
秦オペラの冒頭のセリフで私たちは黄土高原に連れて行かれました。自分の目で見ていなかったら、多くの視聴者は生きているうちに兵馬俑とジェムが同じステージで「陸軍行進曲」を披露するのを見ることになるとは想像もしていなかったかもしれない。 「青海省の長い雲と暗い雪を頂いた山々、遠くに玉門峠を望む寂しい都市。」 古代の旋律は音楽では変化しましたが、その音は今も感動的です: 
このパフォーマンスの背後にある「AI復活召喚技術」は、Alibaba Tongyi LabよりEMOと呼ばれています。写真と音声だけで、EMO は静止画を本物のような歌とパフォーマンスのビデオに変換し、音声の浮き沈みや浮き沈みを正確にキャプチャーできます。 やはりEMO技術に基づいたCCTVの「2024年中国AIフェスティバル」では、北宋時代の作家蘇軾が「復活」し、同じステージで李雨剛とともに「水条格頭」という曲を歌った。 「AI Su Shi」の動きは、まるで時空を旅したかのようにシンプルかつ自然です: 
初の国家レベル技術であるEMOなどのAI分野の最先端技術からインスピレーションを得ています人工知能を核とした饗宴「2024中国AIフェスティバル」が盛大に開催 オープニングでは、国内の最先端AIテクノロジーの力が「メディア+テクノロジー+アート」の統合の形でショーの前にすべての観客に届けられます。  EMOが「輪から外れ」たのはこれが初めてではありません。かつてソーシャルメディアで爆発的に流行した「Gao Qiqiang Integrated Luo Xiang Pufa」もEMOによって作成されました:
EMOが「輪から外れ」たのはこれが初めてではありません。かつてソーシャルメディアで爆発的に流行した「Gao Qiqiang Integrated Luo Xiang Pufa」もEMOによって作成されました: 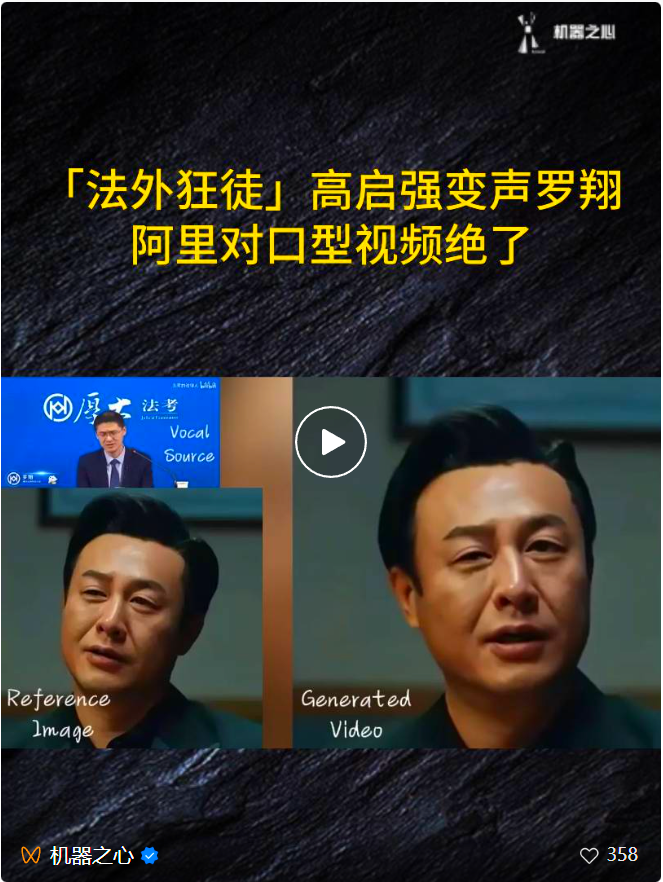 Tongyi APPにログインした後、プレーヤーのさまざまな想像力豊かな試みの助けを借りて、EMOは今日非常に人気になりました。 。まだ試したことのない友達は、このアプリをダウンロードし、「チャンネル」に入り、「全国ステージ」を選択するとスムーズに体験できます。
Tongyi APPにログインした後、プレーヤーのさまざまな想像力豊かな試みの助けを借りて、EMOは今日非常に人気になりました。 。まだ試したことのない友達は、このアプリをダウンロードし、「チャンネル」に入り、「全国ステージ」を選択するとスムーズに体験できます。 
実際、今年2月にはTongyi LaboratoryはEMO(Emote Portrait Alive)関連の論文を発表しました。この論文は最初に発表されたときに絶賛され、「EMO は革新的な研究だ。」
と賞賛する人もいます。
- 論文アドレス: https://arxiv.org/pdf/2402.17485
- プロジェクトホームページ: https://humanaigc.github.io/emote-portrait-alive/
なぜ機能するのかこれほど高い評価を受けるには?これも、ビデオ生成技術の開発状況と、その根底にある EMO の技術革新から始まります。 それでは輪から外れているのに、なぜ EMO なのでしょうか? ここ数年、画像生成における AI の成功は誰の目にも明らかです。現在、AI 分野における研究のホットスポットは、ビデオ生成というより困難なタスクを克服することです。 EMO は、最も困難なタスクの 1 つである オーディオ駆動のキャラクター ビデオ生成に直面しています。 一般的な Vincent ビデオや Tusheng ビデオのゲームプレイとは異なり、オーディオ主導のキャラクター ビデオ生成は、オーディオ モダリティからビデオ モダリティに直接横断するプロセスです。