
ホームページ >テクノロジー周辺機器 >AI >コンピューター上で RTX AI チャットボットを使用して Nvidia のチャットを使用する方法
コンピューター上で RTX AI チャットボットを使用して Nvidia のチャットを使用する方法

- 王林オリジナル
- 2024-06-14 18:39:261260ブラウズ
Nvidia は、PC 上で動作し、ChatGPT などと同様の機能を提供する AI チャットボットである Chat with RXT をリリースしました。必要なのは Nvidia RTX GPU だけで、Nvidia の新しい AI チャットボットを使い始める準備は完了です。
RTX を使用した Nvidia チャットとは何ですか?
Nvidia Chat with RTX は、大規模言語モデル (LLM) をコンピューター上でローカルに実行できる AI ソフトウェアです。そのため、ChatGPT のような AI チャットボットをオンラインで使用する代わりに、いつでもオフラインで Chat with RTX を使用できます。
RTX とのチャットは、TensorRT-LLM、RTX アクセラレーション、および量子化された Mistral 7-B LLM を使用して、他のオンライン AI チャットボットと同等の高速パフォーマンスと高品質の応答を提供します。また、検索拡張生成 (RAG) も提供し、チャットボットがファイルを読み取って、提供されたデータに基づいてカスタマイズされた回答を可能にすることができます。これにより、チャットボットをカスタマイズして、より個人的なエクスペリエンスを提供できるようになります。
RTX で Nvidia チャットを試してみたい場合は、コンピューターにダウンロード、インストール、構成する方法を次に示します。
Chat with RTX をダウンロードしてインストールする方法

