
ホームページ >テクノロジー周辺機器 >AI >Yann LeCun: ViT は遅くて非効率です。リアルタイム画像処理は依然として畳み込みに依存しています。
Yann LeCun: ViT は遅くて非効率です。リアルタイム画像処理は依然として畳み込みに依存しています。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2024-06-06 13:25:021270ブラウズ
Transformer 統合の時代においても、コンピューター ビジョンの CNN の方向性を研究する必要はありますか?
今年の初めに、OpenAI の大規模ビデオ モデル Sora により、Vision Transformer (ViT) アーキテクチャが普及しました。それ以来、ViT と従来の畳み込みニューラル ネットワーク (CNN) のどちらがより強力であるかについての議論が続いています。
最近、ソーシャルメディアで活動しており、チューリング賞を受賞したMetaの主任科学者ヤン・ルカン氏も、ViTとCNNの間の紛争に関する議論に参加しました。

この事件の原因は、Comma.aiのCTOであるHarald Schäfer氏が最新の研究を披露していたことにありました。彼は(最近の多くの AI 学者と同様に)Yann LeCun の表現をヒントに、チューリング賞の大物は純粋な ViT は実用的ではないと信じているが、私たちは最近コンプレッサーを純粋な ViT に変更しましたが、すぐに得られるものはなく、トレーニングには時間がかかります。効果はとても良いです。
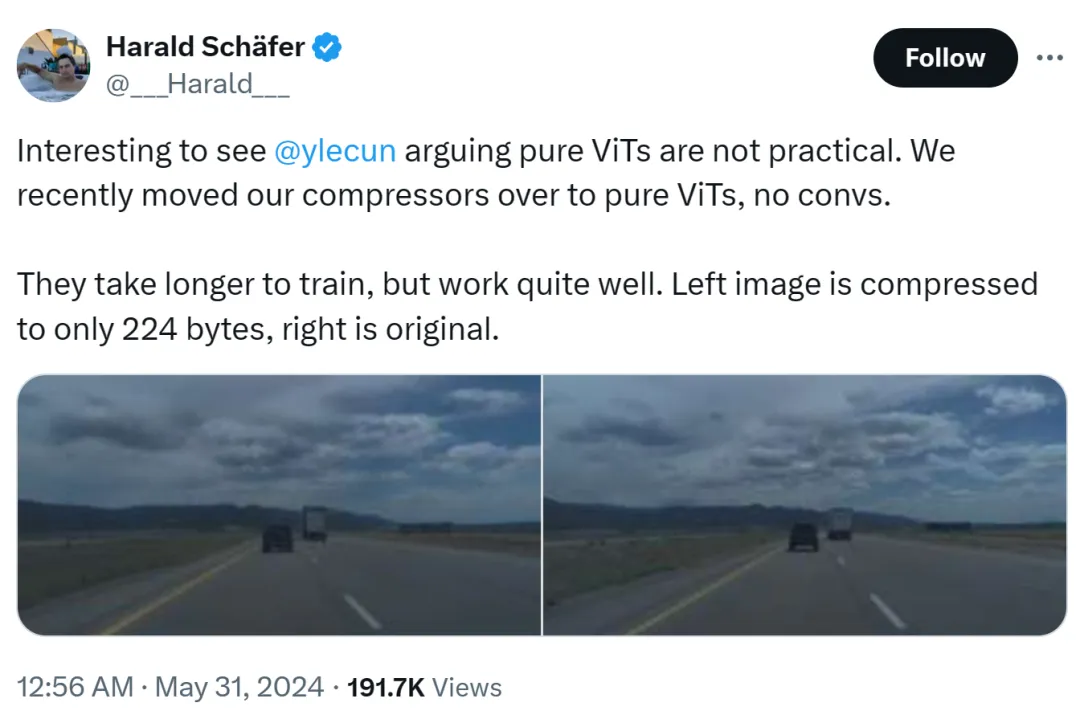
たとえば、左側の画像は 224 バイトのみに圧縮されており、右側は元の画像です。
はわずか 14×128 であり、これは自動運転の世界モデルとしては非常に大きく、大量のデータをトレーニングに入力できることを意味します。仮想環境でのトレーニングは、エージェントが適切に機能するためにポリシーに従ってトレーニングする必要がある実際の環境よりも安価です。仮想トレーニングの解像度が高いほど動作は良くなりますが、シミュレーターが非常に遅くなるため、現時点では圧縮が必要です。
