
ホームページ >テクノロジー周辺機器 >AI >レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ
レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-11 17:29:581188ブラウズ
上記の内容と著者の個人的な理解
最近、深層学習技術の発展と進歩により、大規模な基盤モデルが自然言語処理とコンピュータービジョンの結果で大きな成果を上げています。自動運転における基本モデルの応用にも大きな発展の可能性があり、シナリオの理解と推論を向上させることができます。
- 豊富な言語と視覚データの事前トレーニングを通じて、基本モデルは自動運転シナリオのさまざまな要素を理解して解釈し、推論を実行して、運転の意思決定と計画のための言語とアクションのコマンドを提供します。
- 基本モデルは、運転シナリオの理解に基づいてデータ拡張を実現でき、通常の運転やデータ収集では遭遇する可能性が低い、まれな実行可能なシナリオをロングテール分布で提供するために使用され、自動運転システムの精度の向上を実現します。信頼性の目的。
- 基本モデルを適用するためのもう 1 つのシナリオは、物理法則と動的なものを理解する能力を実証する世界モデルです。自己教師あり学習パラダイムを使用して大量のデータから学習することで、ワールド モデルは目に見えないが信頼できる運転シーンを生成し、動的な物体の動作予測と運転戦略のオフライン トレーニング プロセスの強化を促進できます。
この記事では、主に自動運転分野における基本モデルの適用について概説し、自動運転モデルにおける基本モデルの適用、データ拡張における基本モデルの適用、およびデータ拡張における基本モデルの適用に基づいて説明します。ベーシックモデルの世界モデルから自動運転までの側面で展開。 自動運転モデルに関しては、基本モデルを使用して、車両の認識、意思決定、制御などのさまざまな自動運転機能を実装できます。基本モデルを通じて、車両は周囲の環境に関する情報を取得し、それに応じた決定を下し、動作を制御できます。 データ強化に関しては、基本モデルを使用してデータを強化できます
この記事のリンク: https://arxiv.org/pdf/2405.02288
自動運転モデル
言語と言語に基づいた人間のような運転視覚基本モデル
自動運転において、言語と視覚の基本モデルは、運転シナリオにおける自動運転モデルの理解と推論を強化することで、人間らしい自動運転を実現できます。以下の図は、言語と視覚に基づく基本モデルによる運転シーンの理解と、言語に基づく指示と運転行動の推論を示しています。
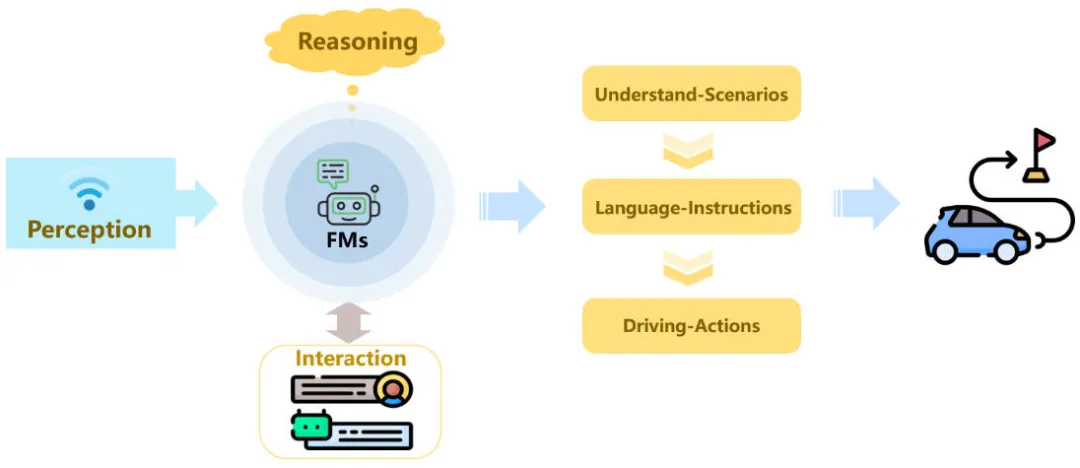
基本モデルは自動運転モデルのパラダイムを強化します
現在の多くの研究では、現在の環境の全体的な知覚的理解を取得した後、言語と視覚機能が運転シーンのモデルの理解を効果的に強化できることが証明されています。モデルは、「前方に赤信号があります。速度を落としてゆっくり運転してください」、「前方に交差点があります、歩行者に注意してください」、およびその他の関連する言語コマンドなどの一連の言語コマンドを与えます。運転中の車は、関連する言語コマンドに従って最終的な運転動作を実行できます。