Nvidia により、コンピューター上でローカルに LLM を実行することがはるかに簡単になりました。 Chat with RTX を実行するには、他のソフトウェアと同様に、アプリをダウンロードしてインストールするだけです。ただし、Chat with RTX を適切にインストールして使用するには、いくつかの最小仕様要件があります。
RTX 30 シリーズまたは 40 シリーズ GPU 16 GB RAM 100 GB の空きメモリ容量 Windows 11PC が最小システム要件を満たしている場合は、アプリをインストールできます。
ステップ 1: Chat with RTX ZIP ファイルをダウンロードします。ダウンロード: Chat with RTX (無料 - 35GB ダウンロード)ステップ 2: 右クリックして 7Zip などのファイル アーカイブ ツールを選択するか、ファイルをダブルクリックして ZIP ファイルを解凍します。すべて抽出を選択します。ステップ 3: 解凍したフォルダーを開き、setup.exe をダブルクリックします。画面上の指示に従い、カスタム インストール プロセス中にすべてのボックスをオンにします。 [次へ] をクリックすると、インストーラーは LLM とすべての依存関係をダウンロードしてインストールします。
Chat with RTX のインストールは、大量のデータをダウンロードしてインストールするため、完了するまでに時間がかかります。インストールプロセスが完了したら、「閉じる」をクリックして完了です。今度は、アプリを試してみましょう。
Nvidia Chat with RTX の使用方法
Chat with RTX は通常のオンライン AI チャットボットのように使用できますが、アクセスを許可したファイルに基づいて出力をカスタマイズできる RAG 機能を確認することを強くお勧めします。
ステップ 1: RAG フォルダーを作成する
RTX とのチャットで RAG の使用を開始するには、AI に分析させたいファイルを保存する新しいフォルダーを作成します。
