
ホームページ >テクノロジー周辺機器 >AI >オープンソースの3D医療用大型モデルSATは、497個のオルガノイドをサポートし、72nnU-Netsを超える性能を持っています。上海交通大学のチームによってリリースされました。
オープンソースの3D医療用大型モデルSATは、497個のオルガノイドをサポートし、72nnU-Netsを超える性能を持っています。上海交通大学のチームによってリリースされました。

- 王林オリジナル
- 2024-07-12 10:52:01615ブラウズ

著者 | 上海交通大学、上海人工知能研究所
編集者 | ScienceAI
最近、上海交通大学と上海人工知能研究所の共同チームは、大規模な 3D 医療画像セグメンテーション モデル SAT (Segment Anything inテキストプロンプトによって駆動される放射線スキャン)、テキストプロンプトに基づいた 3D 医療画像(CT、MR、PET)上で、人体の 497 種類の臓器/病変の普遍的なセグメンテーションを実現します。すべてのデータ、コード、モデルはオープンソースです。

ペーパーリンク:https://arxiv.org/abs/2312.17183
コードリンク:https://github.com/zhaoziheng/SAT
データリンク:https://github .com/zhaoziheng/SAT-DS/
研究の背景
医療画像のセグメンテーションは、診断、手術計画、疾患のモニタリングなどの一連の臨床タスクにおいて重要な役割を果たします。しかし、従来の研究では、特定のセグメンテーション タスクごとに「専用」モデルをトレーニングするため、各「専用」モデルの適用範囲が比較的限られており、広範囲の医療セグメンテーション ニーズを効率的かつ便利に満たすことができません。
同時に、最近、大規模な言語モデルが医療分野で大きな成功を収めており、一般的な医療用人工知能の開発をさらに促進するには、言語と位置決め機能を接続できる医療セグメンテーションツールを構築する必要があります。
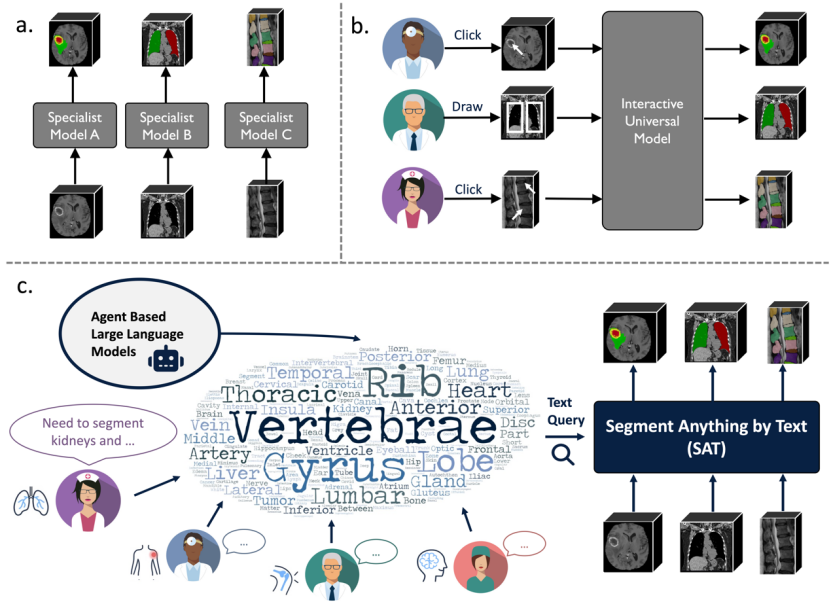
これらの課題を克服するために、上海交通大学と上海人工知能研究所の研究者は、知識強化とテキストプロンプトを使用した、テキストによって駆動される SAT (Segment Anything in radiology scans) と呼ばれる 3D 医療画像の最初の一般的なセグメンテーション モデルを提案しました。
1. この研究は、解剖学的用語を正確にエンコードし、テキスト プロンプトを実現するために、人体解剖学の知識をテキスト エンコーダーに注入することを初めて検討しました。 。 2. この研究では、6K を超える人体解剖学の概念を含む初のマルチモーダルな医学知識グラフが構築されました。同時に、SAT-DS と呼ばれる最大の 3D 医療画像セグメンテーション データ セットが構築されました。これには、人体をカバーする 72 の公開データ セット、CT、MR、PET モダリティからの 22,000 以上の画像、および 302,000 以上のセグメンテーション アノテーションがまとめられています。 8 つの主要な部分に分かれた 497 のセグメンテーション ターゲット。 3. この研究では、SAT-DS に基づいて、SAT-Pro (パラメーター 447M) と SAT-Nano (パラメーター 110M) の 2 つの異なるサイズのモデルをトレーニングし、複数の角度から SAT の値を検証する実験を設計しました。