
ホームページ >テクノロジー周辺機器 >AI >史上初のリアルタイムAI動画生成技術:DiTユニバーサル、10.6倍高速
史上初のリアルタイムAI動画生成技術:DiTユニバーサル、10.6倍高速

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-28 19:14:461385ブラウズ
DiT を使用すると、品質を損なうことなく、トレーニングも必要なくビデオを生成できます。
リアルタイム AI ビデオ生成が登場!
水曜日、シンガポール国立大学のYou Yang氏のチームは、リアルタイムで出力できる業界初のDiTベースのビデオ生成方法を提案した。

このテクノロジーは、ピラミッド アテンション ブロードキャスト (PAB) と呼ばれます。冗長なアテンション計算を削減することで、PAB は、Open-Sora、Open-Sora-Plan、Latte 品質などの一般的な DiT ベースのビデオ生成モデルの利点を犠牲にすることなく、最大 21.6 FPS のフレーム レートと 10.6 倍の高速化を実現します。トレーニングを必要としない方法として、PAB は将来の DiT ベースのビデオ生成モデルにアクセラレーションを提供し、リアルタイム ビデオを生成する機能を提供できることは注目に値します。
今年以来、OpenAI の Sora やその他の DiT ベースのビデオ生成モデルが AI 分野に新たな波を引き起こしています。ただし、画像生成と比較すると、ビデオ生成に対する人々の注目は基本的に品質にあり、DiT モデル推論を高速化する方法の探索に焦点を当てた研究はほとんどありません。ビデオ生成モデルの推論の高速化は、生成 AI アプリケーションにとってすでに優先事項となっています。
PAB手法の出現により、私たちに道が開かれました。独自方式とPAB動画生成速度の比較。著者は、Open-Sora で 5 つの 4 秒 (192 フレーム) 480p 解像度ビデオをテストしました。 
ピラミッド アテンション ブロードキャスト
最近、Sora やその他の DiT ベースのビデオ生成モデルが広く注目を集めています。ただし、画像生成と比較して、DiT ベースのビデオ生成モデルの推論の高速化に焦点を当てた研究はほとんどありません。さらに、単一のビデオを生成する推論コストは高くなる可能性があります。 ➢ 図 1: 現在の拡散ステップと以前の拡散ステップの間の差異、および微分誤差 (MSE) が定量化されます。実装
この研究は、ビデオ拡散変換器における注意メカニズムの 2 つの重要な観察を明らかにします: まず、異なるタイム ステップでの注意の差は、最初と最後の 15 で U 字型のパターンを示します。 % のステップは大幅に変化しますが、中央の 70% のステップはわずかな差はあるものの非常に安定しています。
まず、異なるタイム ステップでの注意の差は、最初と最後の 15 で U 字型のパターンを示します。 % のステップは大幅に変化しますが、中央の 70% のステップはわずかな差はあるものの非常に安定しています。
第 2 に、安定した中間セグメント内では、注意のタイプ間に違いがあります。空間的な注意は、エッジやテクスチャなどの高周波要素に関係して最も変化します。時間的な注意は、ビデオ内の動きやダイナミクスに関連する中周波の変化を示します。クロスモーダル アテンションは最も安定しており、テキストのセマンティクスを反映する低周波信号と同様に、テキストとビデオ コンテンツを結び付けます。 これに基づいて、研究チームは不必要な注意の計算を減らすためにピラミッド型の注意ブロードキャストを提案しました。中間部分では、注意力に小さな違いが見られ、この研究では 1 つの拡散ステップの注意力出力を後続のいくつかのステップにブロードキャストすることで、計算コストが大幅に削減されます。 さらに、より効率的な計算と最小限の品質損失のために、作者は安定性と異なる注意の違いに応じて異なるブロードキャスト範囲を設定します。ポストトレーニングを行わなくても、このシンプルかつ効果的な戦略により、生成されたコンテンツの品質低下を無視して最大 35% の高速化が達成されます。
図 2: この研究では、注意力の違いに基づいて 3 つの注意力に対して異なるブロードキャスト範囲が設定されるピラミッド注意力ブロードキャストを提案しています。注目度の変化が小さいほど、放送範囲は広くなります。このメソッドは実行時に、アテンションの結果を次のいくつかのステップにブロードキャストして、冗長なアテンションの計算を回避します。 x_t は、タイム ステップ t でのフィーチャを指します。
Parallel
下の図 3 は、この記事の方法と元の Dynamic Sequence Parallel (DSP) の比較を示しています。一時的な注意が分散されると、あらゆるコミュニケーションを避けることができます。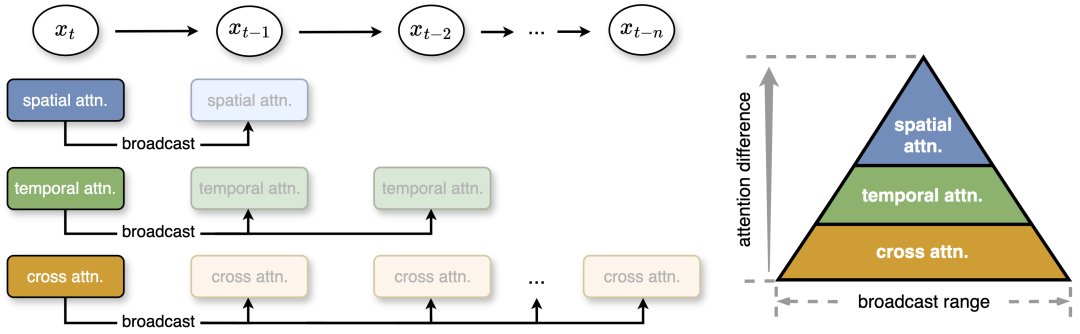
ビデオ生成の速度をさらに向上させるために、この記事では DSP を使用してシーケンスの並列性を向上させます。 Sequence Parallel はビデオを複数の GPU にわたる異なる部分に分割し、各 GPU のワークロードを軽減し、ビルドの遅延を短縮します。ただし、DSP では大量の通信オーバーヘッドが発生するため、2 つの全対全通信を準備するには時間と注意が必要です。
PAB で時間的注意を伝播することにより、この記事では時間的注意を計算する必要がなくなり、それによってコミュニケーションが削減されます。これに応じて、通信オーバーヘッドが 50% 以上大幅に削減され、リアルタイム ビデオ生成のためのより効率的な分散推論が可能になります。
評価結果
加速度
次の図は、8 つの NVIDIA H100 GPU で 1 つのビデオを生成する際に、さまざまなモデルで測定された合計 PAB 遅延を示しています。単一の GPU を使用した場合、著者らは 1.26 から 1.32 倍の高速化を達成し、異なるスケジューラ間でも安定した状態を維持しました。
この方法を複数の GPU に拡張すると、10.6 倍の高速化が達成され、効率的な逐次並列処理の改善の恩恵を受けて、GPU の数に応じてほぼ線形の拡張が達成されました。