作成後、データファイルをフォルダーに配置します。保存するデータには、ドキュメント、PDF、テキスト、ビデオなど、さまざまなトピックやファイル タイプが含まれます。ただし、パフォーマンスに影響を与えないように、このフォルダーに配置するファイルの数を制限することもできます。検索するデータが増えると、RTX とチャットすると、特定のクエリに対する応答が返されるまでに時間がかかります (ただし、これはハードウェアにも依存します)。
これでデータベースの準備ができました。RTX でチャットを設定し、質問やクエリに答えるために使用を開始できます。
ステップ 2: 環境をセットアップする
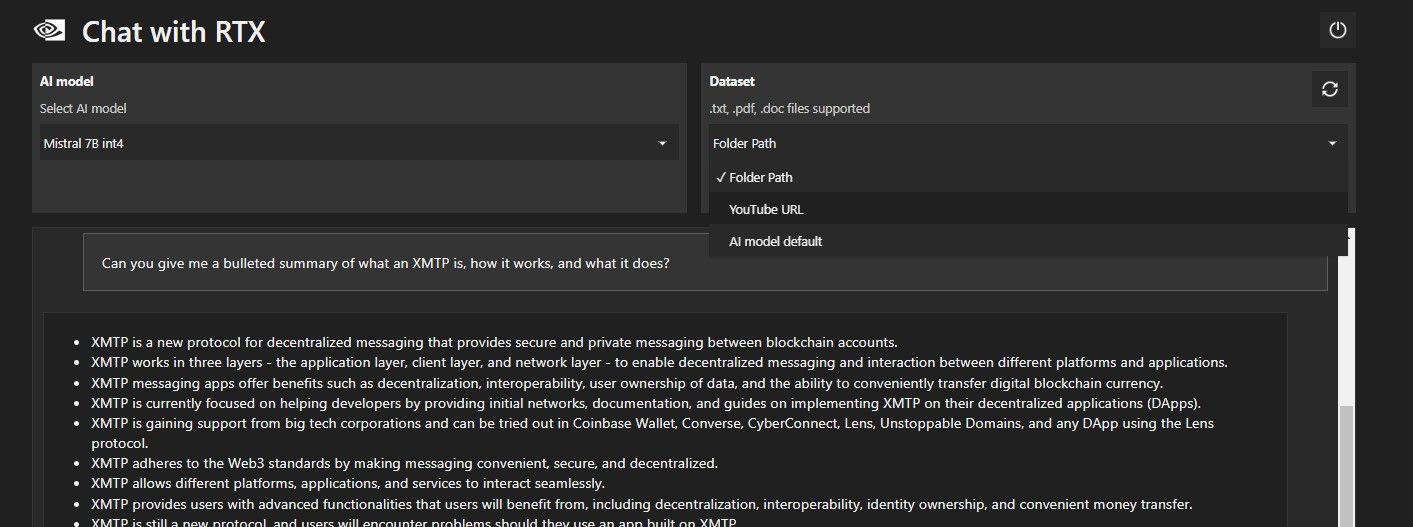
RTX でチャットを開きます。以下の画像のようになります。
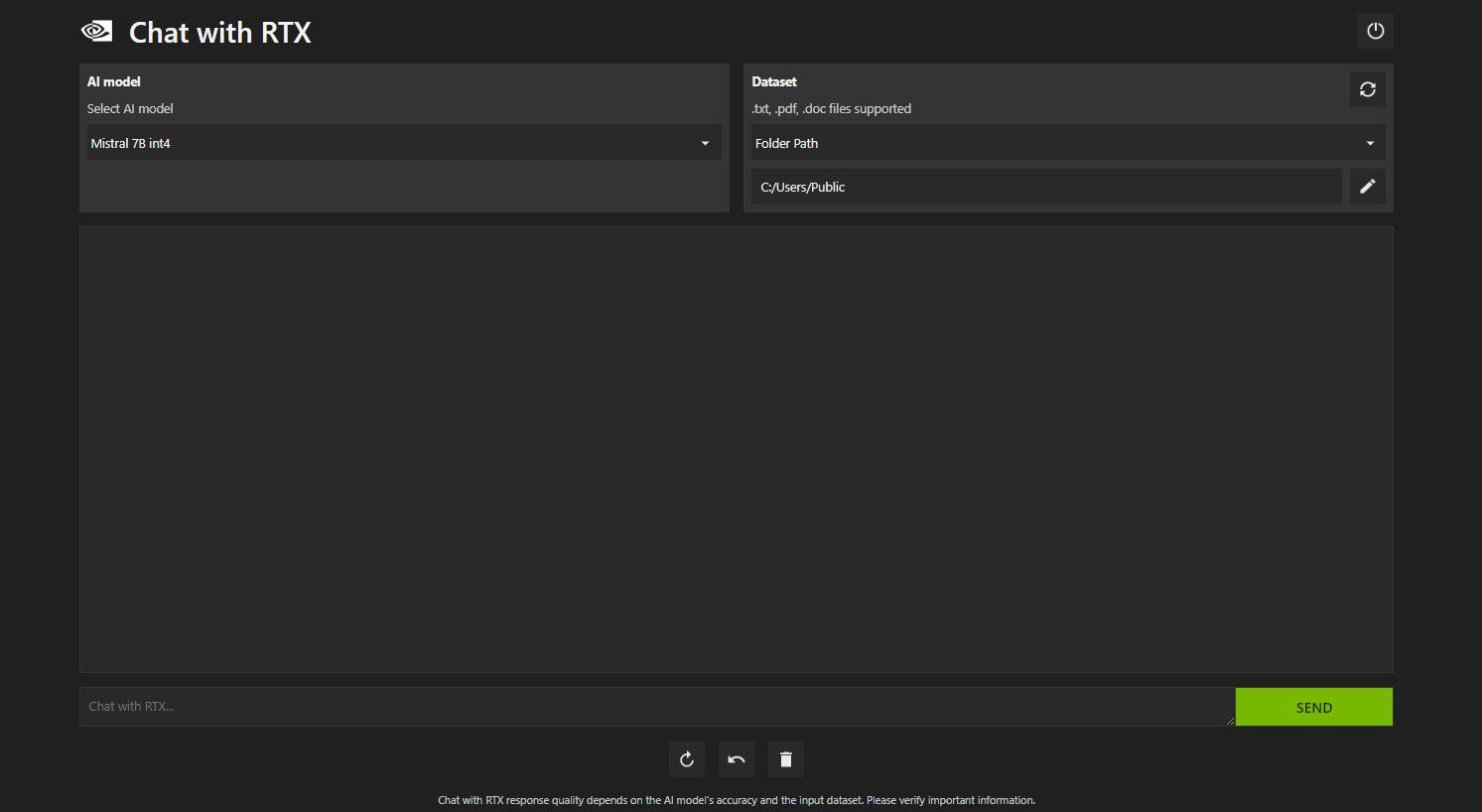
[データセット] で、[フォルダー パス] オプションが選択されていることを確認します。次に、下の編集アイコン (ペンのアイコン) をクリックし、Chat with RTX に読み取らせたいすべてのファイルが含まれるフォルダーを選択します。他のオプションが利用可能な場合は、AI モデルを変更することもできます (執筆時点では、Mistral 7B のみが利用可能です)。
これで、RTX でチャットを使用する準備ができました。
ステップ 3: RTX とチャットで質問してください!
RTX で Chat をクエリするにはいくつかの方法があります。 1つ目は、通常のAIチャットボットのように使用することです。 Chat with RTX にローカル LLM を使用する利点について尋ねたところ、その答えに満足しました。それほど詳しくはありませんでしたが、十分正確でした。
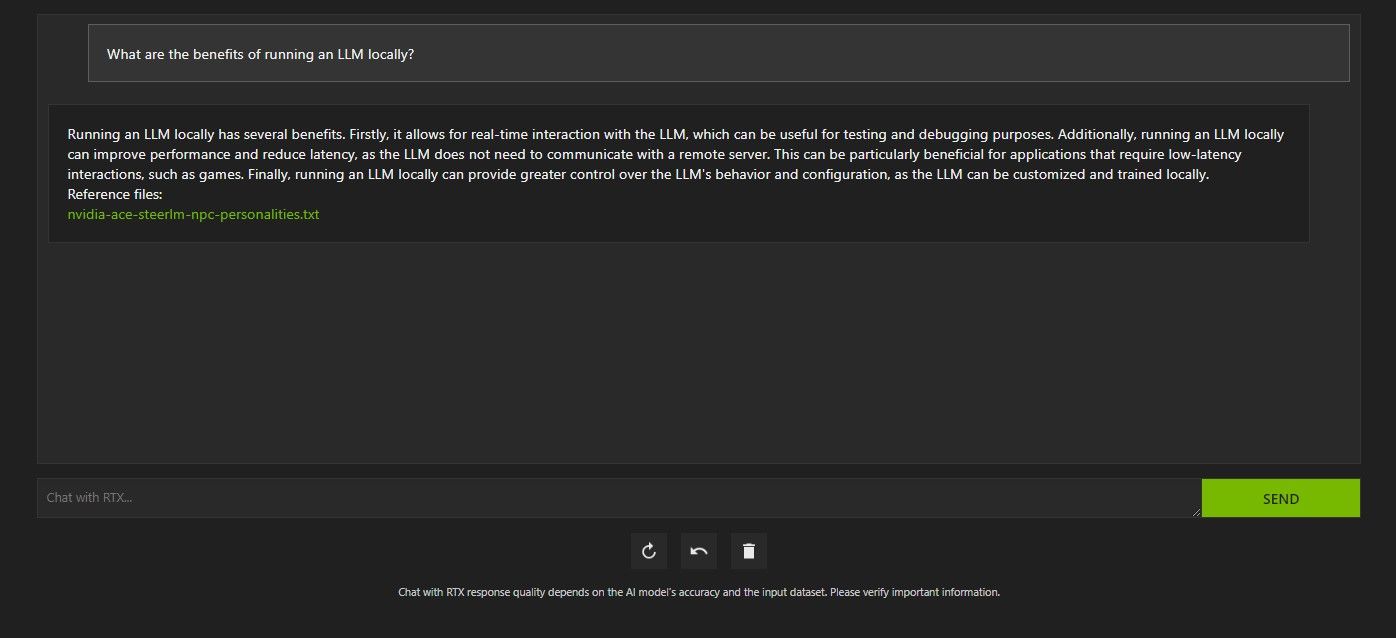
ただし、RTX でのチャットは RAG に対応しているため、パーソナル AI アシスタントとしても使用できます。
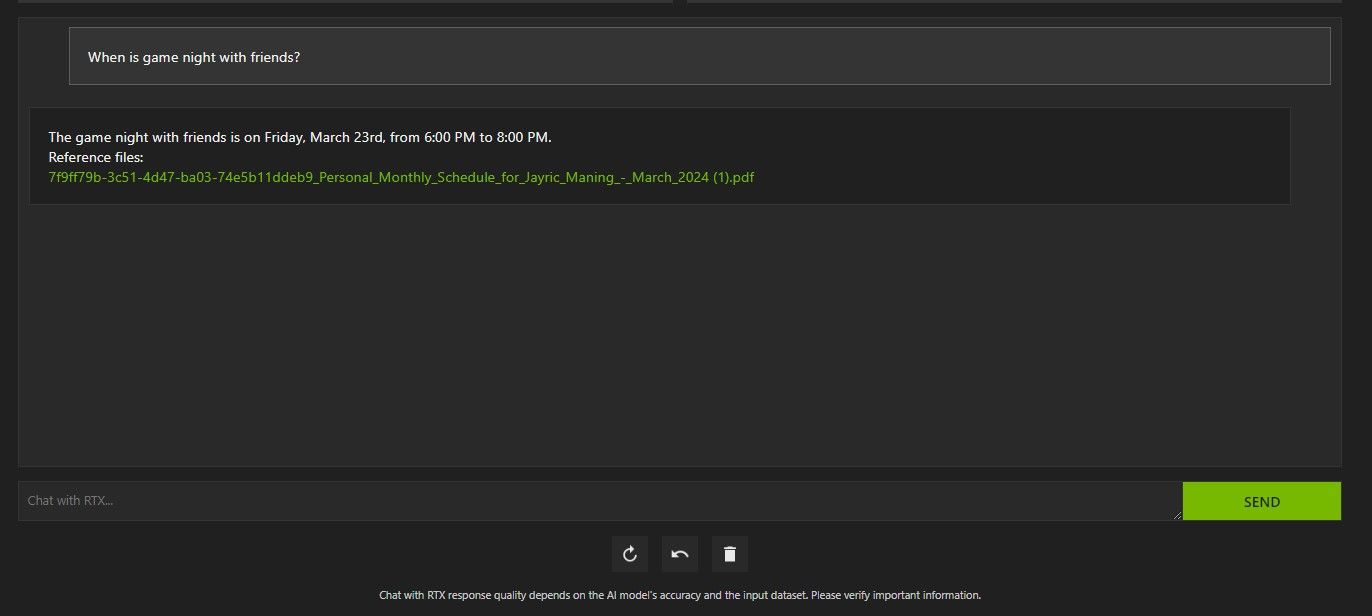
