終了したばかりの Worldwide Developers Conference で、Apple は、iOS 18、iPadOS 18、macOS Sequoia に深く統合された新しいパーソナライズされたインテリジェンス システムである Apple Intelligence を発表しました。

Apple+ Intelligence は、ユーザーの日常業務向けに設計されたさまざまな高度にインテリジェントな生成モデルで構成されています。 Apple が最近更新したブログで、そのうちの 2 つのモデルについて詳しく説明しました。
これら 2 つの基本モデルは Apple の生成モデル ファミリーの一部であり、Apple は近い将来、このモデル ファミリーに関する詳細情報を共有すると述べています。
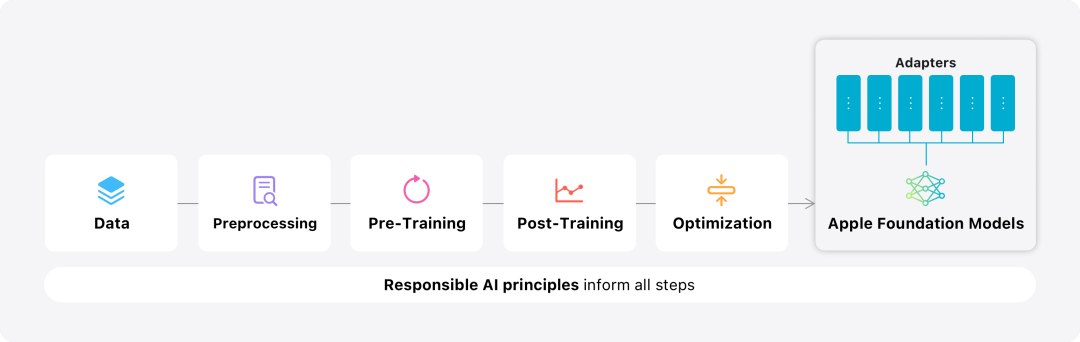
このブログでは、Apple は、高性能、高速、エネルギー効率の高いモデルを開発する方法、特定のユーザーのニーズに合わせてアダプターを微調整する方法、およびモデルを評価する方法を紹介することに多くの時間を費やしています。偶発的な怪我の観点からパフォーマンスを助け、回避するため。 Apple 基本モデルのモデリング概要
これは Apple 2023 年にリリースされたオープンソース プロジェクトです。このフレームワークは JAX と XLA に基づいて構築されているため、ユーザーはクラウドおよびオンプレミスの TPU や GPU を含む、さまざまなハードウェアおよびクラウド プラットフォーム上でモデルを効率的かつスケーラブルにトレーニングできます。さらに、Apple はデータ並列処理、テンソル並列処理、シーケンス並列処理、FSDP などの手法を使用して、データ、モデル、シーケンスの長さなどの複数の次元に沿ってトレーニングをスケールします。
基本モデルをトレーニングする際、Apple は承認されたデータを使用します。これには、特定の機能を強化するために特別に選択されたデータと、Apple の Web クローラー AppleBot によってパブリック ネットワークから収集されたデータが含まれます。 Web コンテンツの発行者は、データ使用制御を設定することで、Web コンテンツを Apple Intelligence のトレーニングに使用しないように選択できます。 Apple は、基本モデルをトレーニングする際にユーザーの個人データを決して使用しません。