AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com、zhaoyunfeng@jiqizhixin.com
この論文の著者は、ファーウェイのモントリオール ノアズ アーク研究所の Kang Jikun、Li Xinze、Chen Xi、Amirreza Kazemi、Chen Boxing です。 人工知能 (AI) は、過去 10 年間で、特に自然言語処理とコンピューター ビジョンの分野で大きな進歩を遂げました。しかし、AI の認知能力と推論能力をどのように向上させるかは依然として大きな課題です。 最近、「MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time」というタイトルの論文で、ツリー検索ベースの推論時間機能改善手法 MindStar [1] が提案され、オープンソース モデル Llama に実装されています。 -13-B とミストラル-7B は、数学的問題に関してクローズドソースの近似大規模モデル GPT-3.5 と Grok-1 の推論能力を達成しました。 
- 論文タイトル: MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
- 論文アドレス: https://arxiv.org/abs/2405.16265v2

図 1: さまざまな大規模言語モデルの数学的精度。 LLaMA-2-13B は、数学的パフォーマンスは GPT-3.5 (4 ショット) と同等ですが、計算リソースを約 200 倍節約します。 モデル規模の急速な成長に伴い、Transformer ベースの大規模言語モデル (LLM) は命令準拠 [1,2] とコーディング支援 [3,4] になりました。 ] 印象的な結果は、クリエイティブライティングなどの分野で実証されています[5]。ただし、複雑な推論タスクを解決する LLM の能力を解放することは依然として課題です。いくつかの最近の研究 [6,7] は、教師あり微調整 (SFT) を通じて問題を解決しようとしています。新しい推論データ サンプルを元のデータ セットと混合することで、LLM はこれらのサンプルの基礎となる分布を学習し、基礎となる分布を模倣しようとします。目に見えない推論タスクを解決するためのロジックを学びましょう。このアプローチではパフォーマンスが向上しますが、広範なトレーニングと追加のデータ準備に大きく依存しています[8、9]。 Llama-3 レポート [10] は重要な観察を強調しています: 困難な推論問題に直面したとき、モデルは正しい推論軌道を生成することがあります。これは、モデルが正しい答えを生成する方法を知っているものの、それを選択するのに苦労していることを示唆しています。この発見に基づいて、私たちは単純な質問をしました。LLM が適切な出力を選択できるように支援することで、LLM の推論能力を強化できるでしょうか?これを調査するために、LLM の出力選択にさまざまな報酬モデルを利用した実験を実施しました。実験結果は、ステップレベルの選択が従来の CoT 方法よりも大幅に優れていることを示しています。 
️図 2 MindStar のアルゴリズム アーキテクチャ図
新しい推論検索を導入しますフレームワーク - MindStar (M*)、推論タスクを検索問題として扱い、プロセス監視モデル (プロセス) の報酬を活用することにより、 -教師付き報酬モデル、PRM)、M * は推論ツリー空間内を効果的にナビゲートし、ほぼ最適なパスを特定します。ビーム検索 (BS) とレビン ツリー検索 (LevinTS) のアイデアを組み合わせることで、検索効率がさらに向上し、限られた計算複雑さ内で最適な推論パスが見つかります。
プロセス教師あり報酬モデル (PRM) は、大規模言語モデル (LLM) 生成の中間ステップを評価して、正しい推論パスの選択を支援するように設計されています。このアプローチは、他のアプリケーションにおける PRM の成功に基づいています。具体的には、PRM は現在の推論パス
と潜在的な次のステップ を入力として受け取り、報酬値
PRM は、現在の推論軌跡全体を考慮して新しいステップを評価し、パス全体に対する一貫性と忠実性を促進します。高い報酬値は、新しいステップ
) が特定の推論パス に対して正しい可能性が高く、拡張パスをさらに探索する価値があることを示します。逆に、報酬値が低い場合は、新しいステップが間違っている可能性があることを示します。これは、このパスに従う解決策も間違っている可能性があることを意味します。
M* アルゴリズムは、正しい解決策が見つかるまで反復する 2 つの主要なステップで構成されます:
1 推論パスの拡張: 各反復で、基礎となる LLM が現在の推論パスの次のステップを生成します。 。
2. 評価と選択: PRM を使用して生成されたステップを評価し、これらの評価に基づいて次の反復の推論パスを選択します。
拡張する推論パスを選択した後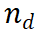 、LLM から次のステップを収集するためのプロンプト テンプレート (例 3.1) を設計しました。例が示すように、LLM は元の質問を {question} として扱い、現在の推論パスを {answer} として扱います。アルゴリズムの最初の反復では、選択されたノードは質問のみを含むルート ノードであるため、{answer} は空であることに注意してください。推論パス
