
ホームページ >テクノロジー周辺機器 >AI >LeCun の新作: 階層化ワールド モデル、データ駆動型ヒューマノイド ロボット制御
LeCun の新作: 階層化ワールド モデル、データ駆動型ヒューマノイド ロボット制御

- PHPzオリジナル
- 2024-06-13 11:37:171042ブラウズ
大型モデルの知的な恩恵により、人型ロボットが新しいトレンドになりました。
SF映画に登場する「自分が人間ではないことが分かる」ロボットが近づいてきているようです。
しかし、ロボット、特に人型ロボットが人間のように考え、行動することは依然として工学的に難しい問題です。
例として、強化学習を使用してトレーニングを行うと、次のように発展する可能性があります: 理論的には問題はなく(報酬メカニズムに従い)、目標は次のようになります。階段を上るということは達成されましたが、そのプロセスが比較的抽象的であることを除けば、ほとんどの人間の行動パターンと同じではないかもしれません。
 ロボットが人間のように「自然に」行動することが難しい理由は、観察・行動空間の高次元性と、二足歩行の形態が本来持つ不安定性によるものです。
ロボットが人間のように「自然に」行動することが難しい理由は、観察・行動空間の高次元性と、二足歩行の形態が本来持つ不安定性によるものです。
これに関して、LeCun が参加した研究は、データ駆動型に基づいた新しいソリューションを提供しました。 Paper Address:https://arxiv.org/pdf/2405.18418
Projectはじめに:https://nicklashansen.com/rlpuppeteer

もちろん、問題を起こしに来た一部のネチズンは、「前の方が面白そうだった」と言いました。
この研究では、研究者は、単純化する仮定、報酬設計、またはスキルプリミティブを一切使用せずに、強化学習に基づいた高度なデータ駆動型の視覚的な全身ヒューマノイド制御アプローチを探索します。

