
ホームページ >テクノロジー周辺機器 >AI >Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-07 12:05:271240ブラウズ
1. はしがき
ここ数年、計算コストと検出パフォーマンスの効果的なバランスにより、YOLO はリアルタイム物体検出の分野で支配的なパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。
YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が不足しており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために、私たちはまず、YOLO の NMS フリー トレーニングに対する一貫した二重割り当てを提案します。これにより、競争力のあるパフォーマンスと低い推論レイテンシーが同時に実現されます。さらに、YOLO の全体的な効率と精度を重視したモデル設計戦略も紹介されています。
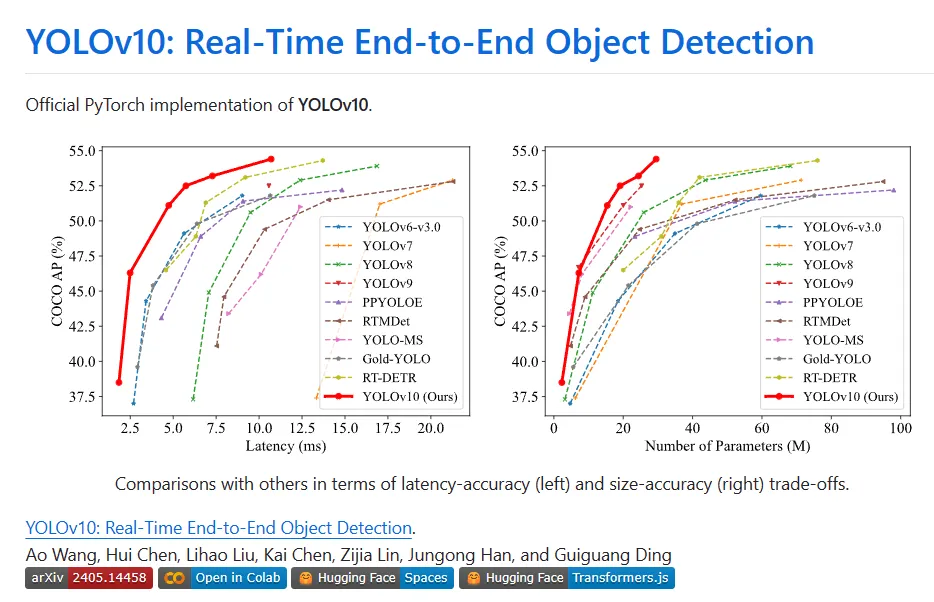
YOLO のさまざまなコンポーネントは、効率と精度の向上、コンピューティングのオーバーヘッドの大幅な削減、機能の強化という 2 つの観点から完全に最適化されています。その成果は、YOLOv10 と呼ばれる、リアルタイムのエンドツーエンドのターゲット検出のための新世代の YOLO シリーズです。広範な実験により、YOLOv10 がさまざまなモデル スケールで最先端のパフォーマンスと効率を達成することが示されています。たとえば、COCO 上の同様の AP では、YOLOv10-Sis1.8 は RT-DETR-R18 より 1.8 倍高速で、同時に共有されるパラメータと FLOP の数は 2.8 倍です。 YOLOv9-C と比較すると、同じパフォーマンスの下で、YOLOv10-B ではレイテンシが 46% 削減され、パラメータが 25% 削減されます。
II. 背景
リアルタイムの物体検出は、低遅延で画像内の物体のカテゴリと位置を正確に予測することを目的としており、常に研究の注目を集めています。 。自動運転、ロボットナビゲーション、物体追跡などのさまざまな実用用途に広く使用されています。近年、研究者はリアルタイム検出を実現するために CNN ベースの物体検出器の設計に焦点を当ててきました。 リアルタイム物体検出器は、1 段階検出器と 2 段階検出器の 2 つのカテゴリに分類できます。 1 段階検出器は入力画像に対して直接密な予測を行いますが、2 段階検出器は最初に候補ボックスを生成し、次にこれらの候補ボックスに対して分類と位置回帰を実行します。
その中でも、パフォーマンスと効率の巧みなバランスにより、YOLOの人気が高まっています。 YOLO の検出パイプラインは、モデルの前処理と NMS の後処理の 2 つの部分で構成されます。ただし、どちらの方法にも依然として欠点があり、精度と待ち時間の限界が最適ではありません。具体的には、YOLO は通常、トレーニング中に 1 対多のラベル割り当て戦略を採用し、1 つの基本実装オブジェクトが複数のサンプル ブックに対応します。このアプローチでは優れたパフォーマンスが得られますが、NMS は推論中に最良の肯定的な予測を選択する必要があります。これにより、推論が遅くなり、パフォーマンスが NMS のハイパーパラメータに敏感になり、YOLO が最適なエンドツーエンド展開を達成できなくなります。この問題を解決する 1 つの方法は、最近導入されたエンドツーエンド DETR アーキテクチャを採用することです。たとえば、RT-DETR は、不確実性を最小限に抑えた効率的なハイブリッド エンコーダとクエリ選択を提供し、DETR をリアルタイム アプリケーションに押し込みます。ただし、DETR の導入には固有の複雑さがあり、精度と速度の最適なバランスを達成することが妨げられています。別の行では、CNN ベースの検出器のエンドツーエンド検出について調査します。これは、通常、冗長な予測を抑制するために 1 対 1 の割り当て戦略を利用します。