このタイプのビデオの生成には、頭の動き、視線、まばたき、唇の動きなどの複数の要素が含まれることが多く、ビデオ コンテンツの一貫性と滑らかさを維持する必要があります。 これまでの方法では、ほとんどのモデルは最初に 3D モデリングまたは顔、頭、体の一部の顔のキー ポイント マーキングを実行し、これを中間表現として使用して最終ビデオを生成します。ただし、中間表現を使用する方法では、音声の情報が圧縮されすぎて、最終的に生成されるビデオの感情表現に影響を与える可能性があります。 Tongyi Laboratoryの応用ビジョンチームの責任者であるBo Liefeng氏は、EMOの重要な革新である「弱い制御設計」が上記の問題をうまく解決し、ビデオ生成のコストを削減するだけでなく、ビデオ生成のコストを大幅に改善すると述べました。ビデオ生成の品質。 
「弱い制御」は 2 つの側面に反映されています。まず、EMO はモデリングを必要とせず、音声から情報を直接抽出して表情のダイナミクスとリップシンクのビデオを生成するため、複雑な前処理の必要性がなくなります。 . 自然でスムーズで表現力豊かなポートレートビデオをエンドツーエンドで作成します。第二に、EMO は生成される表情や体の動きをあまり「制御」しません。自然で滑らかな最終生成結果は、高品質のデータから学習してトレーニングされたモデル自体の汎化能力によるものです。 兵馬俑と馬とジェムジェムを同じフレームに収めて「軍隊行進曲」を歌うと、歌で伝えられる感情(興奮など)が人に感じさせずによく表情に現れています。不服従: 
弱い制御の概念に基づいて、研究チームは EMO モデル用に大規模で多様なオーディオおよびビデオ データ セットを構築し、合計 250 時間以上の録音と 1 億 5,000 万枚以上の画像 をカバーしました。スピーチ、映画などのさまざまなコンテンツ中国語や英語を含む多言語でのテレビクリップや歌唱パフォーマンスなど、豊富なビデオにより、トレーニング教材は人間の幅広い表現や発声スタイルを確実に捉えることができます。 学術コミュニティには、データセットに対する最良の可逆圧縮は、データセット外のデータに対する最良の一般化であるという見解があります。効率的な圧縮を実現できるアルゴリズムは、データの深いパターンを明らかにすることが多く、これはインテリジェンスの重要な現れでもあります。 したがって、チームは、データの圧縮または処理のプロセス中に元の情報の豊富な詳細とダイナミック レンジが可能な限り維持されるように、トレーニング プロセス中に 忠実度の高いデータ エンコード アルゴリズム を設計しました。 。 EMOトレーニング特有の、音声情報が揃って初めてキャラクターの感情をうまく表現することができます。 
Tongyi Lab はどのようにして世界初のエシュロンになったのでしょうか? 今年 2 月初旬、Sora のリリースによりビデオ生成トラックに火がつき、DiT (Diffusion Transformer) を含む、その背後にある多くのテクノロジーが注目を集めました。 拡散モデルの U-Net は、ノイズから信号を段階的に回復するプロセスをシミュレートできることがわかっています。理論的には、あらゆる複雑なデータ分布を近似でき、敵対的生成ネットワーク (GAN) よりも優れており、変数の点でも優れています。オートエンコーダ (VAE) は、より自然なテクスチャとより正確な詳細を備えた現実世界の画像を生成します。ただし、DiT の論文では、U-Net 誘導バイアスは拡散モデルのパフォーマンスに不可欠ではなく、標準設計 (Transformer など) で簡単に置き換えることができることが示されています。