AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この研究では、10 個のデータセットに対する高度なマルチモーダル基本モデルのマルチサンプル コンテキスト学習を評価し、持続的なパフォーマンスの向上を明らかにしました。バッチクエリは、パフォーマンスを犠牲にすることなく、サンプルごとのレイテンシと推論コストを大幅に削減します。これらの調査結果は、次のことを示しています: 大規模なデモ例を活用することで、従来の微調整を行わずに、新しいタスクやドメインに迅速に適応できます。 
- ペーパーアドレス: https://arxiv.org/abs/2405.09798
- コードアドレス: https://github.com/stanfordmlgroup/ManyICL
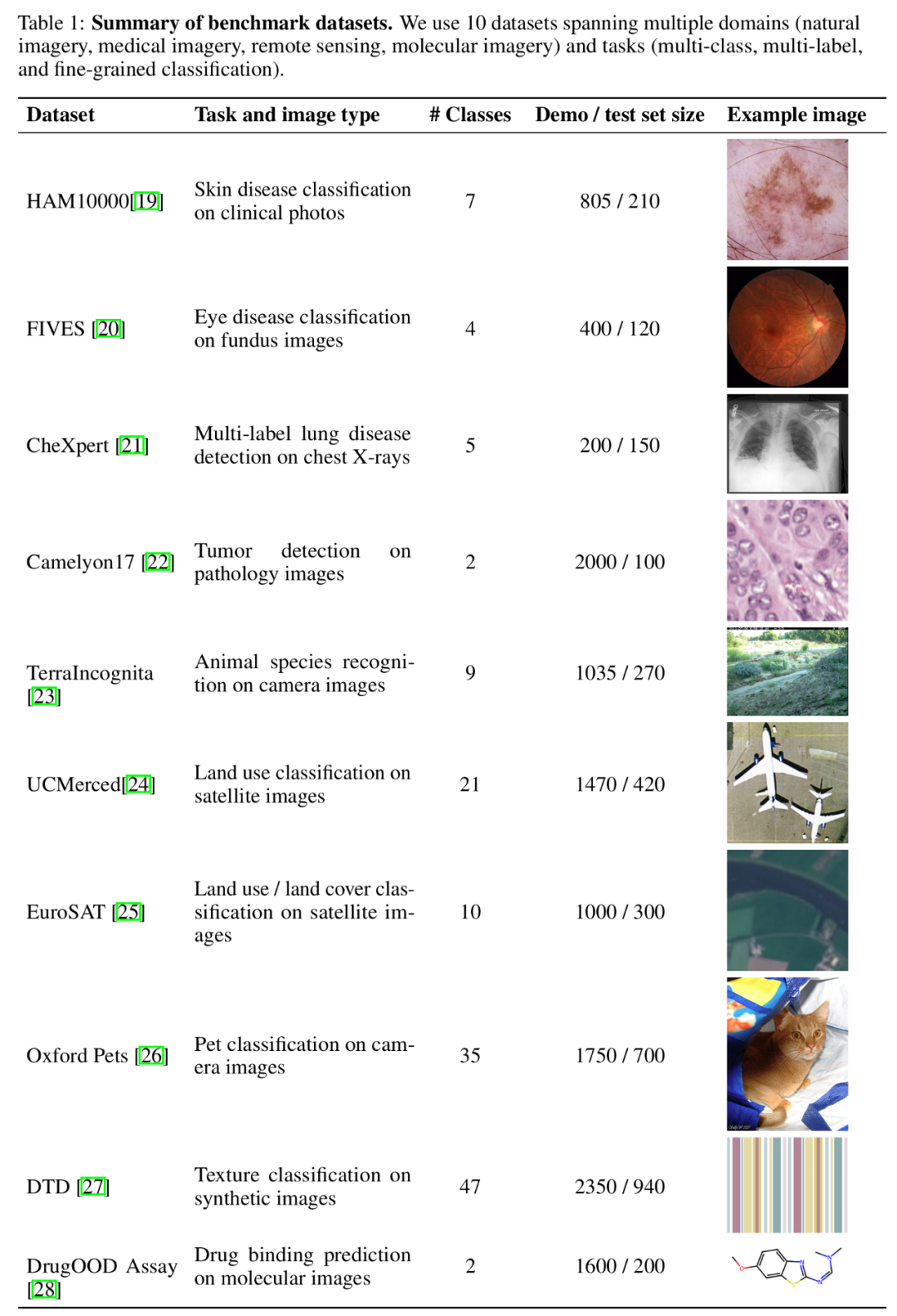
マルチモーダル基盤モデルに関する最近の研究では、インコンテキスト学習 (ICL) がモデルのパフォーマンスを向上させる効果的な方法の 1 つであることが証明されています。 ただし、基本モデルのコンテキストの長さによって制限されるため、特に画像を表現するために多数の視覚トークンを必要とするマルチモーダル基本モデルの場合、既存の関連研究は、少数のサンプルを提供することに限定されています。コンテキスト。 興味深いことに、最近の技術の進歩により、モデルのコンテキストの長さが大幅に増加し、より多くの例を使用してコンテキスト学習を探索できる可能性が開かれました。 これに基づいて、スタンフォード Ng チームの最新研究 - ManyICL は、主に、少数のサンプル (100 未満) から複数のサンプルまでのコンテキスト学習における現在の最先端のマルチモーダル基本モデルを評価します。