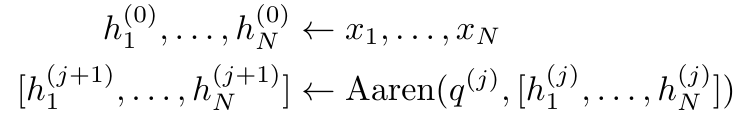シーケンス モデリングの進歩は、強化学習 (ロボット工学や自動運転など)、時系列分類 (金融詐欺検出や医療診断など) を含む幅広いアプリケーションで重要な役割を果たすため、非常に大きな影響を与えています。 ここ数年、Transformer の出現により、シーケンス モデリングにおける大きな進歩が見られました。これは主に、Transformer が GPU 並列処理を活用できる高性能アーキテクチャを提供しているという事実によるものです。 ただし、Transformer は、主にメモリとコンピューティング要件の 2 次拡張により、推論中の計算オーバーヘッドが高く、低リソース環境 (例: モバイルや組み込みデバイス) でのアプリケーションが制限されます。 KV キャッシュなどの手法を採用して推論効率を向上させることもできますが、Transformer は、(1) トークンの数に応じて直線的に増加するメモリ、および (2) 以前のすべてのトークンをモデル。この問題は、長いコンテキスト (つまり、多数のトークン) を持つ環境では、Transformer の推論にさらに影響します。 この問題を解決するために、カナダ王立銀行 AI 研究所 Borealis AI とモントリオール大学の研究者は、論文「RNN としての注意」で解決策を提供しました。チューリング賞受賞者のヨシュア・ベンジオ氏が著者欄に登場していることを発見したことは言及しておく価値があります。
- 論文のアドレス: https://arxiv.org/pdf/2405.13956
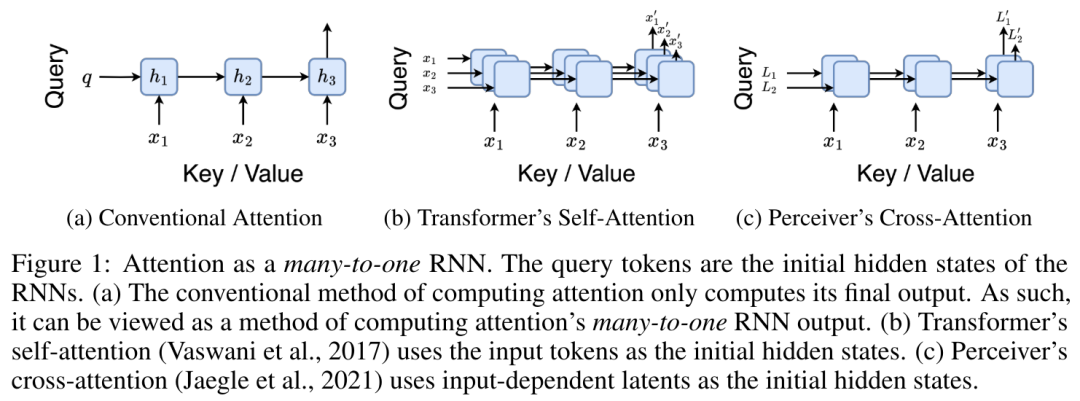
具体的には、研究者最初に、Transformer のアテンション メカニズムを調査しました。これは、Transformer の計算複雑性を二次関数的に増加させるコンポーネントです。この研究は、アテンション メカニズムが、多対 1 の RNN 出力を効率的に計算する機能を備えた特別なタイプのリカレント ニューラル ネットワーク (RNN) とみなすことができることを示しています。この研究では、注意の RNN 定式化を活用して、Transformer や Perceiver などの一般的な注意ベースのモデルが RNN の亜種とみなせることを示しています。 ただし、LSTM や GRU などの従来の RNN とは異なり、Transformer や Perceiver などの人気のアテンション モデルは RNN の亜種と考えることができます。残念ながら、新しいトークンを使用して効率的に更新することはできません。 この問題を解決するために、この研究では、並列プレフィックススキャンアルゴリズムに基づいた新しいアテンション式を導入します。これは、多対多(多対多)のアテンションを効率的に計算できます。多数) RNN 出力を使用して効率的な更新を実現します。 