パフォーマンスは 72 nnU-Nets エキスパート モデルと同等であり (パラメーターはデータ セットごとに個別に調整および最適化され、合計約 22 億個のパラメーター)、ドメイン外の SAT を使用できるより強力な汎化能力を示します。大規模なデータで事前トレーニングされた基本的なセグメンテーション モデルは、下流の微調整を通じて特定のタスクに転送されると、nnU-Nets よりも優れたパフォーマンスを示すことができます。さらに、ボックス プロンプトに基づく MedSAM と比較して、SAT はより正確で優れたパフォーマンスを実現できます。テキストプロンプトに基づく正確なパフォーマンス、より効率的なセグメンテーション、最後に、研究チームは、ドメイン外の臨床データに関して、SAT が大規模な言語モデルのプロキシツールとして使用できることを実証し、後者にタスクのローカライズとセグメント化の機能を直接提供しました。レポート作成など。 以下では、データ、モデル、実験結果の3つの側面から元記事の詳細を紹介します。データ構築
マルチモーダルナレッジグラフ:解剖学的用語の正確なエンコードを達成するために、研究チームはまず、6K以上の人体解剖学の概念を含むマルチモーダルナレッジグラフを収集しました。その内容は3つの概念から来ています。出典:
1. Unified Medical Language System (UMLS) は、米国国立医学図書館によって構築された生物医学辞書です。研究チームは、約 23 万の生物医学の概念と定義、および 100 万以上の相互関係をカバーするナレッジ グラフを抽出しました。 2. インターネット上の権威ある解剖学の知識。研究チームは、6,502 の人体解剖学の概念をスクリーニングし、検索機能が強化された大規模言語モデルを利用してインターネットから関連情報を検索し、6,000 以上の概念と定義、および解剖学的構造間の 38,000 以上の関係をカバーする知識マップを取得しました。 3. パブリックセグメンテーションデータセット。研究チームは、公開されている大規模な 3D 医用画像セグメンテーション データセットを収集し、解剖学的概念 (カテゴリ ラベル) を通じてセグメント化された領域を上記のテキスト知識ベースの知識と結び付け、視覚的な知識の比較を提供しました。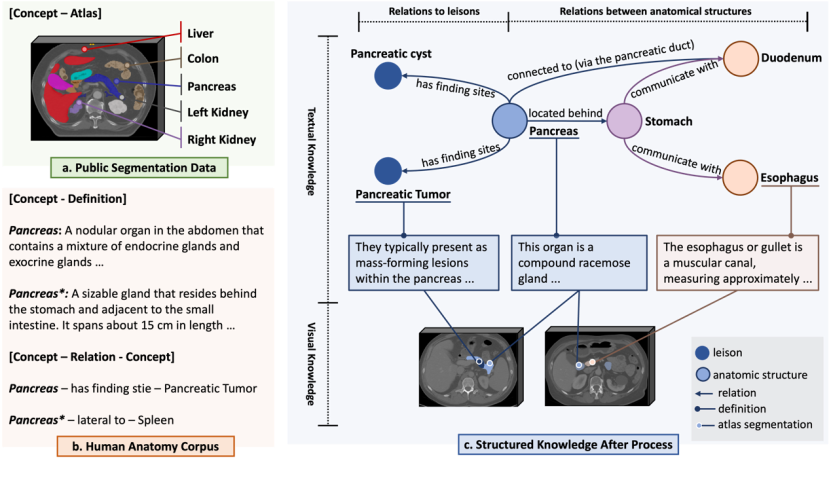
SAT-DS: ユニバーサル セグメンテーション モデルをトレーニングするために、研究チームは、この分野で最大の 3D 医用画像セグメンテーション データ コレクションである SAT-DS を構築しました。特に、CT、MR、PET の 3 つのモダリティからの合計 22,186 の 3D 画像、302,033 のセグメンテーション アノテーション、および人体の 8 つの主要領域をカバーする 497 のセグメンテーションを含む、72 の多様なパブリック セグメンテーション データ セットが収集および整理されました。 (解剖学的構造または病変)。
異種データセット間の差異を最小限に抑えるために、研究チームは異なるデータセット間の方向、ボクセル間隔、グレー値、その他の画像属性を標準化し、統一された解剖学的用語システムセグメンテーションカテゴリを使用して異なるデータセットに名前を付けました。

図 3: SAT-DS は、大規模かつ多様な 3D 医療画像セグメンテーション データ コレクションであり、人体の 8 つの主要領域の合計 497 のセグメンテーション カテゴリをカバーしています。
モデル アーキテクチャ