、LLM から次のステップを収集するためのプロンプト テンプレート (例 3.1) を設計しました。例が示すように、LLM は元の質問を {question} として扱い、現在の推論パスを {answer} として扱います。アルゴリズムの最初の反復では、選択されたノードは質問のみを含むルート ノードであるため、{answer} は空であることに注意してください。推論パス  の場合、LLM は N 個の中間ステップを生成し、それらを現在のノードの子として追加します。アルゴリズムの次のステップでは、これらの新しく生成された子ノードが評価され、さらなる拡張のために新しいノードが選択されます。また、ステップを生成するもう 1 つの方法は、ステップ マーカーを使用して LLM を微調整することであることもわかりました。ただし、これは LLM の推論能力を低下させる可能性があり、さらに重要なことに、重みを変更せずに LLM の推論能力を強化するというこの記事の焦点に反します。 推論ツリーを展開した後、事前トレーニングされた手続き型教師あり報酬モデル (PRM) を使用して、新しく生成された各ステップを評価します。前述したように、PRM はパスとステップを受け取り、対応する報酬値を返します。評価後、展開する次のノードを選択するためのツリー検索アルゴリズムが必要です。私たちのフレームワークは特定の検索アルゴリズムに依存せず、この作業では、Beam Search と Levin Tree Search という 2 つの最良優先検索メソッドをインスタンス化します。 GSM8K および MATH データセットの広範な評価により、M* がオープンソース モデル (LLaMA-2 など) の推論機能を大幅に向上させ、そのパフォーマンスが同等であることが示されました。これは、より大きなクローズドソース モデル (GPT-3.5 や Grok-1 など) と同等でありながら、モデル サイズと計算コストを大幅に削減します。これらの発見は、計算リソースを微調整から推論時の検索に移行する可能性を浮き彫りにし、効率的な推論強化技術に関する将来の研究に新たな道を開くものです。
の場合、LLM は N 個の中間ステップを生成し、それらを現在のノードの子として追加します。アルゴリズムの次のステップでは、これらの新しく生成された子ノードが評価され、さらなる拡張のために新しいノードが選択されます。また、ステップを生成するもう 1 つの方法は、ステップ マーカーを使用して LLM を微調整することであることもわかりました。ただし、これは LLM の推論能力を低下させる可能性があり、さらに重要なことに、重みを変更せずに LLM の推論能力を強化するというこの記事の焦点に反します。 推論ツリーを展開した後、事前トレーニングされた手続き型教師あり報酬モデル (PRM) を使用して、新しく生成された各ステップを評価します。前述したように、PRM はパスとステップを受け取り、対応する報酬値を返します。評価後、展開する次のノードを選択するためのツリー検索アルゴリズムが必要です。私たちのフレームワークは特定の検索アルゴリズムに依存せず、この作業では、Beam Search と Levin Tree Search という 2 つの最良優先検索メソッドをインスタンス化します。 GSM8K および MATH データセットの広範な評価により、M* がオープンソース モデル (LLaMA-2 など) の推論機能を大幅に向上させ、そのパフォーマンスが同等であることが示されました。これは、より大きなクローズドソース モデル (GPT-3.5 や Grok-1 など) と同等でありながら、モデル サイズと計算コストを大幅に削減します。これらの発見は、計算リソースを微調整から推論時の検索に移行する可能性を浮き彫りにし、効率的な推論強化技術に関する将来の研究に新たな道を開くものです。 
表 1 は、GSM8K および MATH 推論ベンチマークにおけるさまざまなソリューションの比較結果を示しています。各エントリの数字は、解決された問題の割合を示します。表記 SC@32 は 32 個の候補結果間の自己一貫性を表し、n ショットは少数のショットの例での結果を表します。 CoT-SC@16 は、16 の思考連鎖 (CoT) 候補結果間の自己一貫性を指します。 BS@16 は、各ステップ レベルで 16 個の候補結果を含むビーム探索法を表します。一方、LevinTS@16 は、同じ数の候補結果を使用するレビン ツリー探索法を詳しく説明します。 MATH データセット上の GPT-4 の最新の結果が GPT-4-turbo-0409 であることは注目に値します。これは GPT-4 ファミリで最高のパフォーマンスを表すため、特に強調します。 
図 3 ステップレベルの候補の数が変化するにつれて M* のパフォーマンスがどのように変化するかを研究します。基本モデルとして Llama-2-13B を、探索アルゴリズムとしてビーム探索 (BS) をそれぞれ選択しました。 
図 4 MATH データセット上の Llama-2 および Llama-3 モデル ファミリのスケーリング則。すべての結果は元の情報源から派生したものです。 Scipy ツールと対数関数を使用して近似曲線を計算します。 