定性的な結果
次の 3 つのビデオは、それぞれ Open-Sora、Open-Sora-Plan、Latte であり、この記事の方法の効果を比較するために、3 つの異なるモデルが使用されています。この記事の方法では、GPU の数が異なると、異なる程度の FPS アクセラレーションが達成されることがわかります。 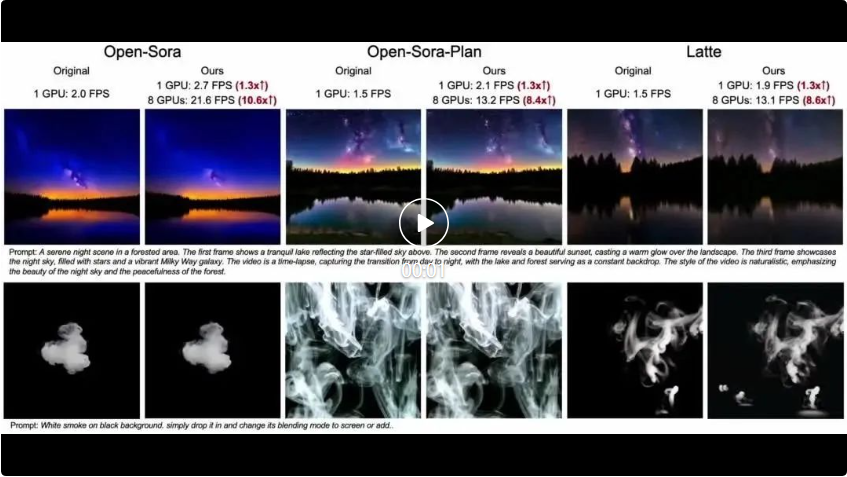
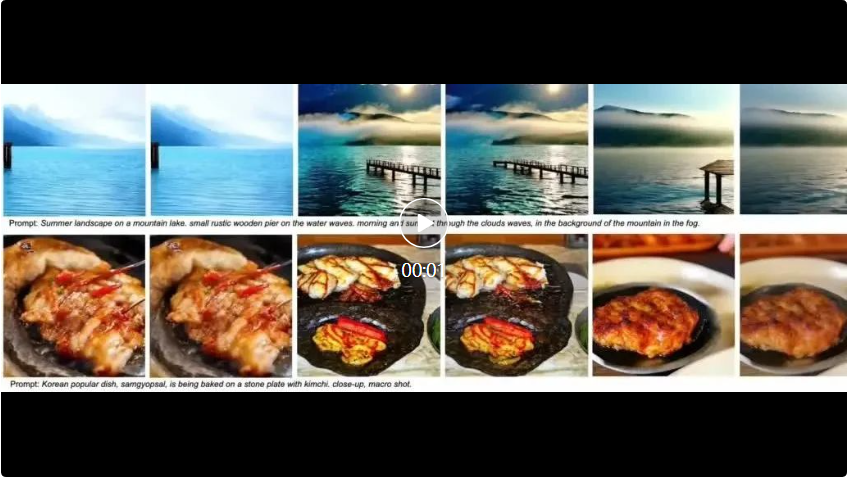

定量的結果
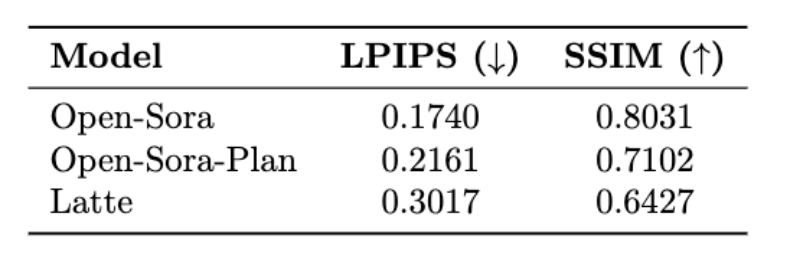
次の表は、Open-Sora、Open-Sora-Plan の 3 つのモデルの LPIPS (学習知覚イメージ パッチ類似性) と SSIM (構造類似性) を示しています。およびラテ ) インジケーターの結果。
技術的な詳細と評価結果については、今後の論文でご覧いただけます。
プロジェクトアドレス:https://oahzxl.github.io/PAB/
参考リンク:
https://oahzxl.github.io/PAB/
以上が史上初のリアルタイムAI動画生成技術:DiTユニバーサル、10.6倍高速の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。