上記では、RTX とのチャットを使用してスケジュールについて尋ねました。データは、スケジュール、カレンダー、イベント、仕事などが含まれた PDF ファイルからのものでした。この場合、Chat with RTX はデータから正しいカレンダー データを取得しています。他のアプリと統合されるまで、このような機能が適切に動作するには、データ ファイルとカレンダーの日付を最新の状態に保つ必要があります。
RTX の RAG とのチャットを有利に使用できる方法はたくさんあります。たとえば、法律文書を読んで概要を示したり、開発中のプログラムに関連するコードを生成したり、忙しくて見られないビデオのハイライトを箇条書きで取得したりするために使用できます。
ステップ 4: ボーナス機能
ローカル データ フォルダーに加えて、RTX とのチャットを使用して YouTube ビデオを分析できます。これを行うには、[データセット] で、フォルダー パスを YouTube URL に変更します。
分析したい YouTube URL をコピーし、ドロップダウン メニューの下に貼り付けます。それなら聞いてください!

RTX の YouTube ビデオ分析とのチャットは非常に優れており、正確な情報が提供されたため、調査や迅速な分析などに便利です。
Nvidia の RTX チャットは役に立ちますか?
ChatGPT は RAG 機能を提供します。一部のローカル AI チャットボットのシステム要件は大幅に低くなります。では、RTX を使用した Nvidia Chat は使用する価値がありますか?
答えは「はい」です! RTX とのチャットは、競合にもかかわらず使用する価値があります。
RTX で Nvidia Chat を使用する最大のセールス ポイントの 1 つは、ファイルをサードパーティのサーバーに送信せずに RAG を使用できることです。オンライン サービスを通じて GPT をカスタマイズすると、データが公開される可能性があります。ただし、Chat with RTX はインターネット接続なしでローカルで実行されるため、Chat with RTX で RAG を使用すると、機密データは安全であり、PC 上でのみアクセスできることが保証されます。