近年、学術界と産業界は、GPT の言語知識を自動運転の意思決定プロセスに組み込みました。言語コマンドの形で自動運転のパフォーマンスを向上させ、大型モデルの自動運転への適用を促進します。大型モデルが実際に車両側に展開されることが期待されることを考慮すると、最終的には計画または制御の指示に該当する必要があり、基本モデルは最終的に動作状態レベルから自動運転を許可する必要があります。一部の学者は予備的な調査を行っていますが、開発の余地はまだたくさんあります。さらに重要なことは、一部の学者は、大規模な言語モデルに基づいて軌道を直接出力し、制御コマンドを通じてそれらを実装する、GPT と同様の方法による自動運転モデルの構築を研究していることです。関連する研究を次の表にまとめます。
エンドツーエンドの自動運転に事前トレーニングされたバックボーンネットワークを使用します
上記の関連コンテンツの中心的なアイデアは、自動運転の意思決定の解釈可能性を向上させ、シーンの理解と分析を強化し、自動運転システムの計画や制御をガイドします。過去の期間にわたって、事前トレーニングされたモデルのバックボーン ネットワークをさまざまな方法で最適化するために多くの作業が行われ、非常に良い結果が得られました。したがって、自動運転における基本モデルの応用をより包括的に要約するために、事前トレーニングされたバックボーン ネットワークと非常に良好な結果を達成した研究を要約してレビューします。以下の図は、エンドツーエンドの自動運転の全体的なプロセスを示しています。

事前訓練されたバックボーンネットワークに基づくエンドツーエンドの自動運転システムのフローチャート
エンドツーエンドの自動運転のプロセス全体において、生データから低レベルの情報を抽出することで、その後のモデルのパフォーマンスの可能性がある程度決まり、優れた事前トレーニング バックボーンにより、モデルの特徴学習機能が強化されます。 ResNet や VGG などの事前トレーニング済み畳み込みネットワークは、エンドツーエンド モデルの視覚的特徴抽出に最も広く使用されているバックボーン ネットワークです。これらの事前トレーニング済みネットワークは通常、一般化された特徴を抽出するタスクとしてオブジェクト検出またはセグメンテーションを使用してトレーニングされ、それらが達成するパフォーマンスは多くの研究で検証されています。
さらに、初期のエンドツーエンドの自動運転モデルは、主にさまざまな種類の畳み込みニューラル ネットワークに基づいており、模倣学習または強化学習を通じて完成されました。最近のいくつかの研究では、Transformer ネットワーク構造を備えたエンドツーエンドの自動運転システムの構築が試みられ、Transfuser、FusionAD、UniAD などの研究でも比較的良好な結果が得られています。
データ強化
