honzhenは現在、北京大学コンピューターサイエンス学部の博士課程2年生です。彼の研究対象は、ロボット工学、コンピューター ビジョン、心理学に焦点を当てており、人間の行動、認知、動機の側面から始めて、人間とロボットの関係を調整したいと考えています。

参考リンク:
[1] https://zsdonghao.github.io/
[2] https://whcpumpkin.github.io/
以上が北京大学の身体化インテリジェンスチームは、人間のニーズを調整し、ロボットをより効率的にするためのデマンド駆動型ナビゲーションを提案しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。