これは、Transformer アーキテクチャに基づく新しい拡散モデル DiT です。論文で提案されている。 最も重要なことは、DiT をコアとする Sora がビデオ生成モデルにスケーリング則がまだ存在することを検証しており、研究者はより多くのパラメーターとデータを追加することでモデルのサイズを拡張してより良い結果を達成できることです。 実際のビデオ生成における DiT モデルの成功により、AI コミュニティがこの手法の可能性を認識できるようになり、ビデオ生成の分野が古典的な U-Net アーキテクチャから U-Net アーキテクチャのパラダイムへの移行を促しました。トランスベースの拡散バックボーン アーキテクチャ。 Transformer のアテンション メカニズムに基づく時間予測と大規模な高品質ビデオ データが、この変革を推進する重要な力となります。 しかし、現在のビデオ生成分野を見ると、「大規模に統合された」アーキテクチャはまだ存在していません。 EMO は DiT のようなアーキテクチャに基づいていません。つまり、従来の U-Net を置き換えるために Transformer を使用しません。また、実際の物理世界を非常にうまくシミュレートでき、これが研究全体に影響を与えました。分野。 将来、ビデオ生成の分野ではどのような技術的なルートが現れるでしょうか?理論研究者も実践者も、「比較的オープンな期待」を維持できます。 Bo Liefeng氏は、本質的に、現在の言語モデルと画像/ビデオ生成モデルは統計的機械学習の枠組みを超えていないと述べました。スケーリング法にも独自の制限があります。各モデルは、強い関係と中程度の関係の生成を比較的正確に把握していますが、弱い関係の学習はまだ不十分です。研究者が十分な高品質のデータを提供し続けられない場合、モデルの機能を質的に向上させることは困難になります。 見方を変えると、映像生成の分野で「国の半分を占める」統一アーキテクチャがあったとしても、それが絶対的な優位性を持っているわけではない。自然言語の分野と同様に、常に C の地位を堅持してきた Transformer も、Mamba に追い越されることになるでしょう。 特にビデオ生成の分野では、各技術ルートに独自のアプリケーション シナリオがあります。例えば、キーポイントドライバーやビデオドライバーは表情の移り変わりのシーンに適しており、オーディオドライバーはキャラクターが喋ったり歌ったりするシーンに適しています。条件付き制御の程度という点では、弱い制御方法は創造的なタスクに非常に適していますが、多くの専門的で特殊なタスクは強い制御方法の恩恵を受けることができます。 Tongyi Laboratoryは、中国で最も早くビデオ生成技術を開発した機関の1つであり、現在、特にキャラクタービデオの生成など、多方向の研究開発を蓄積しています。は、Animate Anybody、キャラクター アクション ビデオ生成フレームワーク、Outfit Anybody、キャラクター ビデオ役割置換フレームワーク Motionshop、およびキャラクターの歌唱とパフォーマンス ビデオ生成フレームワーク Emote Portrait Alive を含む、People完全な研究マトリックスを形成しました。  :その他のプロジェクトについては、https://github.com/humanaigc、EMO以前、Animateなど、かつては誰もがソーシャルメディアと友人の輪を支配していました。このモデルは、キャラクターの動きのビデオを生成する際のキャラクターの外観の短期的な連続性と長期的な一貫性を維持するという問題を解決しました。その後、Tongyi アプリに「National Dance King」機能が開始され、全国的なダンスの波が始まりました。クライマックス。