サンプル (最大 2000) でのパフォーマンス。複数のドメインとタスクからのデータ セットをテストすることで、チームはモデルのパフォーマンス向上におけるマルチサンプル コンテキスト学習の大きな効果を検証し、バッチ クエリがパフォーマンス、コスト、レイテンシに与える影響を調査しました。 メニーショット ICL とゼロサンプル、少数サンプル ICL の比較。 この研究には、GPT-4o、GPT4 (V)-Turbo、および Gemini 1.5 Proの 3 つの高度なマルチモーダル基本モデルが選択されました。 GPT-4o の優れたパフォーマンスのため、研究チームは本文で GPT-4o と Gemini 1.5 Pro に焦点を当てています。付録の GPT4 (V)-Turbo の関連コンテンツを参照してください。 データセットに関して、研究チームは、さまざまな分野(自然画像、医療画像、リモートセンシング画像、分子イメージングなどを含む)およびタスク(多重分類、多重ラベル分類を含む)にわたる10のデータセットに対して実験を実施しました。および詳細な分類)広範な実験。
ベンチマークデータセットの概要。
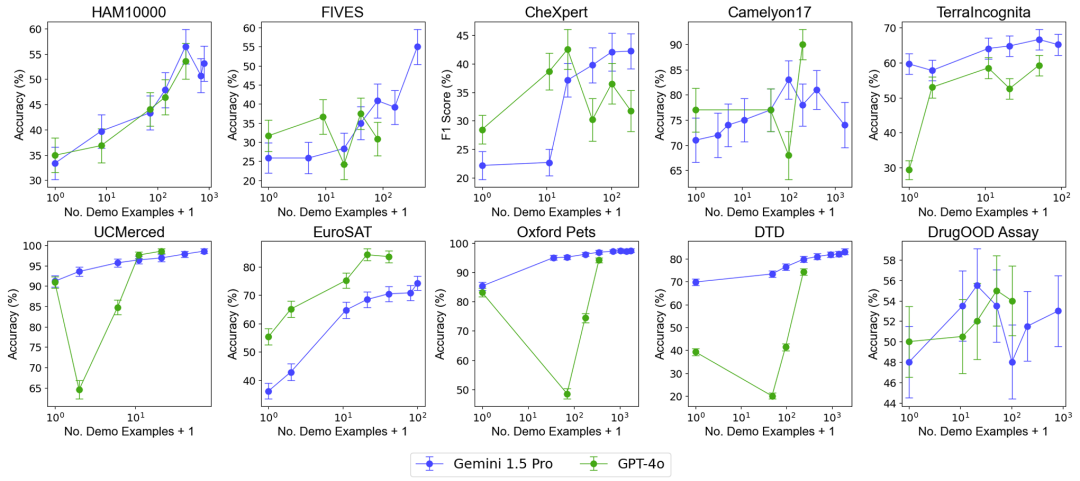
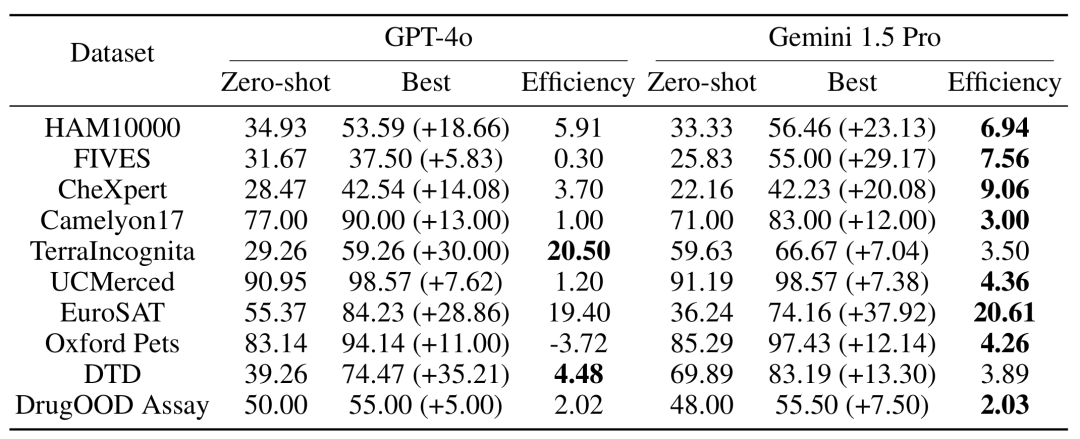
例の数の増加がモデルのパフォーマンスに及ぼす影響をテストするために、研究チームは、コンテキストで提供される例の数を徐々に増やし、最大 2,000 個近くの例まで増やしました。同時に、マルチサンプル学習の高コストと高レイテンシを考慮して、研究チームはクエリのバッチ処理の影響も調査しました。