ただし、多くの場合、追加の推論オーバーヘッドが発生したり、次善のパフォーマンスが得られたりします。さらに、モデル アーキテクチャの設計は YOLO にとって依然として根本的な課題であり、精度と速度に大きな影響を与えます。より効率的かつ効果的なモデル アーキテクチャを実現するために、研究者はさまざまな設計戦略を検討してきました。特徴抽出機能を強化するために、DarkNet、CSPNet、EfficientRep、ELAN などのさまざまなメイン コンピューティング ユニットがバックボーンに提供されています。ネックについては、PAN、BiC、GD、RepGFPN などが検討され、マルチスケールの機能融合が強化されます。さらに、モデルのスケーリング戦略と再パラメータ化手法も調査されます。これらの取り組みは大幅に進歩しましたが、効率と精度の観点から YOLO のさまざまなコンポーネントを包括的に検討する余地がまだあります。したがって、モデルを制約する機能によってパフォーマンスの違いも生まれ、精度を向上させる余地が十分に残されています。
3. 新しいテクノロジー
NMSなしのトレーニングのための一貫したデュアル割り当て
トレーニング中、YOLO は通常、TAL を利用してインスタンスごとに複数の陽性サンプルを割り当てます。 1 対多の割り当てを採用すると、最適化と優れたパフォーマンスの実現に役立つ豊富なモニタリング信号が生成されます。ただし、YOLO は NMS の後処理に依存する必要があるため、デプロイ推論の効率が不十分になります。これまでの研究では、冗長な予測を抑制するために 1 対 1 のマッチングを検討していましたが、多くの場合、追加の推論オーバーヘッドが発生したり、次善のパフォーマンスが生成されたりしていました。この研究では、YOLO は二重ラベル割り当てと一貫したマッチングメトリクスを備えた NMS フリーのトレーニング戦略を提供し、高い効率と競争力のあるパフォーマンスを実現します。
- デュアルラベル割り当て
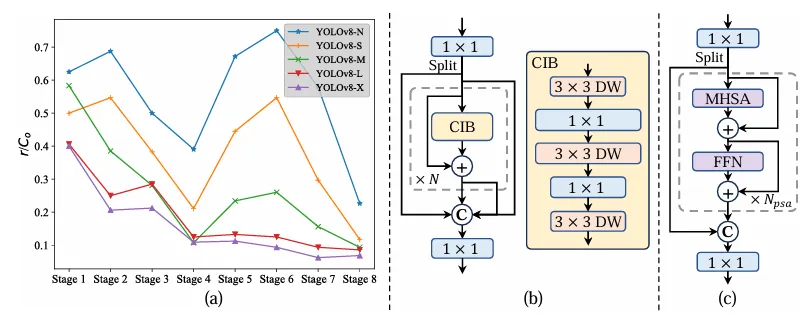
1対多の割り当てとは異なり、1対1のマッチングでは各グランドトゥルースに1つの予測のみを割り当て、NMSによる後処理を回避します。 。ただし、監視が不十分になり、精度と収束速度が最適ではなくなります。幸いなことに、この欠点は 1 対多の割り当てによって解決できます。これを達成するために、YOLO は両方の戦略の長所を組み合わせたデュアル ラベル割り当てを導入します。具体的には、以下の図(a)のようになります。
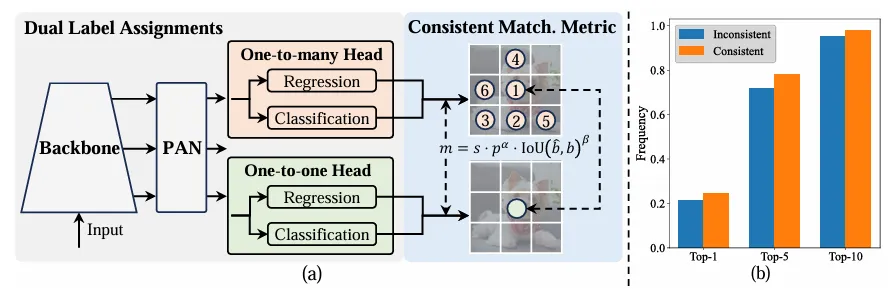
YOLO の別の 1 対 1 ヘッダーを紹介します。元の 1 対多分岐と同じ構造を保持し、同じ最適化目標を採用しますが、ラベル割り当てを取得するために 1 対 1 マッチングを利用します。トレーニング プロセス中に、2 つの頭部がモデルとともに最適化され、背骨と首が 1 対多のタスクによって提供される豊富な監視を享受できるようになります。推論中、1 対多ヘッダーは破棄され、1 対 1 ヘッダーが予測に利用されます。これにより、追加の推論コストを発生させることなく、YOLO をエンドツーエンドで導入できるようになります。さらに、1 対 1 マッチングでは前の選択が採用され、追加のトレーニング時間をより少なくしてハンガリー マッチングと同じパフォーマンスを実現します。