知識の注入: 解剖学的用語を正確にエンコードできるプロンプト エンコーダーを構築するために、研究チームはまず、対照学習を使用してマルチモーダル解剖学の知識をテキスト エンコーダーに注入しました。
下の図aに示すように、解剖学的概念を使用してマルチモーダル知識をペアに接続し、次にビジュアルエンコーダーとテキストエンコーダーを使用して視覚知識とテキスト知識をそれぞれエンコードし、特徴をコントラストを通じて学習します。空間内のテキスト知識を使用して解剖学的構造の特徴を理解し、解剖学的構造間の関係を構築することで、解剖学的概念のより適切なエンコードを学び、視覚セグメンテーション モデルのトレーニングをガイドする手がかりとして機能します。
テキストプロンプトに基づくユニバーサルセグメンテーション:研究チームはさらに、以下の図bに示すように、テキストエンコーダー、ビジュアルエンコーダー、ビジュアルデコーダー、プロンプトデコーダーを含むテキストプロンプトに基づくユニバーサルセグメンテーションモデルフレームワークを設計しました。
その中で、同じ解剖学的構造でも異なる画像では違いがあることを考慮して、キューデコーダー(クエリデコーダー)は、ビジュアルエンコーダーが出力する画像特徴を使用して、解剖学的概念特徴、つまりセグメンテーションキューを強化します。最後に、セグメンテーション ヒントとビジュアル デコーダによって出力されたピクセル レベルの特徴の間の内積が計算され、セグメンテーション予測結果が得られます。

モデル評価
この研究では、SAT を 2 つの代表的な方法、つまり「特殊な」モデル nnU-Nets と対話型の一般セグメンテーション モデル MedSAM と比較します。評価には、ドメイン内データ セット テスト (包括的なセグメンテーション パフォーマンス) とゼロショット ドメイン外データ セット テスト (センター間のデータ移行機能) の 2 つの側面が含まれます。評価結果は、データ セット、データ セット、データ セットの 3 つのレベルから統合されます。カテゴリと人体の領域:
-
カテゴリ: 異なるデータセット間の同じカテゴリのセグメンテーション結果が要約され、平均化されます。
領域: カテゴリの結果に基づいて、同じ人体解剖学的領域内のカテゴリの結果が次のようになります。
データセット: 従来のセグメンテーション モデルの評価方法では、同じデータ セット内のセグメンテーション結果が平均化されます。
専用モデル nnU-Nets との比較実験。 nnU-Nets のパフォーマンスを調べるため、研究では個別のデータ分析を実行しました。nnU-Nets はセット上でトレーニングされ、SAT と比較されました。
ドメイン内テストでは、すべて 72。 SAT-DS のデータセットはテストと比較に使用されます。 SAT の場合、72 のトレーニング セットの合計がトレーニングに使用され、72 のテスト セットでテストされます。nnU-Net の場合、それぞれのテスト セットでの 72 の nnU-Net の結果が全体として要約されます。 2. ドメイン外テストでは、72 個のデータセットがさらに分割され、49 個のデータセット (SAT-DS-Nano と名付けられました) のトレーニングセットが SAT-Nano のトレーニングとゼロショットテストに使用されました。 nnU-Net の場合、49 個の nnU-Net を使用して 10 個のドメイン外テスト セットでテストが行われ、結果が要約されます。 表 1: SAT-Pro、SAT-Nano、SAT-Pro-Ft、および nnU-Nets のドメイン内テストの比較。結果は領域または病変の単位で統合されます。 H&N は頭と首、UL は上肢、LL は下肢を表します。複数の領域に出現するカテゴリーをWhole Body (WB)に分類し、Allは497カテゴリーの平均結果を表します。 ドメイン内テストの結果:
ドメイン内テストの結果: 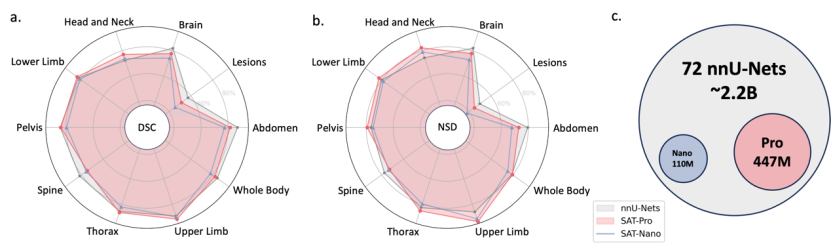
微調整移行テストの結果: この研究では、SAT-Pro-Ft と呼ばれる、個別に微調整した後、各データセットで SAT-Pro をさらにテストしました。表 1 からわかるように、SAT-Pro-Ft は、SAT-Pro と比較してすべての領域でパフォーマンスが大幅に向上しており、全体的なパフォーマンスで nnU-Nets を上回っています。
ドメイン外テスト結果: 表 2 に示すように、SAT-Nano は 10 のデータセットの 20 指標のうち 19 で nnU-Nets を上回り、全体的に強力な移行機能を示しています。
表 2: SAT-Nano、nnU-Nets、および MedSAM 間のドメイン外テストの比較 結果はデータセット単位で表示されます。

インタラクティブセグメンテーションモデルMedSAMとの比較実験
この研究では、テストとSAT比較にMedSAMのパブリックチェックポイントを直接使用します。具体的な設定は次のとおりです:
1.データ 比較のために、MedSAM トレーニングで使用された 32 のデータセットをさらにスクリーニングしました。
2. ドメイン外テストでは、MedSAM トレーニングで使用されていない 5 つのデータセットが比較のためにスクリーニングされました。
MedSAM の場合、2 つの異なる Box プロンプトを検討します。グラウンド トゥルース セグメンテーションを含む最小の長方形 (Oracle Box) を使用し、MedSAM (Tight) として記録され、Oracle Box に基づいてランダム オフセットを追加し、MedSAM (Loose) として記録されます。同時に、Oracle Box の効果を予測として直接テストします。 SAT の場合、nnU-Nets 比較実験のモデルは、再トレーニングせずにこれらのデータ セットをテストするために直接使用されます。
ドメイン内テスト結果: 表 3 に示すように、SAT-Pro はほぼすべての領域で MedSAM より優れたパフォーマンスを示し、SAT-Pro と SAT-Nano の全体的なパフォーマンスは MedSAM よりも優れています。 SAT-Pro は病変に対して MedSAM ほど優れたパフォーマンスを発揮しませんが、Oracle Box 自体は予測として病変に対して十分なパフォーマンスを発揮し、DSC では MedSAM を上回っています。これは、病変のセグメント化における MedSAM の優れたパフォーマンスは、Box によって促された強力な事前情報に由来する可能性が高いことを示しています。
表 3: SAT-Pro、SAT-Nano、および MedSAM のドメイン内テストの比較。結果は領域または病変の単位で統合されます。

定性的比較: 図 6 は、SAT と MedSAM をさらに比較するために、視覚表示用のドメイン内テストの結果から 2 つの典型的な例を選択しています。図 6 に示すように、心筋層のセグメンテーションでは、Box プロンプトは心筋層と心筋層に包まれた心室を区別するのが難しいため、MedSAM も誤って 2 つを一緒にセグメント化しました。これは、Box プロンプトが類似していることを示しています。複雑な空間関係は曖昧になりやすく、不正確なセグメンテーションにつながります。