オープンソースコード: https://github.com/nicklashansen/puppeteer

高次元の制御された階層的世界モデル
物理世界における汎用エージェントの学習と訓練は、常に AI 分野の研究目標の 1 つです。 
人型ロボットは、全身制御と知覚を統合することでさまざまなタスクを実行できるため、多機能プラットフォームとして際立っています。
しかし、私たちのような先進的な動物を模倣する代償は依然として非常に高いです。
 たとえば、下の写真では、穴に足を踏み入れないようにするために、人型ロボットは、近づいてくる床の隙間の位置と長さを正確に感知すると同時に、体の動きを注意深く調整する必要があります。それぞれのギャップを越えるのに十分な勢いと範囲があります。
たとえば、下の写真では、穴に足を踏み入れないようにするために、人型ロボットは、近づいてくる床の隙間の位置と長さを正確に感知すると同時に、体の動きを注意深く調整する必要があります。それぞれのギャップを越えるのに十分な勢いと範囲があります。
Puppeteer は、2022 年に LeCun によって提案された階層型 JEPA ワールド モデルに基づくデータ駆動型 RL 手法です。
それは 2 つの異なるエージェントで構成されます。1 つは知覚と追跡を担当し、関節レベルの制御を通じて参照モーションを追跡します。もう 1 つは、低次元の参照モーションを合成することで下流のタスクを実行することを学習します。以前の追跡サポート。
Puppeteer は、モデルベースの RL アルゴリズム TD-MPC2 を使用して、2 つの異なるステージで 2 人のエージェントを独立してトレーニングします。
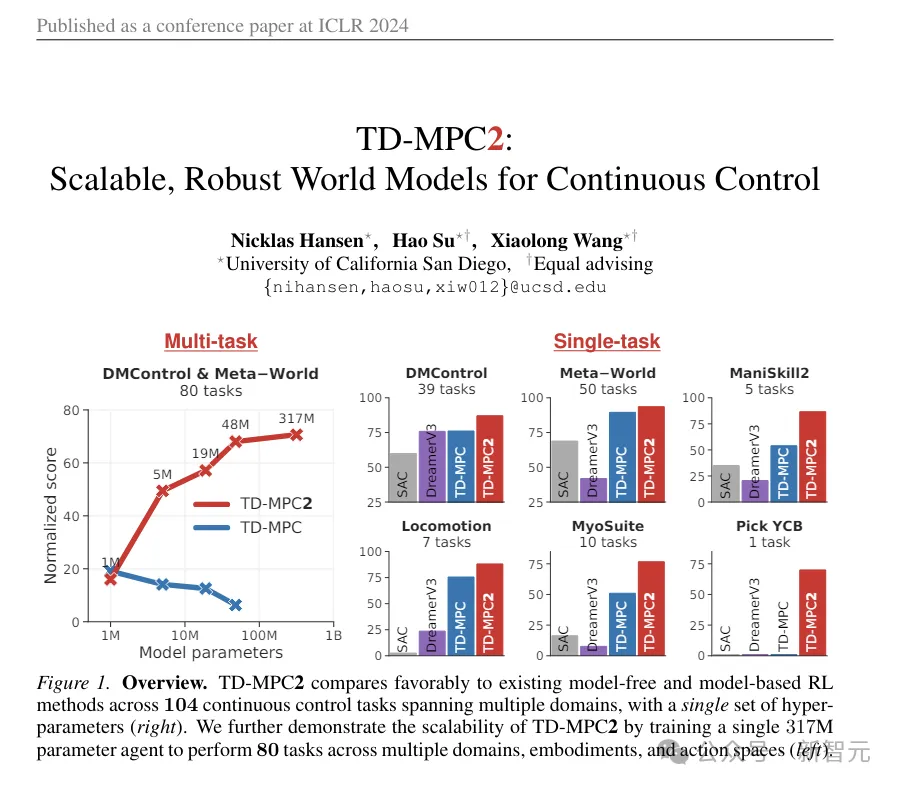
(追伸:このTD-MPC2は記事冒頭で比較に使用したアニメーション画像です。少し抽象的ですが、実はこれは今年のICLRに掲載された前のSOTAであり、最初の作品はこの記事の最初の作業でもあります。)
最初の段階では、モーションを物理的に実行可能なアクションに変換するための参照として既存の人間のモーション キャプチャ データを使用して、追跡用のワールド モデルが事前トレーニングされます。 。このエージェントは保存して、すべての下流タスクで再利用できます。
第 2 段階では、視覚的な観察を入力として受け取り、指定された下流タスクに従って別のエージェントによって提供される参照モーションを出力として統合する、パペット ワールド モデルがトレーニングされます。
このフレームワークは非常に単純に見えます。2 つの世界モデルはアルゴリズム的には同じで、入力/出力が異なるだけであり、他の追加機能なしで RL を使用してトレーニングされます。
従来の階層型 RL 設定とは異なり、「Puppet」はターゲットの埋め込みではなく、エンドエフェクター ジョイントの幾何学的位置を出力します。
これにより、追跡を担当するエージェントがタスク間で簡単に共有および汎用化できるようになり、全体的なコンピューティングスペースが節約されます。
研究方法
研究者らは、タプル(S、A、T、R、γ)に基づくマルコフ決定プロセス(MDP)によって制御される強化学習問題として、視覚的な全身ヒューマノイド制御をモデル化しました。 、Δ) は特徴です。
ここで、S は状態、A はアクション、T は環境遷移関数、R はスカラー報酬関数、γ は割引係数、Δ は終了条件です。
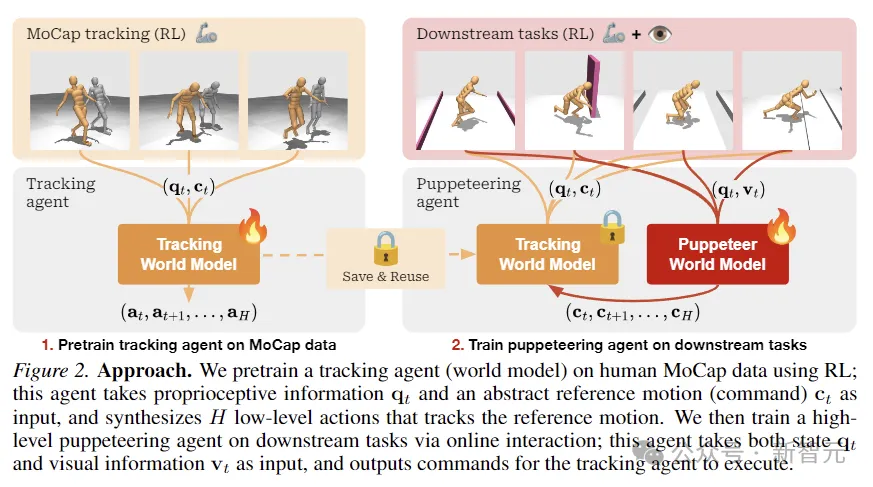
上の図に示すように、研究者らは RL を使用して、人間の MoCap データで追跡エージェントを事前トレーニングしました。これは、固有受容情報と抽象的な参照モーション入力を取得し、低レベルのアクションを合成するために使用されました。参照モーションを追跡します。
次に、オンライン対話を通じて、下流タスクを担当する高度なパペット エージェントがトレーニングされ、パペットはステータスと視覚情報の入力を受け取り、追跡エージェントが実行するコマンドを出力します。
TD-MPC2
TD-MPC2 は、環境相互作用から潜在デコーダーフリーの世界モデルを学習し、学習したモデルを計画に使用します。
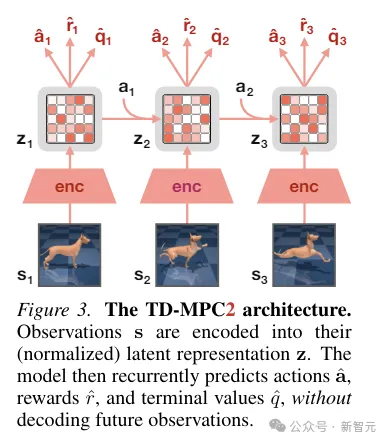
世界モデルのすべてのコンポーネントは、元の観測値をデコードすることなく、結合埋め込み予測、報酬予測、時間差損失の組み合わせを使用してエンドツーエンドで学習されます。
推論中、TD-MPC2 はモデル予測制御 (MPC) フレームワークに従い、ローカル軌道最適化のための導関数フリー (サンプリングベース) オプティマイザーとしてモデル予測パス積分 (MPPI) を使用します。
計画をスピードアップするために、TD-MPC2 はモデルフリー戦略を事前に学習して、サンプリング プログラムを事前に開始します。
両方のエージェントはアルゴリズム的に同一であり、どちらも次の 6 つのコンポーネントで構成されています:

実験
方法の有効性を評価するために、研究者たちは新しい方法を提案しました。タスクスイートではシミュレートされた 56 のコンポーネントが使用されます。 -視覚的な全身制御のための自由度ヒューマノイド ロボットには、SAC、DreamerV3、TD-MPC2 などの合計 8 つの困難なタスクが含まれています。
8つのタスクは下の図に示されており、5つの視覚条件による全身運動タスクと、視覚入力を伴わない別の3つのタスクが含まれます。
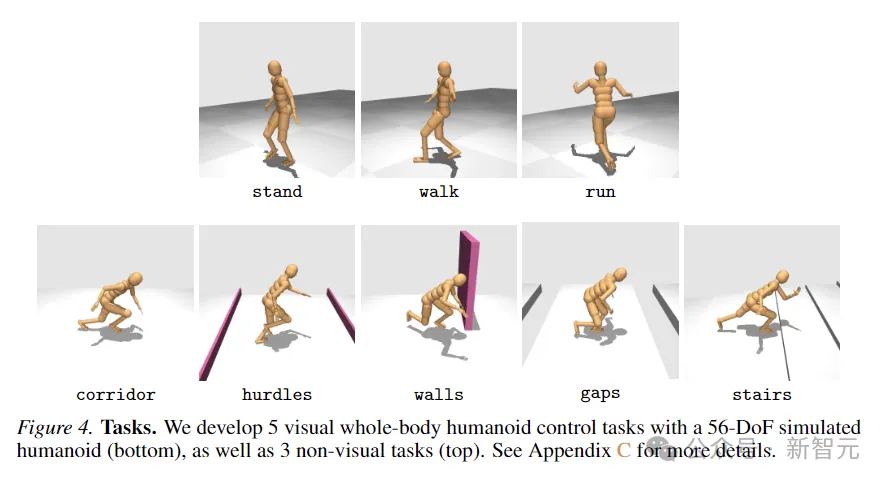
クエストは高度なランダム性を持って設計されており、廊下を走る、障害物や隙間を飛び越える、階段を上る、壁を迂回するなどが含まれます。
5 つの視覚制御タスクはすべて、線形前進速度に比例する報酬関数を使用しますが、非視覚タスクは任意の方向の変位に報酬を与えます。
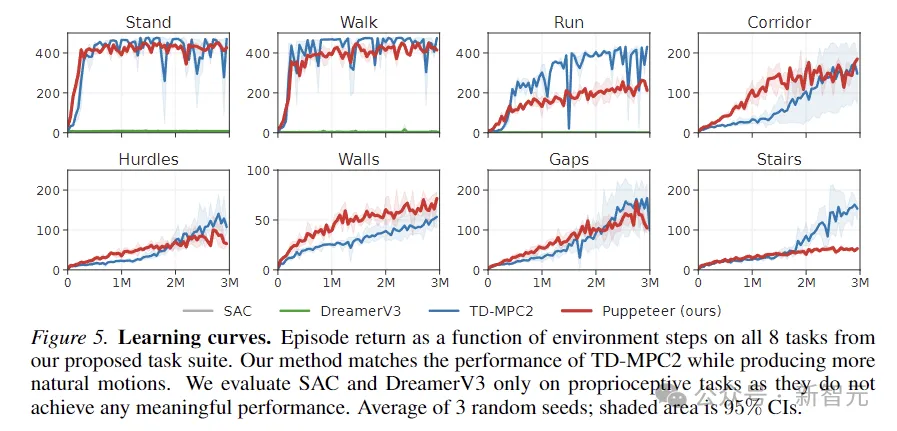
上の図は学習曲線をプロットしたものです。結果は、SAC と DreamerV3 がこれらのタスクで有意義なパフォーマンスを達成できないことを示しています。
TD-MPC2 は、報酬の点では私たちのメソッドと同等のパフォーマンスを発揮しますが、不自然な動作を生成します (下の画像の抽象的なアクションを参照)。

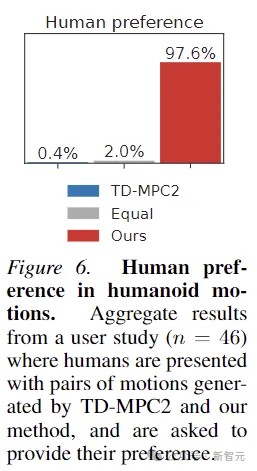
さらに、この記事では、Puppeteer によって生成された動きが実際により「自然」であることを証明するために、46 人の参加者を対象とした人間の好みの実験も実施しました。このメソッドによって生成される動き。
以上がLeCun の新作: 階層化ワールド モデル、データ駆動型ヒューマノイド ロボット制御の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。