ディープラーニングテクノロジーのさらなる開発と、基礎となるネットワークアーキテクチャのさらなる改善とアップグレードにより、事前トレーニングと微調整を備えた基本モデルは、ますます強力なパフォーマンスを示しています。 GPT に代表される基本モデルにより、学習パラダイムのルールからデータ駆動型アプローチへの大規模モデルの変換が可能になりました。モデル学習における重要なリンクとしてのデータの重要性は、かけがえのないものです。自動運転モデルのトレーニングとテストでは、モデルがさまざまな道路や交通のシナリオを十分に理解し、意思決定できるようにするために、大量のシーン データが使用されます。自動運転が直面するロングテールの問題は、未知のエッジ シナリオが無限に存在するという事実でもあり、そのためモデルの一般化能力が決して十分ではなく、その結果、パフォーマンスが低下することになります。
データ拡張は、自動運転モデルの一般化能力を向上させるために重要です。データ拡張の実装では、2 つの側面を考慮する必要があります
- 一方で: 自動運転モデルに提供されるデータが十分に多様かつ広範囲になるように、大規模なデータを取得する方法
- もう一方で: 取得方法できるだけ多くのデータ 高品質のデータにより、自動運転モデルのトレーニングとテストに使用されるデータが正確かつ信頼できるものになります
したがって、関連研究作業では、主に上記の 2 つの側面から関連する技術研究を実行します。既存のデータセットを活用し、運転シナリオにおけるデータ特性を強化します。 2 つ目は、シミュレーションを通じてマルチレベルの運転シナリオを生成することです。
自動運転データセットの拡張
既存の自動運転データセットは、主にセンサーデータを記録し、データにラベルを付けることによって取得されます。この方法で取得されるデータ特徴は、通常、非常に低レベルであり、データセットの規模も比較的貧弱であり、自動運転シナリオの視覚特徴空間としては完全に不十分です。言語モデルによって表される基本モデルの高度な意味理解、推論、解釈機能は、自動運転データセットの強化と拡張のための新しいアイデアと技術的アプローチを提供します。基礎となるモデルの高度な理解、推論、解釈機能を活用してデータセットを拡張すると、自動運転システムの説明可能性と制御をより適切に評価できるようになり、それによって自動運転システムの安全性と信頼性が向上します。
運転シーンを生成する
運転シーンは自動運転にとって非常に重要です。さまざまな走行シーンのデータを取得するには、車両のセンサーのみに頼ってリアルタイムに収集すると膨大なコストがかかり、一部のエッジシーンでは十分なシーンデータを取得することが困難です。シミュレーションによる現実的な運転シーンの生成は、多くの研究者の注目を集めています。交通シミュレーションの研究は、主にルールベースとデータ駆動の 2 つのカテゴリに分類されます。
- ルールベースのアプローチ: 事前に定義されたルールを使用しますが、複雑な運転シナリオを説明するには不十分な場合が多く、シミュレートされた運転シナリオはよりシンプルでより一般的です