対照的に、テキスト プロンプト (解剖学的構造の名前を直接入力) に基づく SAT は、心筋と心室を正確に区別できます。さらに、図 6 に示す腸腫瘍のセグメンテーションでわかるように、Oracle Box はすでに病変ターゲットの良好な予測結果を示していますが、MedSAM のセグメンテーション結果は、取得された Box プロンプトよりも優れているとは言えません。
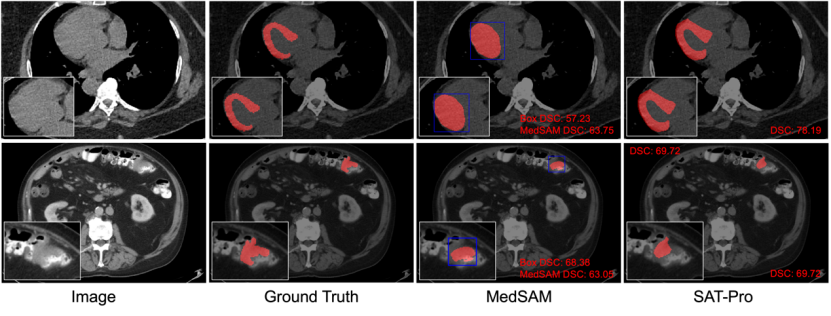
図 6: SAT-Pro と MedSAM (タイト) の定性的比較。このうち、MedSAM は Oracle Box をプロンプトとして使用しており、Box は青色でマークされています。最初の行は心筋のセグメンテーションの例を示し、2 番目の行は腸腫瘍のセグメンテーションの例を示します。
ドメイン外テスト結果: 表 2 に示すように、MedSAM (タイト) と比較して、SAT-Nano は 5 つのデータセットの 10 指標のうち 5 指標で MedSAM を上回りました。 MedSAM (Loose) では、すべてのインジケーターで明らかなパフォーマンスの低下があり、MedSAM がユーザーが入力したボックス プロンプトのオフセットに対してより敏感であることを示しています。
アブレーション実験
SAT を設計するとき、ビジュアル バックボーン ネットワークとテキスト エンコーダーは 2 つの重要な部分です。この研究では、SAT フレームワークでさまざまなビジュアル ネットワーク構造またはテキスト エンコーダーを使用し、それらの影響を調査するために一般的なアブレーション実験を試みます。
実験のコストを節約するために、アブレーション実験におけるすべての SAT モデルのトレーニングとテストは、13303 の 3D 画像、151461 のセグメンテーション アノテーション、および 429 の分割カテゴリを含む 49 のデータセットを含む SAT-DS-Nano 上で実行されます。
ビジュアル バックボーン ネットワーク: SAT-Nano のフレームワークの下で、この研究では、比較のために 3 つの主流のセグメンテーション ネットワーク構造、すなわち U-Net (110M パラメーター)、SwinUNETR (107M パラメーター)、および U-Mamba (114M パラメーター) を選択しました。公平に比較するために、このアブレーション実験でそれらを制御するパラメータの量はほぼ同様です。同時に、オーバーヘッドを計算するために、ナレッジ注入のステップが省略され、MedCPT が直接使用されます (MedCPT は、PubMed 文献に基づくテキスト エンコーダーであり、2 億 2,500 万のプライベート ユーザー クリック データを使用してトレーニングされ、最高のパフォーマンスを達成しています)一連の医療言語タスク) として、テキスト エンコーダーがヒントを生成します。 3 つの亜種は、それぞれ U-Net-CPT、SwinUNETR-CPT、および U-Mamba-CPT として示されます。
図 7 からわかるように、ビジュアル バックボーン ネットワークとして U-Net と U-Mamba を使用すると、最終的なセグメンテーション パフォーマンスは比較的近くなり、U-Net は U-Mamba よりわずかに優れていますが、SwinUNETR を使用した場合のセグメンテーション パフォーマンスは高くなります。低下が大幅に改善されました。最後に、研究チームは SAT のビジュアル バックボーン ネットワークとして U-Net を選択しました。