この新しいattention公式に基づいて、この研究はAaren ([A]tention [a] s a [re] current neural [n] etwork)を提案しています。これは、Transformerのように並列トレーニングできるだけでなく、計算効率の高いモジュールです。ですが、RNN と同じくらい効率的に更新することもできます。 実験結果は、Aaren のパフォーマンスが、強化学習、イベント予測、時系列分類、時系列予測タスクという 4 つの一般的なシーケンス データ設定をカバーする 38 個のデータセットで Transformer に匹敵することを示しています。また、時間と時間の面でもより効率的です。メモリ。 上記の問題を解決するために、著者はGPU並列性を利用し、同時に効率的に更新できるアテンションに基づく効率的なモジュールを提案します。 まず、著者らはセクション 3.1 で、attention が多対 1 RNN の出力を効率的に計算する特別な能力を備えた RNN の一種とみなすことができることを示しています (図 1a)。著者らは、注意の RNN 形式を活用して、Transformer (図 1b) や Perceiver (図 1c) などの一般的な注意ベースのモデルが RNN とみなせることをさらに説明しています。ただし、従来の RNN とは異なり、これらのモデルは新しいトークンに基づいて効率的に更新することができないため、データがストリームの形式で到着する連続的な問題における可能性が制限されます。 この問題を解決するために、著者はセクション 3.2 で並列プレフィックス スキャン アルゴリズムに基づいて多対多 RNN でアテンションを計算する効率的な方法を紹介します。これに基づいて、著者はセクション 3.3 で Aaren を紹介しました。Aaren は、(Transformer と同様に) 並行してトレーニングできるだけでなく、推論中に一定のメモリのみを必要とする、新しいトークンで効率的に更新できる計算効率の高いモジュールです。従来の RNN と同様)。クエリベクトルqのattentionは、N個のコンテキストトークンx_1:Nのキーと値を渡す関数として見ることができます 単一の出力 o_N = アテンション (q, k_1:N, v_1:N) にマッピングされます。 s_i = dot (q, k_i) とすると、出力 o_N は次のように表すことができます: ここで、分子は 、分母は です。アテンションを RNN として考えると、 と は、k = 1,...,.... の場合、ローリング合計方式で反復的に計算できます。しかし、実際には、この実装は不安定であり、精度表現が限られており、指数が非常に小さいか非常に大きい可能性があるため、数値上の問題が発生します (つまり、exp (s))。この問題を軽減するために、著者は累積最大項 を使用して漸化式を書き換えて と を計算します。最終結果が同じであることは注目に値します 、m_k のループ計算は次のとおりです:
単一の出力 o_N = アテンション (q, k_1:N, v_1:N) にマッピングされます。 s_i = dot (q, k_i) とすると、出力 o_N は次のように表すことができます: ここで、分子は 、分母は です。アテンションを RNN として考えると、 と は、k = 1,...,.... の場合、ローリング合計方式で反復的に計算できます。しかし、実際には、この実装は不安定であり、精度表現が限られており、指数が非常に小さいか非常に大きい可能性があるため、数値上の問題が発生します (つまり、exp (s))。この問題を軽減するために、著者は累積最大項 を使用して漸化式を書き換えて と を計算します。最終結果が同じであることは注目に値します 、m_k のループ計算は次のとおりです:
a_(k-1)、c_(k-1)、m_(k-1) からの a_k、c_k、m_k の巡回計算をカプセル化することで、著者はアテンションの出力を反復的に計算できる RNN ユニットを導入しました (参照図2)。アテンション RNN ユニットは (a_(k-1), c_(k-1), m_(k-1), q) を入力として受け取り、(a_k, c_k, m_k, q) を計算します。クエリ ベクトル q は RNN ユニットで渡されることに注意してください。アテンション RNN の初期隠れ状態は (a_0, c_0, m_0, q) = (0, 0, 0, q) です。 アテンションを計算する方法: アテンションを RNN として考えることで、アテンションを計算するさまざまな方法がわかります。O (1) メモリ内のトークンごとにループ計算する (つまり、逐次計算)、または従来の方法で計算する (つまり、並列コンピューティング)、線形 O(N) メモリが必要です。アテンションは RNN とみなすことができるため、アテンションを計算する従来の方法は、アテンションの多対 1 RNN の出力を計算する効率的な方法であるとみなすこともできます。つまり、RNN の出力は次のように複数のコンテキスト トークンを取ります。入力されますが、RNN の最後には 1 つのトークンのみが出力されます (図 1a を参照)。最後に、アテンションは、完全に順次または完全に並列ではなく、チャンクごとにトークンを処理する RNN として計算することもできます。これには、O(b) メモリが必要です。ここで、b はチャンクのサイズです。 既存のアテンション モデルを RNN として扱います。注意を RNN として扱うことにより、既存の注意ベースのモデルを RNN のバリアントとみなすこともできます。たとえば、Transformer のセルフアテンションは RNN (図 1b) であり、コンテキスト トークンはその初期の非表示状態です。 Perceiver のクロスアテンションは RNN (図 1c) であり、その初期の隠れ状態はコンテキスト依存の潜在変数です。 RNN 形式のアテンション メカニズムを活用することで、これらの既存のモデルは出力ストアを効率的に計算できます。 