プライバシーを保護するために、フィルターを使用して、インターネット上で公開されているクレジット カード番号などの個人を特定できる情報を削除します。さらに、下品な言葉やその他の低品質のコンテンツがトレーニング データ セットに組み込まれる前に除外されます。これらのフィルタリング手段に加えて、Apple はデータ抽出と重複排除を実行し、モデルベースの分類子を使用してトレーニング用の高品質ドキュメントを識別して選択します。
Apple は、データ品質がモデルにとって重要であることに気づき、トレーニング プロセスにハイブリッド データ戦略、つまり手動で注釈を付けたデータと合成データを採用しました。包括的なデータ管理とフィルタリング手順を実施しました。 Apple はトレーニング後の段階で 2 つの新しいアルゴリズムを開発しました: (1) 「教師委員会」による拒否サンプリング微調整アルゴリズム、(2) ミラー降下戦略の最適化とリーブワンアウトを使用した人間のフィードバックからの強化利点推定学習 (RLHF) アルゴリズム。これら 2 つのアルゴリズムにより、モデルの命令追従品質が大幅に向上します。 Apple は、生成されたモデル自体の高いパフォーマンスを確保することに加えて、さまざまな革新的なテクノロジーを使用してデバイスとプライベート クラウド上のモデルを最適化し、速度とパフォーマンスを向上させます。効率 。特に、最初のトークン (単一の文字または単語の基本単位) と後続のトークンを生成する際のモデルの推論プロセスに多くの最適化を行い、モデルの高速な応答と効率的な動作を確保しました。
Apple は、効率を向上させるために、デバイス側モデルとサーバー モデルの両方でグループ クエリ アテンション メカニズムを使用しています。メモリ要件と推論コストを削減するために、マッピング中に重複しない共有の入力および出力語彙埋め込みテーブルが使用されます。デバイス側モデルの語彙数は 49,000、サーバー モデルの語彙数は 100,000 です。 デバイス側の推論では、Apple は、必要なメモリ、消費電力、パフォーマンス要件を満たすことができる重要な最適化テクノロジである低ビット パレタイゼーションを使用しています。モデルの品質を維持するために、Apple は、非圧縮モデルと同じ精度を達成するために、ハイブリッド 2 ビットと 4 ビットの構成戦略 (重みあたり平均 3.5 ビット) を組み合わせた LoRA アダプターを使用した新しいフレームワークも開発しました。