- データドリブンのアプローチ: 運転データを使用してモデルをトレーニングします。そこから継続的に学び、適応していきます。しかし、データ駆動型の方法では通常、トレーニング用に大量のラベル付きデータが必要となるため、技術の発展に伴い、現在のデータ生成方法はルールベースの方法からデータ生成方法に徐々に変化してきました。駆動方式。さまざまな複雑で危険な状況を含む運転シナリオを効率的かつ正確にシミュレーションすることで、モデル学習に大量のトレーニング データが提供され、自動運転システムの汎化能力を効果的に向上させることができます。同時に、生成された運転シナリオを使用して、さまざまな自動運転システムやアルゴリズムを評価し、システムのパフォーマンスをテストおよび検証することもできます。次の表は、さまざまなデータ拡張戦略をまとめたものです。
さまざまなデータ拡張戦略の概要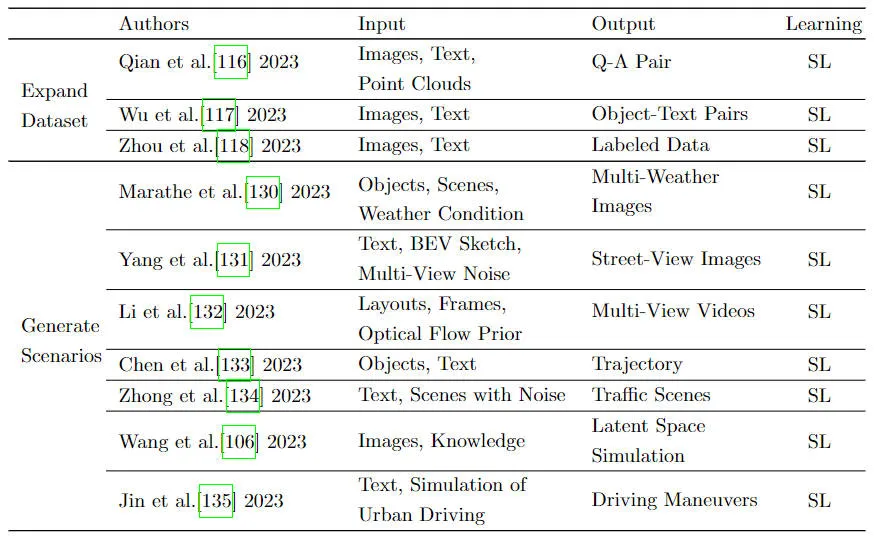
ワールドモデル
ワールドモデルは、それが動作する環境の全体的な理解または表現を含む人工知能モデルとみなされます。モデルは環境をシミュレートして予測や決定を行うことができます。最近の文献では、強化学習の文脈で「ワールド モデル」という用語が言及されています。この概念は、運転環境のダイナミクスを理解して解明できるため、自動運転アプリケーションでも注目を集めています。ワールド モデルは、強化学習、模倣学習、深層生成モデルと密接に関連しています。ただし、強化学習や模倣学習でワールド モデルを利用するには、通常、適切にラベル付けされたデータが必要であり、SEM2 や MILE などの手法は教師ありパラダイムで実行されます。同時に、ラベル付きデータの制限に基づいて、強化学習と教師なし学習を組み合わせる試みも行われています。自己教師あり学習との密接な関係により、深層生成モデルの人気が高まっており、多くの研究が提案されています。以下の図は、ワールドモデルを使用して自動運転モデルを強化する全体のフローチャートを示しています。
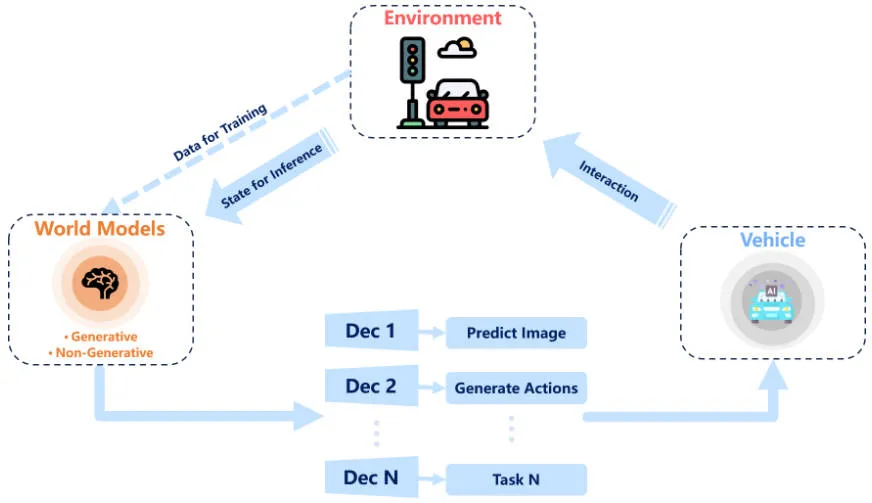
ワールドモデルの自動運転モデル強化の全体的なフローチャート
深い生成モデル
深い生成モデルには、通常、変分オートエンコーダー、敵対的生成ネットワーク、フローモデル、自己回帰モデルが含まれます。
- 変分オートエンコーダーは、オートエンコーダーと確率的グラフィカルモデルのアイデアを組み合わせて、データの基礎となる構造を学習し、新しいサンプルを生成します
- 敵対的生成ネットワークは、敵対的性質を利用するジェネレーターとディスクリミネーターの 2 つのニューラルネットワークで構成されますトレーニングは競合して強化します相互に相互作用し、最終的に実際のサンプルを生成するという目標を達成します
- フロー モデルは、一連の可逆変換を通じて単純な事前分布を複雑な事後分布に変換し、同様のデータ サンプルを生成します
- 自己回帰モデルはシーケンスの一種です 分析この方法は、シーケンス データ間の自己相関に基づいて、現在の観測と過去の観測の関係を記述します。モデル パラメーターの推定は、通常、最小二乗法と最尤推定を使用して行われます。拡散モデルは、純粋なノイズ データから段階的なノイズ除去プロセスを学習する典型的な自己回帰モデルです。強力な生成性能により、拡散モデルは現在のディープ生成モデルの中で新しい SOTA モデルです
生成方法