ただし、既存のアテンションベースのモデル (Transformer など) が RNN として考慮される場合、これらのモデルには、従来の RNN (LSTM や GRU など) で一般的に見られる重要なプロパティが欠けています。 注目に値するのは、LSTM と GRU は、わずか O(1) の定数メモリと計算で新しいトークンを使用して効率的に更新できることです。対照的に、Transformer の RNN ビュー (図 1b を参照) では、新しいトークンが追加されます。初期状態として、新しいトークンを処理するために新しい RNN が追加されます。この新しい RNN は以前のすべてのトークンを処理し、O(N) 線形計算を必要とします。 Perceiver では、そのアーキテクチャにより、潜在変数 (図 1c の L_i) は入力に依存します。これは、新しいトークンを受信すると値が変化することを意味します。 RNN の初期の隠れ状態 (つまり、潜在変数) が変化すると、Perceiver は RNN を最初から再計算する必要があり、O (NL) の線形計算量が必要になります。ここで、N はトークンの数、L はトークンの数です。潜在変数。 これらの制限を考慮して、著者は、RNN 定式化の機能を活用して効率的な更新を実行するアテンションベースのモデルを開発することを提案します。 。この目的のために、著者はまず、多対多の RNN としてアテンションを計算する効率的な並列化手法、つまり並列計算 の手法を紹介します。この目的を達成するために、著者らは、相関演算子 ⊕ を介して N 個の連続するデータ ポイントから N 個のプレフィックスを計算する並列計算方法である並列プレフィックス スキャン アルゴリズム (アルゴリズム 1 を参照) を利用します。このアルゴリズムは、Reviewを効率的に計算できます。ここで、を効率的に計算するには、とを並列スキャンアルゴリズムを通じて計算し、次にa_kとc_kを組み合わせて計算します。 。 この目的のために、著者は次の相関演算子 ⊕ を提案します。これは形式 (m_A, u_A, w_A) のトリプルに作用します。ここで、A はインデックスのセット , , 。並列スキャン アルゴリズムへの入力は です。アルゴリズムは演算子 ⊕ を再帰的に適用し、次のように動作します: 、ここで 、。
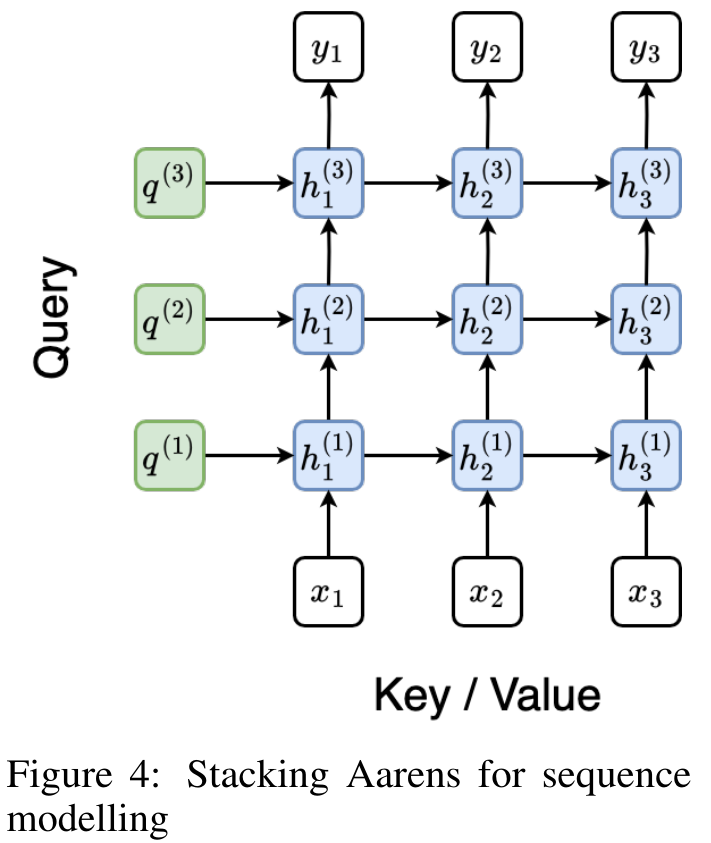
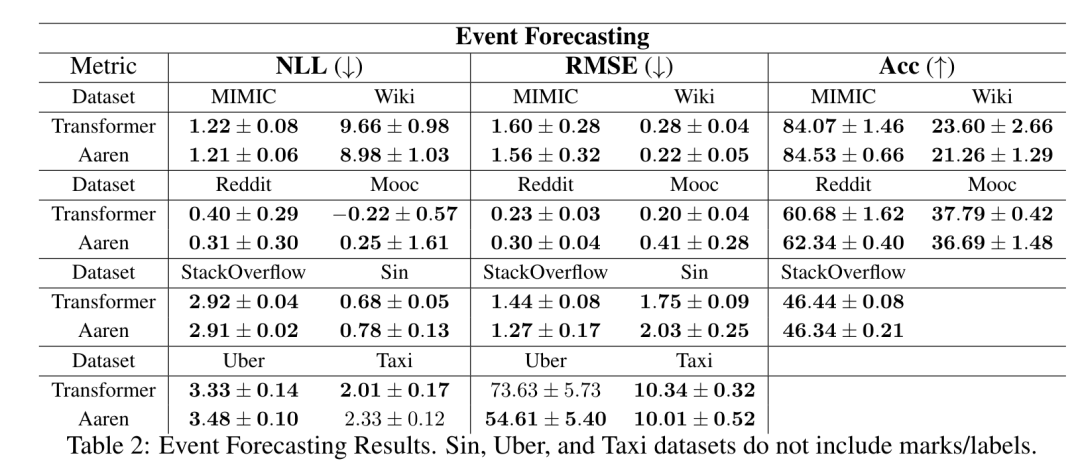
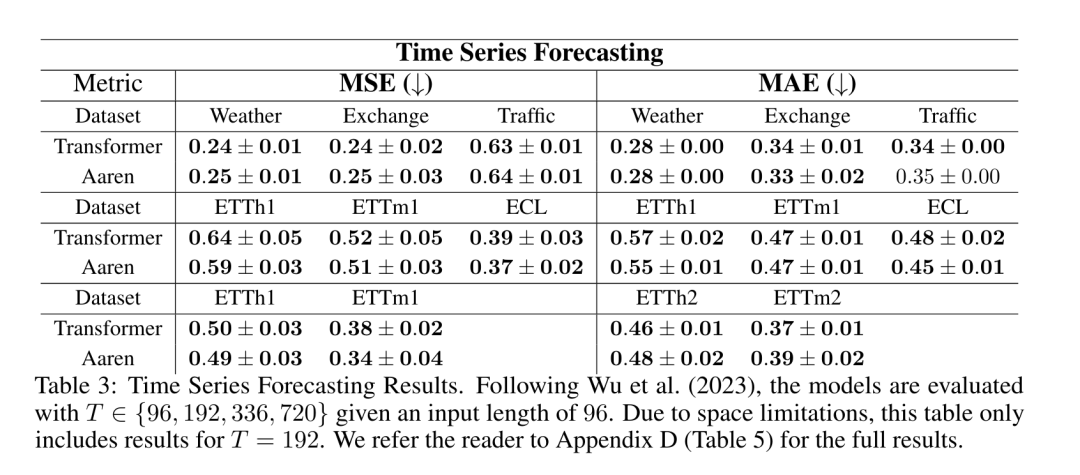
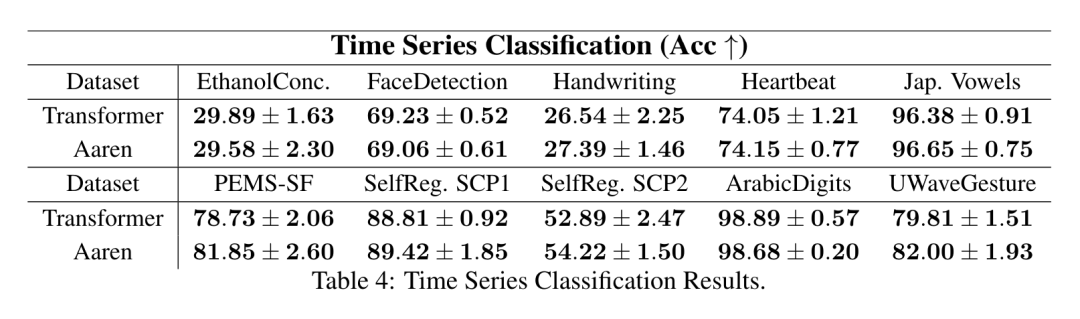
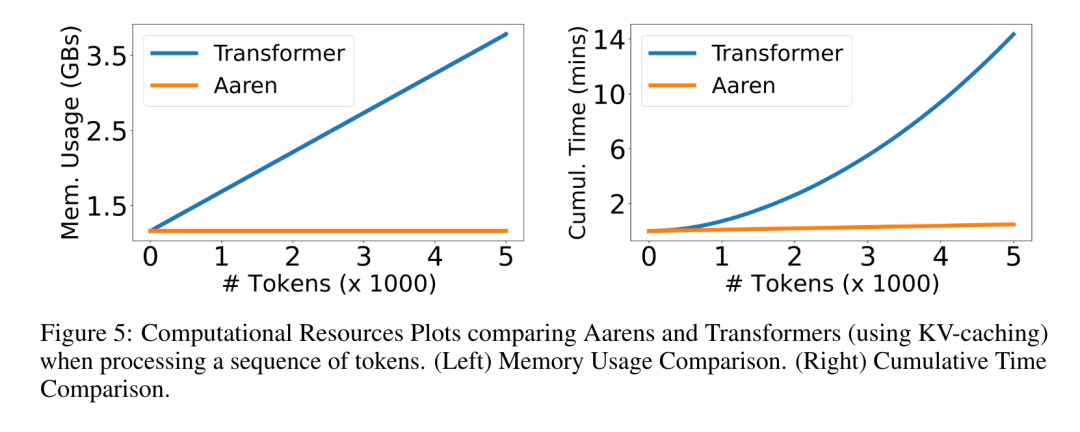