さらに、Apple は、対話型モデルのレイテンシーおよび電力分析ツールである Talaria、アクティベーション量子化および埋め込み量子化を使用し、Neural Engine 上で効率的なキー値 (KV) キャッシュの更新を実装する方法を開発しました。
この一連の最適化により、iPhone 15 Pro では、モデルがプロンプトワードを受信したときに、プロンプトワードを受信してから最初のトークンを生成するまでに必要な時間が約 0.6 ミリ秒と非常に短いことがわかります。モデルは 1 秒あたり 30 トークンの速度で非常に高速に応答を生成していることがわかります。
Apple は、ユーザーの日常のアクティビティに合わせて基本モデルを微調整し、当面のタスクに合わせて動的に特化できます。
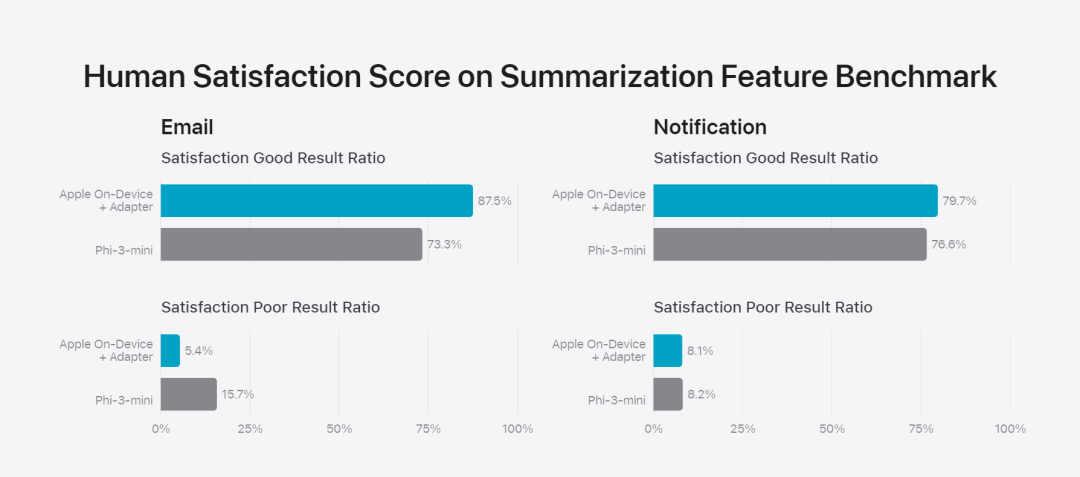
研究チームは、事前トレーニングされたモデルのさまざまな層に接続できる小さなニューラル ネットワーク モジュールであるアダプターを使用して、特定のタスクに合わせてモデルを微調整します。具体的には、研究チームは、ポイントワイズフィードフォワードネットワークの注意行列、注意投影行列、および全結合層を調整しました。 アダプター層を微調整するだけで、事前トレーニングされた基本モデルの元のパラメーターは変更されず、モデルの一般的な知識が維持され、特定のタスクをサポートするようにアダプター層が調整されます。 図 2: アダプターは、共通の基本モデルに重ねられたモデルの重みの小さなコレクションです。これらは動的にロードおよび交換できるため、基礎となるモデルが当面のタスクに動的に特化できるようになります。 Apple Intelligence には、特定の機能に合わせてそれぞれが微調整された広範なアダプターのセットが含まれています。これは、基本モデルの機能を拡張する効率的な方法です。 研究チームは、約 30 億のパラメータを持つデバイス モデルの場合、通常、16 ビットを使用して 10 メガバイトを必要とします。アダプター モデルは、動的にロードし、一時的にメモリーにキャッシュし、交換することができます。これにより、メモリを効率的に管理し、オペレーティング システムの応答性を確保しながら、基礎となるモデルが現在のタスクに動的に特化できるようになります。 アダプターのトレーニングを容易にするために、Apple は、基礎となるモデルまたはトレーニング データが更新されたときにアダプターを迅速に再トレーニング、テスト、デプロイできる効率的なインフラストラクチャを作成しました。 