ここでのバッチ クエリとは、単一の API 呼び出しで複数のクエリを処理することを指します。 マルチサンプルコンテキスト学習のパフォーマンス評価全体的なパフォーマンス: ほぼ 2000 のサンプルを使用したマルチサンプルコンテキスト学習は、すべてのサンプルで優れたパフォーマンスを発揮しますデータセット 少数ショット学習。 Gemini 1.5 Pro モデルのパフォーマンスは、例の数が増加するにつれて一貫して対数線形の向上を示しますが、GPT-4o のパフォーマンスはあまり安定していません。
データ効率: この研究では、モデルのコンテキスト学習データ効率、つまりモデルが例から学習する速度を測定しました。結果は、Gemini 1.5 Pro がほとんどのデータセットで GPT-4o よりも高いコンテキスト学習データ効率を示し、これは例からより効果的に学習できることを意味します。
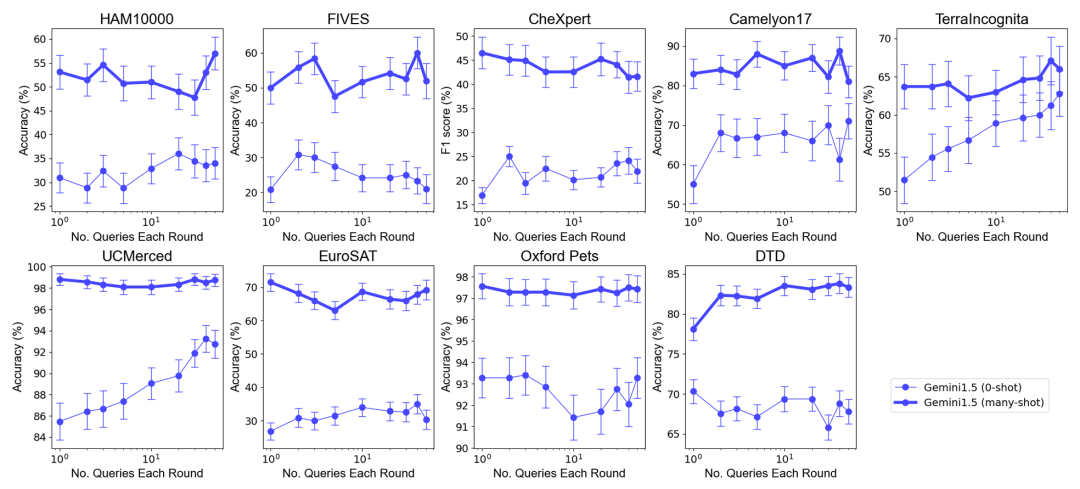
全体的なパフォーマンス: 最適なサンプルセットサイズが選択されたゼロサンプルおよびマルチサンプルのシナリオでは、複数のクエリを 1 つのリクエストにマージしてもパフォーマンスは低下しません。ゼロショット シナリオでは、単一のクエリが多くのデータセットに対してパフォーマンスが低下することに注意してください。対照的に、バッチ クエリではパフォーマンスも向上します。
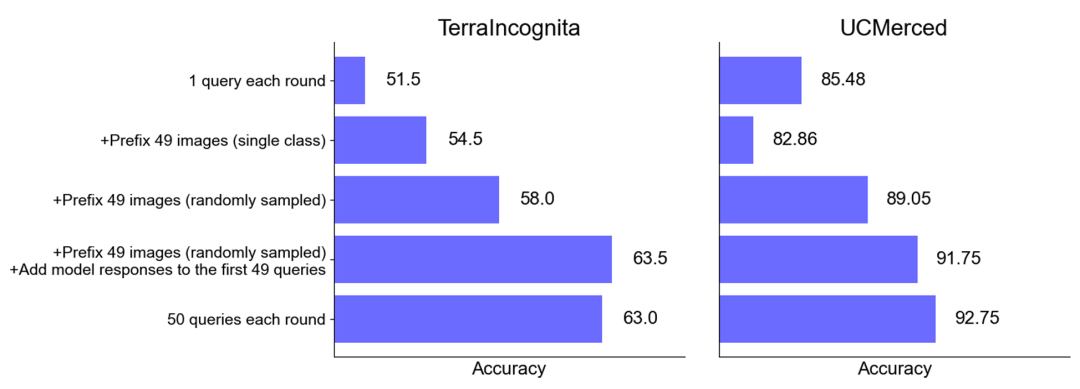
ゼロサンプル シナリオでのパフォーマンスの向上: 一部のデータセット (UCMerced など) では、バッチ クエリによりゼロサンプル シナリオのパフォーマンスが大幅に向上します。研究チームは、これは主にドメインキャリブレーション、クラスキャリブレーション、自己学習(セルフICL)によるものだと分析した。