演算子の再帰的適用が完了すると、アルゴリズムは を出力します。 としても知られています。出力タプルの最後の 2 つの値を結合すると、 が取得され、多対多の RNN としてアテンションを計算する効率的な並列方法が得られます (図 3)。 Aaren: [A] 注目 [a] s a [re] current neural [n] etworkAaren のインターフェイスは Transformer と同じです、つまり N 入力ですは N 個の出力にマッピングされ、i 番目の出力は 1 番目から i 番目の入力の集合です。さらに、Aaren は当然スタック可能であり、シーケンス トークンごとに個別の損失条件を計算できます。ただし、因果的自己注意を使用する Transformers とは異なり、Aaren は注意を計算する上記の方法を多対多の RNN として使用し、より効率的にしています。 Aaren の形式は次のとおりです。 Transformer とは異なり、Transformer ではクエリはアテンションに入力されるトークンの 1 つですが、Aaren ではクエリ トークン q が逆伝播によって渡されます。トレーニングプロセス中に学習しました。 下の図は、スタックされた Aaren モデルの例を示しています。モデルの入力コンテキスト トークンは x_1:3 で、出力は y_1:3 です。 Aaren は RNN の形式でアテンション メカニズムを利用するため、Aarens をスタッキングすることは RNN をスタッキングすることと同等であることに注意してください。したがって、Aarens は新しいトークンで効率的に更新することもできます。つまり、y_k の反復計算は、h_k-1 と x_k にのみ依存するため、定数の計算のみが必要です。 Transformer ベースのモデルは線形メモリ (KV キャッシュを使用する場合) を必要とし、中間の Transformer 層のトークンを含む以前のすべてのトークンを保存する必要がありますが、Aaren ベースのモデルは定数メモリのみを必要とします。また、以前のトークンをすべて保存する必要がないため、計算効率の点で Aarens は Transformer よりも大幅に優れています。 実験部分の目標は、パフォーマンスと必要なリソース (時間とメモリ) の観点から Aaren と Transformer を比較することです。包括的な比較を行うために、著者らは強化学習、イベント予測、時系列予測、時系列分類の 4 つの問題について評価を実行しました。 著者はまず、強化学習における Aaren と Transformer のパフォーマンスを比較しました。強化学習は、ロボット工学、レコメンデーション エンジン、交通制御などの対話型環境で一般的です。 表 1 の結果は、Aaren が 12 のデータセットすべてと 4 つの環境にわたって Transformer と同等のパフォーマンスを示していることを示しています。ただし、Transformer とは異なり、Aaren は RNN でもあるため、連続計算で新しい環境相互作用を効率的に処理でき、強化学習により適しています。 次に、著者はイベント予測におけるアーレンとトランスフォーマーのパフォーマンスを比較しました。イベント予測は、金融 (取引など)、ヘルスケア (患者観察など)、電子商取引 (購入など) など、多くの実世界の設定で一般的です。 