- 一貫したマッチングメトリクス
割り当てプロセス中、1 対 1 メソッドと 1 対多メソッドの両方でメトリクスを利用して、予測とインスタンスの間の一貫性のレベルを定量的に評価します。 2 つのブランチの予測を考慮したマッチングを実現するには、統合されたマッチング メトリックが使用されます。
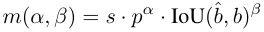
デュアルラベル割り当てでは、1 対多のブランチは 1 対 1 ブランチよりも豊富なモニタリング信号を提供します。直感的には、1 対 1 ヘッダーの監視を 1 対多ヘッダーの監視と調整できる場合、1 対 1 ヘッダーは 1 対多ヘッダーの最適化の方向に最適化できます。したがって、1 対 1 ヘッドにより推論中のサンプル品質が向上し、パフォーマンスが向上します。この目的を達成するために、まず両者間の規制上のギャップが分析されます。トレーニング プロセスのランダム性により、同じ値で初期化された 2 つのヘッドで検査を開始し、同じ予測を生成します。つまり、1 対 1 のヘッドと 1 対多のヘッドは、それぞれの予測に対して同じ結果を生成します。インスタンスのペア p と IoU。両方のブランチの回帰目標に注目してください。
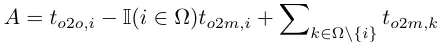
to2m、i=u*のとき、上記(a)に示すように、最小値に達します。つまり、iはΩの最良の正のサンプルです。これを達成するために、一貫したマッチング メトリック、つまり αo2o=r・αo2m および βo2o=r・βo2m、つまり mo2o=mro2m が提案されます。したがって、1 対多のヘッドにとって最適なポジティブ サンプルは、1 対 1 のヘッドにとっても最適なサンプルでもあります。その結果、両方のヘッドを一貫して調和して最適化できます。簡単にするために、デフォルトでは r=1 が採用されます。つまり、αo2o=αo2m および βo2o=βo2m です。改善された教師ありアライメントを検証するために、トレーニング後に 1 対多の結果の最初の 1/5/10 内の 1 対 1 一致ペアの数が計算されます。上の (b) に示すように、一貫したマッチング方法の下では位置合わせが改善されます。
スペースが限られているため、YOLOv10 の主要な革新は、デュアルラベル割り当て戦略の導入です。その中心となるアイデアは、トレーニング段階でより多くのポジティブサンプルを提供してモデルを強化することです。 . トレーニング; 推論段階では、勾配トランケーションを使用して 1 対 1 の検出ヘッドに切り替えるため、パフォーマンスを維持しながら推論のオーバーヘッドが削減されます。原理は実際には難しいものではなく、コードを見て理解することができます:
#https://github.com/THU-MIG/yolov10/blob/main/ultralytics/nn/modules/head.pyclass v10Detect(Detect):max_det = -1def __init__(self, nc=80, ch=()):super().__init__(nc, ch)c3 = max(ch[0], min(self.nc, 100))# channelsself.