人間による評価の結果は製品のユーザーエクスペリエンスと高い相関があるため、Apple はモデルのベンチマークを行う際に人間による評価に重点を置いています。 製品固有の要約機能を評価するために、研究チームは、ユースケースごとに注意深くサンプリングされた 750 件の回答セットを使用しました。評価データセットは、製品機能が本番環境で直面する可能性のある入力の多様性を強調しており、さまざまなコンテンツ タイプと長さの単一ドキュメントと積み重ねられたドキュメントの階層化された組み合わせが含まれています。実験の結果、アダプターを備えたモデルは同様のモデルよりも優れたサマリーを生成できることがわかりました。 責任ある開発の一環として、Apple は要約に内在する特定のリスクを特定し、評価します。たとえば、要約では重要なニュアンスやその他の詳細が削除されることがあります。しかし、研究チームは、ダイジェスト アダプターが標的となった敵対的サンプルの 99% 以上に含まれる機密コンテンツを増幅しないことを発見しました。図 3: 抽象的なユースケースにおける「良い」と「違い」の割合。 研究チームは、ベースモデルとアダプターによってサポートされる特定の機能を評価することに加えて、オンデバイスモデルとサーバーベースのモデルの一般的な機能も評価しました。具体的には、研究チームは、ブレインストーミング、分類、クローズド Q&A、コーディング、抽出、数学的推論、オープン Q&A、リライト、セキュリティ、要約、およびライティング タスクをカバーする、現実世界のプロンプトの包括的なセットを使用してモデルの機能をテストしました。
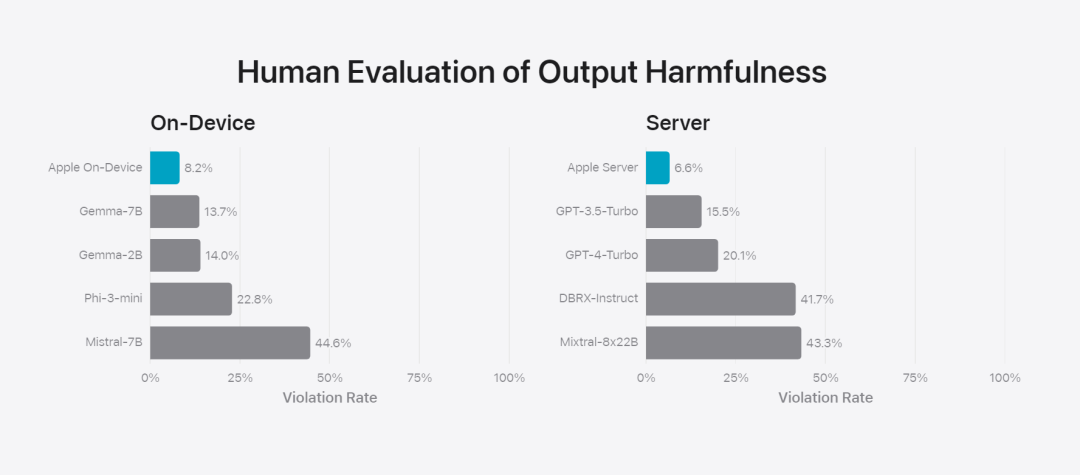
研究チームは、このモデルをオープンソース モデル (Phi-3、Gemma、Mistral、DBRX) および同等規模の商用モデル (GPT-3.5-Turbo、GPT-4-Turbo) と比較しました。 Apple のモデルは、ほとんどの競合モデルと比較して人間の評価者に好まれていることがわかりました。たとえば、最大 3B のパラメータを持つ Apple のオンデバイス モデルは、Phi-3-mini、Mistral-7B、Gemma-7B などの大型モデルよりも優れたパフォーマンスを発揮します。サーバー モデルは、DBRX-Instruct、Mistral-8x22B、GPT-3.5 -Turbo と競合します。比較しても遜色なく、同時に非常に効率的です。ベース 図 4: Apple 基本モデルと比較モデルの評価における回答率の割合。 