:その他のプロジェクトについては、https://github.com/humanaigc、EMO以前、Animateなど、かつては誰もがソーシャルメディアと友人の輪を支配していました。このモデルは、キャラクターの動きのビデオを生成する際のキャラクターの外観の短期的な連続性と長期的な一貫性を維持するという問題を解決しました。その後、Tongyi アプリに「National Dance King」機能が開始され、全国的なダンスの波が始まりました。クライマックス。
 テクノロジーから現実世界へ 過去 2 年間、言語モデルは対話、理解、要約、推論などにおいて強力なテキスト機能を実証し、画像生成モデルは強力なテキスト機能を実証してきました。ナチュラルジェネレーション、エンターテイメント性とアート性を兼ね備えた両代表曲は数々のヒット作を生み出してきた。これらのモデルの成功は、少なくとも 1 つのことを教えてくれます。
テクノロジーから現実世界へ 過去 2 年間、言語モデルは対話、理解、要約、推論などにおいて強力なテキスト機能を実証し、画像生成モデルは強力なテキスト機能を実証してきました。ナチュラルジェネレーション、エンターテイメント性とアート性を兼ね備えた両代表曲は数々のヒット作を生み出してきた。これらのモデルの成功は、少なくとも 1 つのことを教えてくれます。
この時代に影響力を持ちたい技術チームは、「基本モデル」と「スーパー アプリケーション」の二本足で歩くことを学ぶ必要があります。 現在、動画コンテンツは爆発的な成長傾向を示しており、誰にとっても「使える」「実用的」なAI動画生成プラットフォームの登場が期待されています。
EMO はこの状況を打破するための重要な技術的進歩となる可能性があり、Tongyi アプリは技術実装のための広範なプラットフォームを提供します。 ビデオ生成テクノロジーにおける次の課題は、プロレベルのコンテンツをキャプチャする方法です。
テクノロジー企業は、AI テクノロジーを、短編ビデオブロガー、映画やテレビのプロデューサー、広告やゲームのクリエイティブに役立つ真の生産性ツールに変えたいと考えています。これが、ビデオ生成アプリケーションが単に「一般的なコンテンツ」のレベルにとどまることができない理由です。
現在のほとんどのビデオ生成アプリケーションを見てみると、そのほとんどは 3 ~ 5 秒のビデオ生成モデルに基づいており、アプリケーションとエクスペリエンスに明らかな制限があります。
ただし、EMO テクノロジーは音声の長さに非常に耐性があり、生成されたコンテンツの品質はスタジオの標準を満たすことができます。たとえば、CCTV で放送されたこの「兵馬俑と馬の歌とパフォーマンス」では、兵馬俑の 4 分間のパフォーマンス ビデオのうち、ポストプロダクションでの手動の「微調整」は 1 秒も必要ありませんでした。 さて、EMOに代表されるキャラクタービデオ生成技術は、最も「プロレベルの生成レベル」に近い実装方向の一つであると思われます。 Wensheng ビデオ テクノロジのユーザー プロンプトには多くの不確実性があるのに比べ、EMO テクノロジは、キャラクター ビデオ作成におけるコンテンツの一貫性と一貫性という中核的な要件と高度に一致しており、非常に潜在的なアプリケーション領域であることを示しています。
EMOが「サークルから出てきた」理由は、研究開発チームの技術力だけではなく、より重要なことに、ビデオ生成技術の実装の加速です。
「一人当たりのプロのクリエイター」の時代はそう遠くないかもしれません。
以上がCCTVは国内のAI復活召喚技術を賞賛し、兵馬俑は実際に宝石おじさんとラップしましたか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