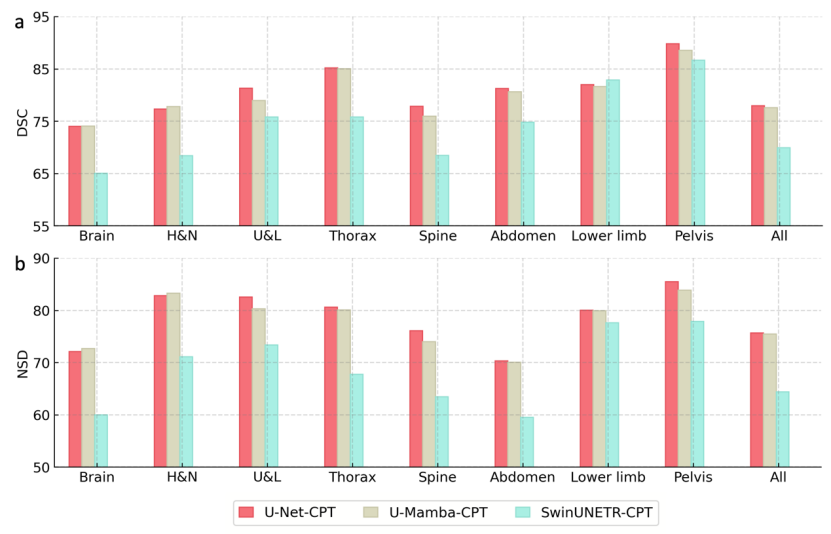
テキスト エンコーダ: SAT-Nano のフレームワークに基づいて、この研究では比較のために 3 つの代表的なテキスト エンコーダを選択しました。上で提案された知識注入方法を使用してトレーニングされたテキスト エンコーダ (Ours と表記)、最先端のテキスト エンコーダ医療テキスト エンコーダ MedCPT が使用され、医療データ用に微調整されていないテキスト エンコーダ BERT-base が使用されます。
公平性を保つため、このアブレーション実験ではビジュアルネットワークとして一律にU-Netを使用します。 3 つの亜種は、それぞれ U-Net-Ours、U-Net-CPT、U-Net-BB と呼ばれます。図 8 に示すように、全体として、MedCPT を使用すると、BERT ベースを使用した場合と比較してセグメンテーション パフォーマンスがわずかに向上しました。これは、ドメインの知識が適切なセグメンテーションのヒントを提供するのに役立つことを示していますが、この研究で提案されたテキスト エンコーダを使用した場合、最高のパフォーマンスが得られました。すべてのカテゴリで達成されており、マルチモーダルな人体解剖学の知識ベースの構築と知識の注入がセグメンテーション モデルに非常に役立つことを示しています。

ロングテール分布は、セグメント化されたデータセットの明らかな特徴です。図9aおよびbに示すように、研究チームはアブレーション実験に使用されたSAT-DS-Nanoの429カテゴリのアノテーション数の分布を調査しました。アノテーションの数が最も多い 10 カテゴリ (上位 2.33%) を先頭クラスとして定義し、アノテーションの数が最も少ない 150 カテゴリ (下位 34.97%) を末尾クラスとして定義すると、末尾クラスのアノテーションは、アノテーションの総数の 3.25 % のみを占めます。
この研究では、ロングテール分布におけるさまざまなカテゴリのセグメンテーション結果に対するテキスト エンコーダーの影響をさらに調査しています。図9cに示すように、研究チームが提案したエンコーダは、ヘッド、テール、ミドルカテゴリーで最高のパフォーマンスを達成し、テールカテゴリーの改善はヘッドカテゴリーよりも明らかでした。同時に、MedCPT はヘッド クラスでは BERT ベースよりもわずかに低いパフォーマンスを示しますが、テール クラスではより優れたパフォーマンスを示します。これらの結果は、ドメイン知識、特にマルチモーダルな人体解剖学の知識の注入が、ロングテール カテゴリのセグメント化に非常に役立つことを示しています。

大規模言語モデルとの組み合わせ
SAT はテキスト プロンプトに基づいてセグメント化できるため、大規模言語モデルのプロキシ ツールとして直接使用して、セグメンテーション機能を提供できます。応用シナリオを実証するために、研究チームは 4 つの多様な実際の臨床データを選択し、GPT4 を使用してレポートからセグメンテーション ターゲットを抽出し、ゼロショット セグメンテーションのために SAT を呼び出しました。その結果を図 10 に示します。
ご覧のとおり、GPT-4 はレポート内の重要な解剖学的構造を非常に適切に検出し、SAT を呼び出して、データを微調整することなく実際の臨床画像上でこれらを非常に適切にセグメント化します。

研究価値
テキストプロンプトに基づいた 3D 医療画像の初の大規模一般セグメンテーション モデルとして、SAT の価値は多くの側面に反映されています。