Mistral 7B を実行しているローカルで実行されている他の AI チャットボットと同様に、Chat with RTX のパフォーマンスが向上し、高速になります。パフォーマンス向上の大部分はハイエンド GPU の使用によるものですが、Nvidia TensorRT-LLM と RTX アクセラレーションの使用により、チャットに最適化された LLM を実行する他の方法と比較して、RTX とのチャットでの Mistral 7B の実行が高速になりました。
現在使用している Chat with RTX バージョンはデモであることに注意してください。 Chat with RTX の今後のリリースでは、より最適化され、パフォーマンスが向上する可能性があります。
RTX 30 または 40 シリーズ GPU がない場合はどうすればよいですか?
RTX とのチャットは、インターネット接続を必要とせずにローカルで LLM を実行する簡単、高速、安全な方法です。 LLM またはローカルでの実行にも興味があるが、RTX 30 または 40 シリーズ GPU を持っていない場合は、ローカルで LLM を実行する他の方法を試すことができます。最も人気のあるものの 2 つは、GPT4ALL と Text Gen WebUI です。 LLM をローカルで実行するプラグアンドプレイ エクスペリエンスが必要な場合は、GPT4ALL を試してください。ただし、もう少し技術的な傾向がある場合は、Text Gen WebUI を通じて LLM を実行すると、より優れた微調整と柔軟性が得られます。
以上がコンピューター上で RTX AI チャットボットを使用して Nvidia のチャットを使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。