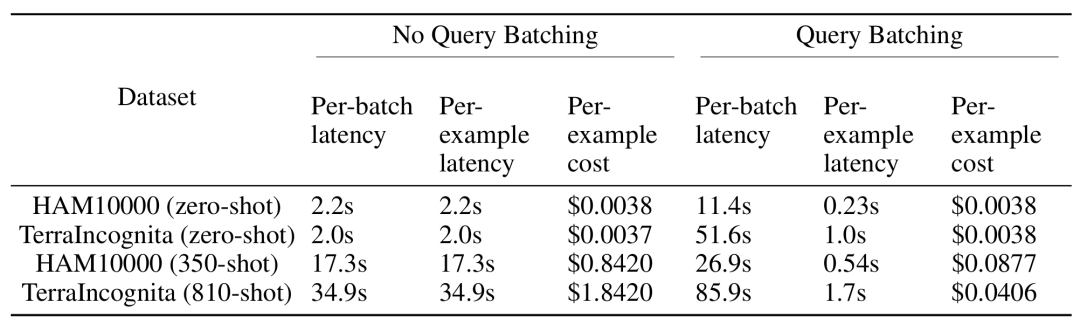
マルチサンプル コンテキスト学習 推論中に長い入力コンテキストを処理する必要がありますが、各サンプルのレイテンシと推論コストはバッチ クエリによって大幅に削減できます。たとえば、HAM10000 データセットでは、350 サンプルのバッチ クエリに Gemini 1.5 Pro モデルを使用すると、レイテンシは 17.3 秒から 0.54 秒に短縮され、コストは 1 サンプルあたり 0.842 ドルから 0.0877 ドルに下がりました。
研究結果は、マルチサンプルコンテキスト学習がマルチモーダル基本モデルのパフォーマンスを大幅に向上させることができることを示しており、特に Gemini 1.5 Pro モデルは複数のデータセットで継続的なパフォーマンス向上を示しています。従来の微調整を必要とせずに、新しいタスクやドメインにより効果的に適応できるようになります。 第 2 に、クエリのバッチ処理により、推論コストとレイテンシを削減しながら、同等またはそれ以上のモデル パフォーマンスを実現でき、実際のアプリケーションで大きな可能性を示します。 一般的に、Andrew Ng のチームによるこの研究は、特に新しいタスクや分野への迅速な適応という点で、マルチモーダル基本モデルの応用に新しい道を切り開きます。 以上がAndrew Ng チームによる新しい成果: マルチモーダルおよびマルチサンプルのコンテキスト学習。微調整を行わずに新しいタスクに迅速に適応します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。