表 2 の結果は、Aaren がすべてのデータセットで Transformer と同等のパフォーマンスを示していることを示しています。新しい入力を効率的に処理する Aaren の機能は、イベントが不規則なストリームで発生するイベント予測環境で特に役立ちます。 次に、著者は時系列予測におけるAarenとTransformerのパフォーマンスを比較しました。時系列予測モデルは、気候 (天候など)、エネルギー (需要と供給など)、経済 (株価など) に関連する分野で一般的に使用されます。 表 3 の結果は、Aaren がすべてのデータセットで Transformer と同等のパフォーマンスを示していることを示しています。ただし、Transformer とは異なり、Aaren は時系列データを効率的に処理できるため、時系列関連の分野により適しています。 次に、著者は時系列分類におけるAarenとTransformerのパフォーマンスを比較しました。時系列分類は、パターン認識 (心電図など)、異常検出 (銀行詐欺など)、障害予測 (送電網の変動など) など、多くの重要なアプリケーションで一般的です。 表 4 からわかるように、Aaren はすべてのデータセットで Transformer と同様のパフォーマンスを発揮します。 最後に、著者は Aaren と Transformer に必要なリソースを比較します。 メモリの複雑さ: 図 5 (左) では、著者は推論時の Aaren と Transformer (KV キャッシュを使用) のメモリ使用量を比較しています。 KV キャッシュ テクノロジを使用すると、Transformer のメモリ使用量が直線的に増加することがわかります。対照的に、Aaren はトークンの数がどのように増加しても一定量のメモリのみを使用するため、はるかに効率的です。 時間計算量: 図 5 (右) では、著者は Aaren と Transformer (KV キャッシュを使用) が一連のトークンを順番に処理するのに必要な累積時間を比較しています。 Transformer の場合、累積計算量はトークン数の 2 乗、つまり O (1 + 2 + ... + N) = O (N^2) となります。対照的に、Aaren の累積計算量は線形です。この図では、モデルに必要な累積時間が同様の結果になっていることがわかります。具体的には、Transformer に必要な累積時間は二次関数的に増加しますが、Aaren に必要な累積時間は直線的に増加します。 パラメータの数: 初期の隠れ状態 q を学習する必要があるため、Aaren モジュールは Transformer モジュールよりもわずかに多くのパラメータを必要とします。ただし、q は単なるベクトルであるため、違いは重要ではありません。著者らは、同様のモデルの経験的測定を通じて、Transformer が 3、152、384 個のパラメータを使用していることを発見しました。比較すると、同等の Aaren は 3,152,896 個のパラメーターを使用しており、パラメーターの増加はわずか 0.016% であり、メモリと時間の複雑さの大きな違いに対して支払う代償は無視できるほどです。 以上がBengio らによる新しい作品: RNN と見なすことができる新しいモデルは、Transformer に匹敵しますが、非常にメモリを節約します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