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), \ nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), \nn.Conv2d(c3, self.nc, 1)) for i, x in enumerate(ch))self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)def forward(self, x):one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)if not self.export:one2many = super().forward(x)if not self.training:one2one = self.inference(one2one)if not self.export:return {'one2many': one2many, 'one2one': one2one}else:assert(self.max_det != -1)boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)return torch.cat([boxes, scores.unsqueeze(-1), labels.unsqueeze(-1)], dim=-1)else:return {'one2many': one2many, 'one2one': one2one}def bias_init(self):super().bias_init()'''Initialize Detect() biases, WARNING: requires stride availability.'''m = self# self.model[-1]# Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum())# nominal class frequencyfor a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride):# froma[-1].bias.data[:] = 1.0# boxb[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2)# cls (.01 objects, 80 classes, 640 img)Holistic Efficiency-Accuracy Driven Model Design
架构改进:
- Backbone & Neck:使用了先进的结构如 CSPNet 作为骨干网络,和 PAN 作为颈部网络,优化了特征提取和多尺度特征融合。
- 大卷积核与分区自注意力:这些技术用于增强模型从大范围上下文中学习的能力,提高检测准确性而不显著增加计算成本。
- 整体效率:引入空间-通道解耦下采样和基于秩引导的模块设计,减少计算冗余,提高整体模型效率。
四、实验
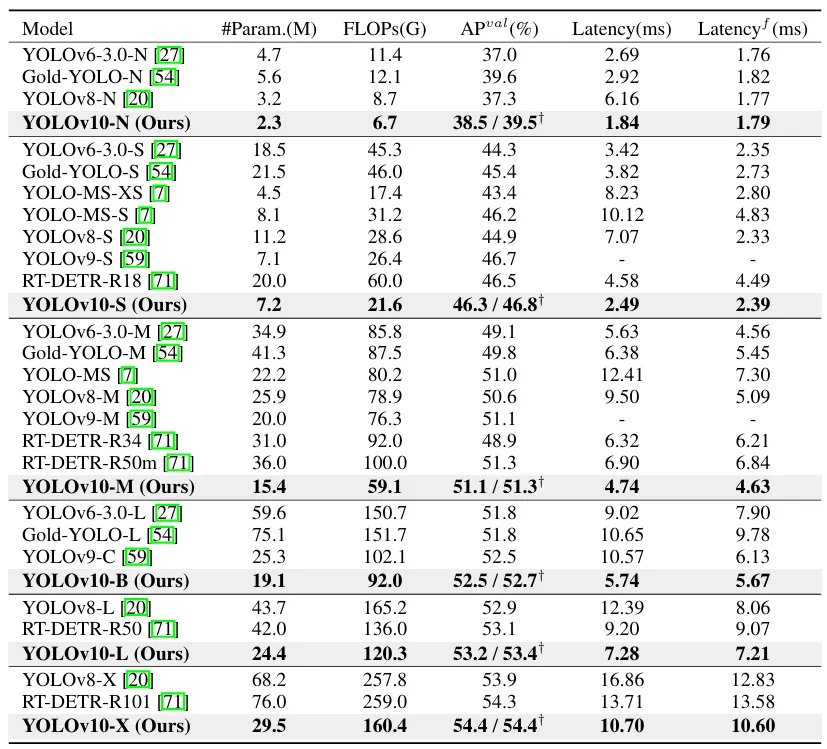
与最先进的比较。潜伏性是通过官方预训练的模型来测量的。潜在的基因测试在具有前处理的模型的前处理中保持了潜在性。†是指YOLOv10的结果,其本身对许多训练NMS来说都是如此。以下是所有结果,无需添加先进的训练技术,如知识提取或PGI或公平比较:

五、部署测试
首先,按照官方主页将环境配置好,注意这里 python 版本至少需要 3.9 及以上,torch 版本可以根据自己本地机器安装合适的版本,默认下载的是 2.0.1:
conda create -n yolov10 pythnotallow=3.9conda activate yolov10pip install -r requirements.txtpip install -e .