ディープ生成モデルの強力な能力に基づいて、ディープ生成モデルは運転を学習するためのワールドモデルとして使用されます自動運転を強化するためのシナリオは、徐々に研究のホットスポットになってきています。次に、自動運転における世界モデルとしての深層生成モデルの使用について検討します。画像データには非常に豊富な特徴情報が含まれているため、視覚は人間が世界に関する情報を取得する最も直接的かつ効果的な方法の 1 つです。これまでの多くの研究では、ワールド モデルを通じて画像生成のタスクを完了しており、ワールド モデルが画像データを十分に理解して推論できることを示しています。全体として、研究者らは画像データから世界に固有の進化の法則を学び、将来の状態を予測したいと考えている。自己教師あり学習と組み合わせて、ワールド モデルを使用して画像データから学習し、モデルの推論機能を完全に解放し、視覚領域で一般化された基本モデルを構築するための実現可能な方向性を提供します。以下の図は、ワールド モデルを使用したいくつかの関連作業の概要を示しています。
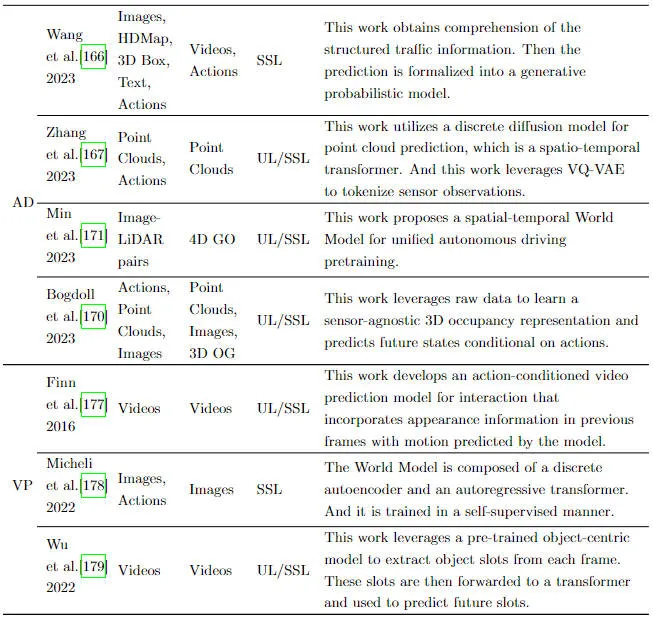
予測にワールドモデルを使用した研究の概要
非生成手法
生成ワールドモデルと比較して、LeCun は Joint Extraction and Prediction Architecture (JEPA) コンセプトを提案することでワールド モデルの違いを詳しく説明しました。これは、入力データに基づいて出力を直接予測せず、入力データを抽象空間でエンコードして最終的な予測を完了するため、非生成型の自己教師型アーキテクチャです。この予測方法の利点は、出力に関するすべての情報を予測する必要がなく、無関係な詳細を排除できることです。
JEPA は、エネルギー モデルに基づく自己教師あり学習アーキテクチャであり、世界がどのように機能するか、および高度に一般化された法則を観察して学習します。 JEPAは自動運転にも大きな可能性を秘めており、運転の仕組みを学ぶことで高品質な運転シナリオや運転戦略を生み出すことが期待されている。
結論
この記事では、自動運転アプリケーションにおける基本モデルの重要な役割について包括的に概要を説明します。この記事で調査した関連する研究成果の概要と結果から判断すると、さらに探求する価値のあるもう 1 つの方向性は、自己教師あり学習のための効果的なネットワーク アーキテクチャを設計する方法です。自己教師あり学習は、データ アノテーションの制限を効果的に突破し、モデルが大規模なデータを学習し、モデルの推論機能を完全に解放できるようにします。自己教師あり学習パラダイムの下で、さまざまなスケールの運転シーンデータを使用して自動運転の基本モデルを学習できれば、その一般化能力が大幅に向上すると期待されます。このような進歩により、より一般的な基本モデルが可能になる可能性があります。
つまり、基本モデルを自動運転に適用するには多くの課題がありますが、非常に広い応用範囲と開発の見通しを持っています。今後も自動運転に適用される基礎モデルの進展に注目していきます。
以上がレビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。