表 2 質問に答えるときにさまざまな方法で生成されるトークンの平均数この論文では、推論機能を強化するための新しい検索ベースの推論フレームワークである MindStar (M*) を紹介します。事前にトレーニングされた大規模な言語モデル。推論タスクを検索問題として扱い、プロセス監視の報酬モデルを活用することで、M* は推論ツリー空間内を効率的にナビゲートし、最適に近いパスを特定します。ビーム探索とレビンツリー探索の考え方を組み合わせることで、探索効率がさらに向上し、限られた計算複雑さの中で最適な推論パスを確実に見つけることができます。広範な実験結果は、M* がオープンソース モデルの推論機能を大幅に向上させ、そのパフォーマンスが大規模なクローズド ソース モデルと同等であると同時に、モデル サイズと計算コストを大幅に削減することを示しています。 これらの研究結果は、コンピューティング リソースを微調整から推論時の検索に移行することには大きな可能性があり、効率的な推論強化テクノロジに関する将来の研究に新たな道を開くことを示しています。 [1] Nisan Stiennon、Long Ouyang、Jeffrey Wu、Daniel Ziegler、Ryan Lowe、Chelsea Voss、Alec Radford、Dario Amodei、Paul F Christiano 要約することを学ぶ。 Advances in Neural Information Processing Systems、33:3008–3021、2020。[2] Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 他、人間のフィードバックによる指示に従う言語モデルのトレーニング、35:27730–27744、2022。 [3] Ziyang Luo、Can Xu。 、Pu Zhao、Qingfeng Sun、Xiubo Geng、Wenxiang Hu、Chongyang Tao、Jing Ma、Qingwei Lin、および Daxin Jiang。Wizardcoder: evol-instruct を使用したコード大規模言語モデルの強化 arXiv:2306.08568、2023。 [4] Mark Chen、Jerry Tworek、Heewoo Jun、Qiming Yuan、Henrique Ponde de Oliveira Pinto、Jared Kaplan、Harri Edwards、Yuri Burda、Nicholas Joseph、Greg Brockman、他 コードでトレーニングされた大規模言語モデルの評価。プレプリント arXiv:2107.03374、2021.[5] カルロス・ゴメス・ロドリゲスとポール・ウィリアムズ モデルの連合: クリエイティブライティングに関する arXiv プレプリント arXiv:2310.08433.。
[6] Longhui Yu、Weisen Jiang、Han Shi、Jincheng Yu、Zhengying Liu、Yu Zhang、James T Kwok、Zhenguo Li、Adrian Weller、Weiyang Metamath: arXiv に対する独自の数学的質問をブートストラップします。プレプリント arXiv:2309.12284、2023。[7] Zhihong Shao、Peiyi Wang、Qihao Zhu、Junxiao Song、Mingchuan Zhang、YK Li、Y Wu、Daya Guo: の限界を押し上げる。オープン言語モデルにおける数学的推論。arXiv プレプリント arXiv:2402.03300、2024.[8] Keiran Paster、Marco Dos Santos、Zhangir Azerbayev、Jimmy Ba: 高品質の数学 Web テキストのオープン データセット。 arXiv プレプリント arXiv:2310.06786、2023.[9] Peiyi Wang、Lei Li、Zhihong Shao、RX Xu、Damai Dai、Yifei Li、Deli Chen、Y Wu、および Zhifang Sou :人間による注釈なしで llm を段階的に検証および強化します。CoRR、abs/2312.08935、2023。[10] Meta AI の紹介: これまでで最も有能な公開利用可能な llm、2024 年 4 月。 URL https://ai.meta.com/blog/meta-llama-3/ アクセス日: 2024-04-30.以上がOpenAI の Q* が待ちきれません。LLM 推論を探索するための Huawei Noah の秘密兵器 MindStar が最初に登場しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



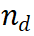
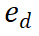
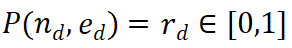
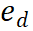
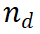
 の場合、LLM は N 個の中間ステップを生成し、それらを現在のノードの子として追加します。アルゴリズムの次のステップでは、これらの新しく生成された子ノードが評価され、さらなる拡張のために新しいノードが選択されます。また、ステップを生成するもう 1 つの方法は、ステップ マーカーを使用して LLM を微調整することであることもわかりました。ただし、これは LLM の推論能力を低下させる可能性があり、さらに重要なことに、重みを変更せずに LLM の推論能力を強化するというこの記事の焦点に反します。
の場合、LLM は N 個の中間ステップを生成し、それらを現在のノードの子として追加します。アルゴリズムの次のステップでは、これらの新しく生成された子ノードが評価され、さらなる拡張のために新しいノードが選択されます。また、ステップを生成するもう 1 つの方法は、ステップ マーカーを使用して LLM を微調整することであることもわかりました。ただし、これは LLM の推論能力を低下させる可能性があり、さらに重要なことに、重みを変更せずに LLM の推論能力を強化するというこの記事の焦点に反します。