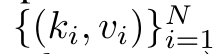 単一の出力 o_N = アテンション (q, k_1:N, v_1:N) にマッピングされます。 s_i = dot (q, k_i) とすると、出力 o_N は次のように表すことができます:
単一の出力 o_N = アテンション (q, k_1:N, v_1:N) にマッピングされます。 s_i = dot (q, k_i) とすると、出力 o_N は次のように表すことができます: 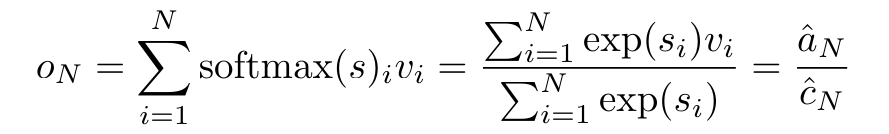
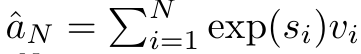 、分母は
、分母は 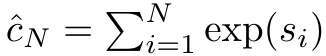 です。アテンションを RNN として考えると、
です。アテンションを RNN として考えると、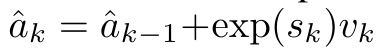 と
と  は、k = 1,...,.... の場合、ローリング合計方式で反復的に計算できます。しかし、実際には、この実装は不安定であり、精度表現が限られており、指数が非常に小さいか非常に大きい可能性があるため、数値上の問題が発生します (つまり、exp (s))。この問題を軽減するために、著者は累積最大項
は、k = 1,...,.... の場合、ローリング合計方式で反復的に計算できます。しかし、実際には、この実装は不安定であり、精度表現が限られており、指数が非常に小さいか非常に大きい可能性があるため、数値上の問題が発生します (つまり、exp (s))。この問題を軽減するために、著者は累積最大項 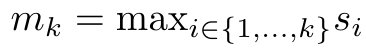 を使用して漸化式を書き換えて
を使用して漸化式を書き換えて 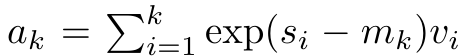 と
と 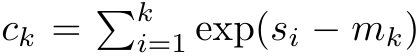 を計算します。最終結果が同じであることは注目に値します
を計算します。最終結果が同じであることは注目に値します 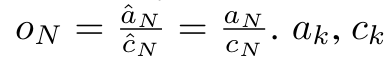 、m_k のループ計算は次のとおりです:
、m_k のループ計算は次のとおりです: 

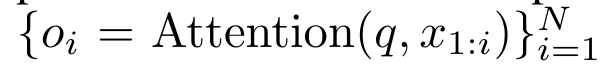 の手法を紹介します。この目的を達成するために、著者らは、相関演算子 ⊕ を介して N 個の連続するデータ ポイントから N 個のプレフィックスを計算する並列計算方法である並列プレフィックス スキャン アルゴリズム (アルゴリズム 1 を参照) を利用します。このアルゴリズムは、