研究チームはまた、別の敵対的プロンプトのセットを使用して、有害なコンテンツ、デリケートなトピック、事実に関するモデルのパフォーマンスをテストし、人間の評価者によって評価されたモデル違反率を測定し、数値が低いほど優れています良い。敵対的なプロンプトに直面しても、オンデバイス モデルとサーバー モデルは両方とも堅牢であり、オープンソース モデルや商用モデルよりも違反率が低くなります。、 図 5: 有害なコンテンツ、デリケートなテーマ、事実の割合 (低いほど良い)。 Apple のモデルは、敵対的なプロンプトに直面した場合に非常に堅牢です。 大規模な言語モデルの幅広い機能を考慮して、Apple は、モデルのセキュリティをさらに評価するために、手動および自動のレッドチームで社内外のチームと積極的に取り組んでいます。
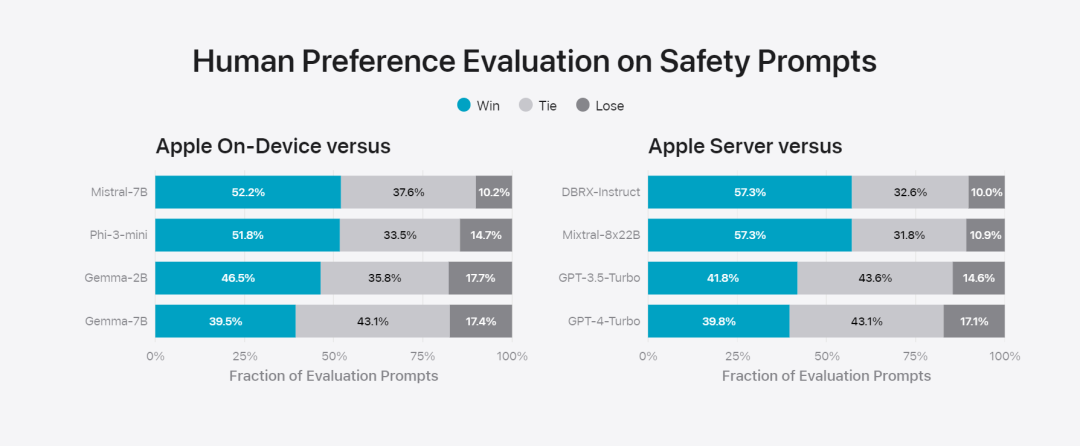
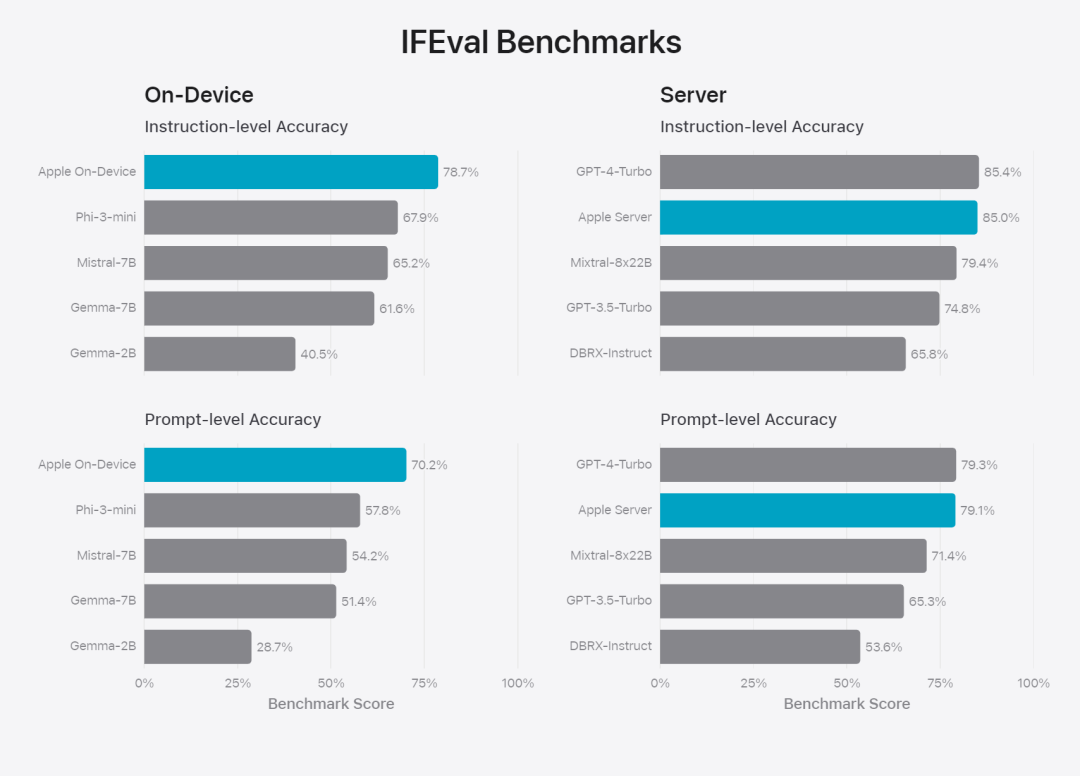
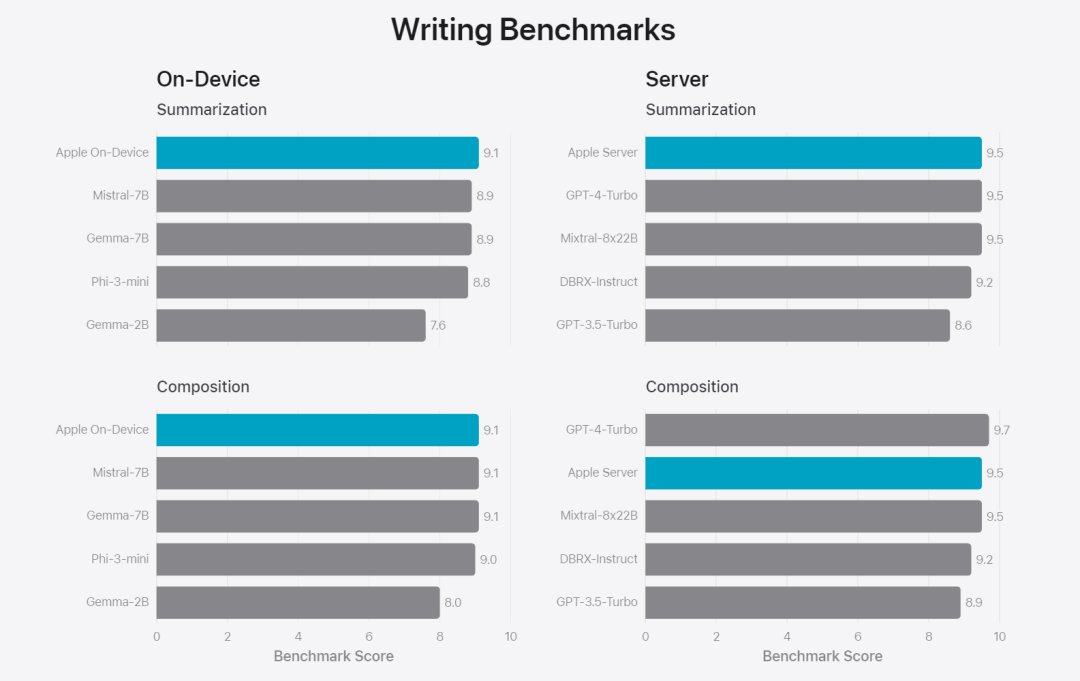
図 6: セキュリティ プロンプトに関して、Apple の基本モデルと同様のモデルを並行して評価した場合の優先回答の割合。人間の評価者は、Apple の基本モデルの応答がより安全でより役立つと判断しました。 モデルをさらに評価するために、研究チームは命令トレース評価 (IFEval) ベンチマークを使用して、その命令トレース機能を同様のサイズのモデルと比較しました。結果は、オンデバイス モデルとサーバー モデルの両方が、同じ規模のオープンソース モデルや商用モデルよりも詳細な指示に従っていることを示しています。ベース 図 7: Apple の基本モデルと同様のスケール モデルの命令追跡機能 (IFEVAL ベンチマークを使用)。 Apple は、さまざまな書き込み命令を含むモデルの書き込み能力も評価しました。 最後に、Apple Intelligence の背後にあるテクノロジーを紹介する Apple のビデオを見てみましょう。
参考リンク:https://machinelearning.apple.com/research/introducing-apple-foundation-models以上がApple のインテリジェンスを支えるモデルが発表: 3B モデルは Gemma-7B よりも優れており、サーバー モデルは GPT-3.5-Turbo に匹敵しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。