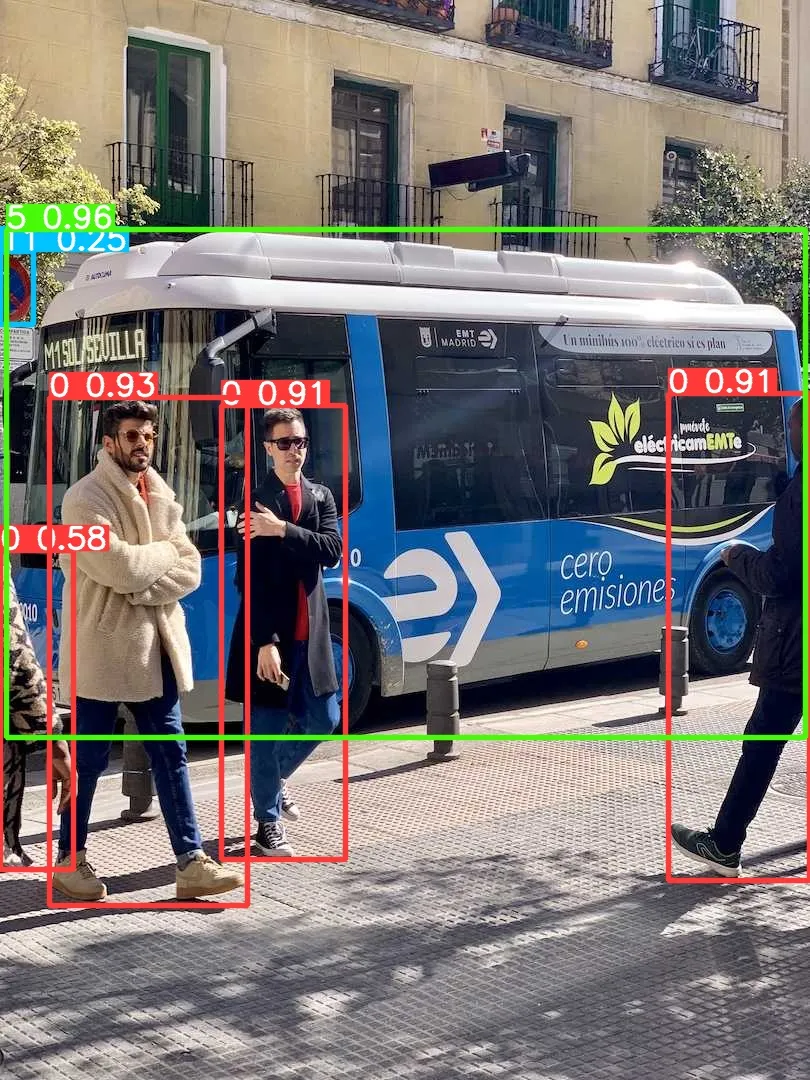
安装完成之后,我们简单执行下推理命令测试下效果:
yolo predict model=yolov10s.pt source=ultralytics/assets/bus.jpg
让我们尝试部署一下,譬如先导出个 onnx 模型出来看看:
yolo export model=yolov10s.pt format=onnx opset=13 simplify
好了,接下来通过执行 pip install netron 安装个可视化工具来看看导出的节点信息:
# run python fisrtimport netronnetron.start('/path/to/yolov10s.onnx')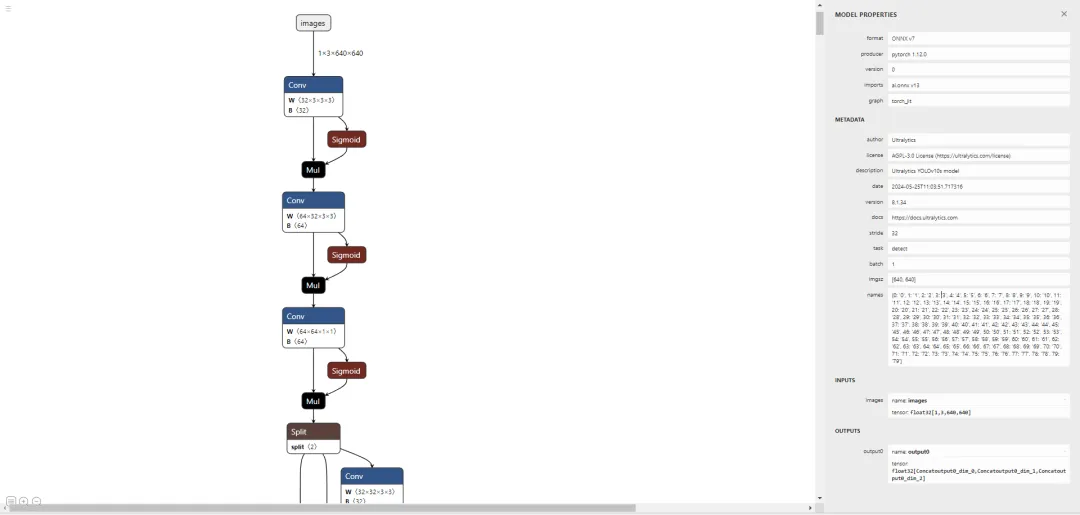
先直接通过 Ultralytics 框架预测一个测试下能否正常推理:
yolo predict model=yolov10s.onnx source=ultralytics/assets/bus.jpg

大家可以对比下上面的运行结果,可以看出 performance 是有些许的下降。问题不大,让我们基于 onnxruntime 写一个简单的推理脚本,代码地址如下,有兴趣的可以自行查看:
# 推理脚本https://github.com/CVHub520/X-AnyLabeling/blob/main/tools/export_yolov10_onnx.py# onnx 模型权重https://github.com/CVHub520/X-AnyLabeling/releases/tag/v2.3.6

以上がYolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。