の手法を紹介します。この目的を達成するために、著者らは、相関演算子 ⊕ を介して N 個の連続するデータ ポイントから N 個のプレフィックスを計算する並列計算方法である並列プレフィックス スキャン アルゴリズム (アルゴリズム 1 を参照) を利用します。このアルゴリズムは、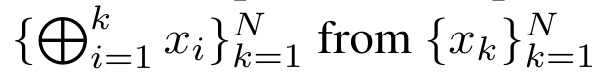

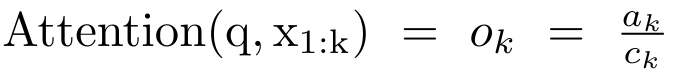 を効率的に計算できます。ここで
を効率的に計算できます。ここで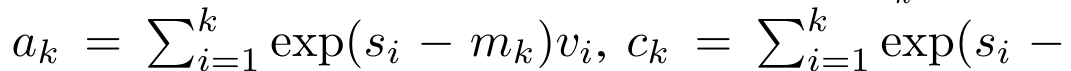
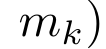 、
、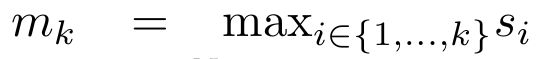
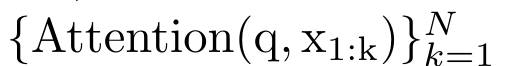 を効率的に計算するには、
を効率的に計算するには、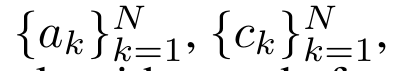 と
と を並列スキャンアルゴリズムを通じて計算し、次にa_kとc_kを組み合わせて計算します。
を並列スキャンアルゴリズムを通じて計算し、次にa_kとc_kを組み合わせて計算します。  。
。 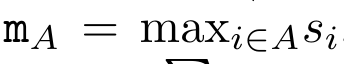 ,
, 
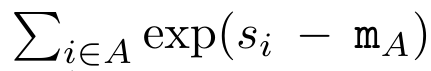 ,
,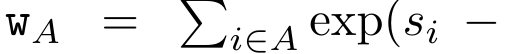
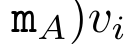 。並列スキャン アルゴリズムへの入力は
。並列スキャン アルゴリズムへの入力は  です。アルゴリズムは演算子 ⊕ を再帰的に適用し、次のように動作します:
です。アルゴリズムは演算子 ⊕ を再帰的に適用し、次のように動作します:  、ここで
、ここで 
 、
、
 。
。 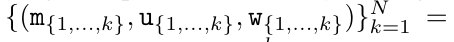
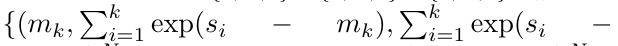
 を出力します。
を出力します。 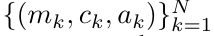 としても知られています。出力タプルの最後の 2 つの値を結合すると、
としても知られています。出力タプルの最後の 2 つの値を結合すると、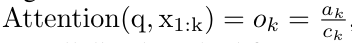 が取得され、多対多の RNN としてアテンションを計算する効率的な並列方法が得られます (図 3)。
が取得され、多対多の RNN としてアテンションを計算する効率的な並列方法が得られます (図 3)。