SAT は効率的で柔軟なユニバーサル セグメンテーションを構築します。SAT-Pro は 1 つのモデルのみを使用し、広範囲のセグメンテーション タスクで 72 nnU-Net と同等のパフォーマンスを示し、モデル パラメーターの量が少なくなります。これは、一連の特殊なモデルの構成、トレーニング、展開を必要とする従来の医療セグメンテーション手法と比較して、一般的なセグメンテーション モデルとしての SAT-Pro がより柔軟で効率的なソリューションであることを示しています。同時に、研究チームは、SAT-Pro が地域外のデータに対してより優れた汎化パフォーマンスを備え、センターを越えた移行などの臨床ニーズをより適切に満たせることも証明しました。
SAT は、大規模なセグメンテーション データの事前トレーニングに基づいた基本モデルです。SAT-Pro が大規模なセグメンテーション データ セットでトレーニングされた後、細かい処理を通じて特定のデータ セットに転送されると、パフォーマンスが大幅に向上します。チューニングが施されており、nnU-Nets よりも全体的にパフォーマンスが優れています。これは、SAT が、微調整された転送を通じて特定のタスクのパフォーマンスを向上させ、それによって汎用セグメンテーションと特殊なセグメンテーションの臨床ニーズのバランスをとることができる強力な基本セグメンテーション モデルとみなすことができることを示しています。
SAT は、テキスト プロンプトに基づいて正確かつ堅牢なセグメンテーションを実現します。Box プロンプトに基づくインタラクティブ セグメンテーション モデルと比較して、テキスト プロンプトに基づく SAT は、より正確でプロンプトに強いセグメンテーション結果を達成でき、ユーザーを節約できます。ボックスの描画にかかる時間を短縮し、自動でバッチ対応のユニバーサル セグメンテーションを実現します。
SAT は、大規模な言語モデルのプロキシ ツールとして使用できます。研究チームは、SAT が大規模な言語モデルとシームレスに接続できることを実際の臨床データで実証しました。テキストをブリッジとして使用して、任意の言語モデルにセグメンテーションおよび位置決め機能を直接提供します。大規模な言語モデル。これは、ジェネラリスト医療用人工知能の開発をさらに促進する上で非常に価値があります。
セグメンテーションに対するモデル サイズの影響: この研究では、サイズの異なる 2 つのモデル、SAT-Nano と SAT-Pro をトレーニングすることにより、ドメイン内テストで SAT-Pro が SAT-Nano と比較して大幅に向上していることが観察されました。 。これは、大規模なデータセットで一般的なセグメンテーション モデルをトレーニングする場合にもスケーリング則が適用されることを意味します。
セグメンテーションに対するドメイン知識の影響: 研究チームは、初のマルチモーダル人体解剖学の知識ベースを提案し、知識強化を使用して一般的なセグメンテーション モデル、特にロングテール カテゴリのセグメンテーションのパフォーマンスを向上させることを検討しました。セグメンテーション アノテーション、特にロングテール カテゴリに関するアノテーションが比較的少ないことを考慮すると、この探索は一般的なセグメンテーション モデルを構築する上で非常に重要です。
以上がオープンソースの3D医療用大型モデルSATは、497個のオルガノイドをサポートし、72nnU-Netsを超える性能を持っています。上海交通大学のチームによってリリースされました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。