彼のデモンストレーションは AI サークルでの議論を引き起こし、1X の人工知能担当副社長である Eric Jang は、その結果は素晴らしいと答えました。
ハラルド氏は ViT を賞賛し続けました: これはとても美しい建築です。
ここで誰かが攻撃を始めました。ルカンのような達人は時々イノベーションのペースについていけないことがあります。
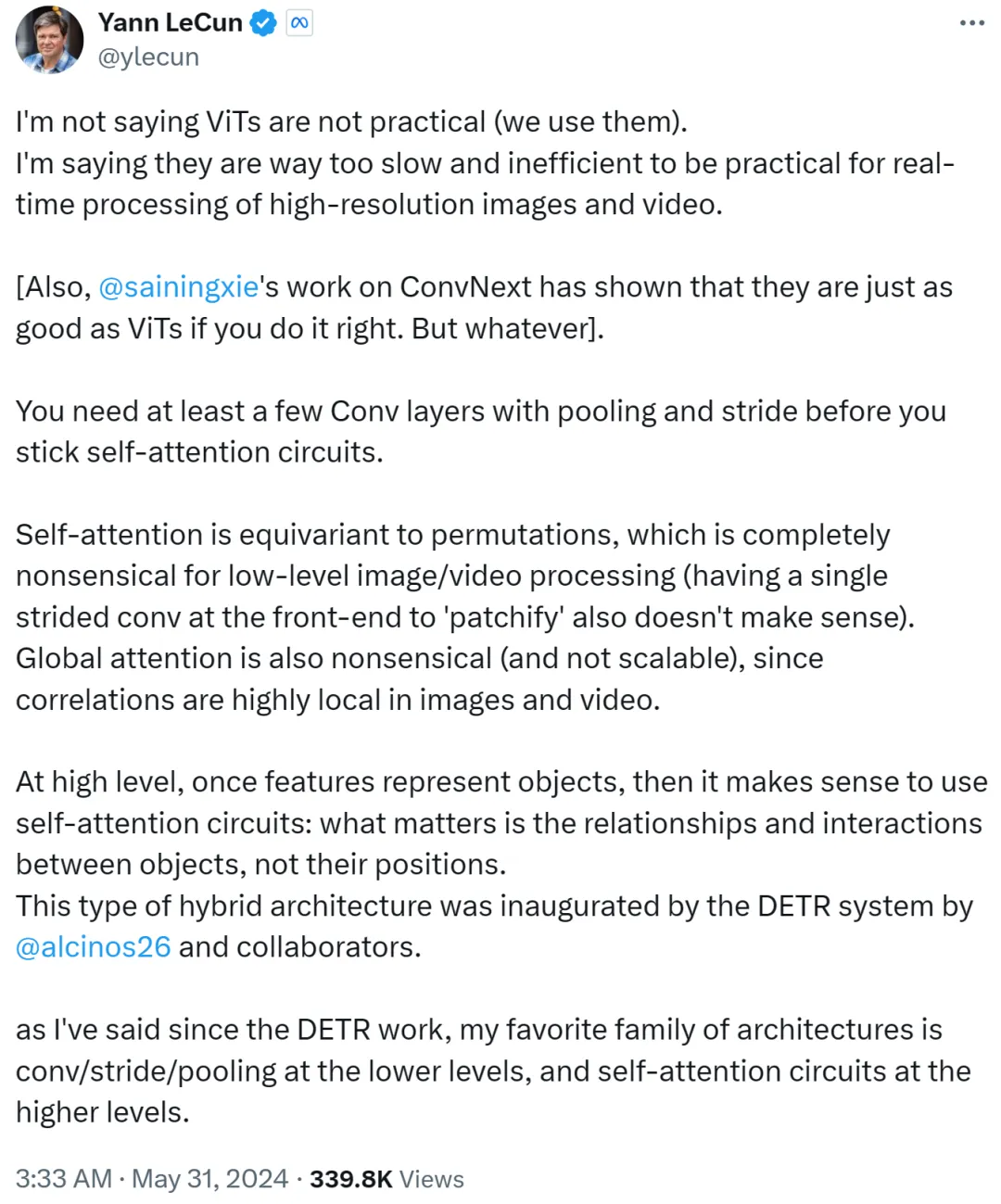
しかし、Yann LeCun は即座に反応し、ViT が実用的ではないと言っているわけではなく、今では誰もがそれを使用していると主張しました。彼が言いたいのは、ViT は遅すぎて非効率であるため、高解像度の画像やビデオのタスクのリアルタイム処理には適さないということです。
Yann LeCun も、ニューヨーク大学の助教授である Cue Xie Saining 氏であり、彼の研究は、方法が正しければ CNN が ViT と同じくらい優れていることを ConvNext で証明しました。
彼は続けて、自己注意ループに固執する前に、プーリングとストライドを備えた少なくともいくつかの畳み込み層が必要であると述べています。
セルフアテンションが順列と同等である場合、低レベルの画像やビデオの処理にはまったく意味がなく、フロントエンドで単一のストライドを使用してパッチ化することもできません。さらに、画像やビデオの相関関係は局所的に非常に集中しているため、世界的な注目は無意味であり、拡張性がありません。
より高いレベルでは、フィーチャがオブジェクトを表すと、セルフ アテンション ループを使用することが理にかなっています。重要なのは、オブジェクトの位置ではなく、オブジェクト間の関係と相互作用です。このハイブリッド アーキテクチャは、メタ研究科学者の Nicolas Carion とその共著者によって完成された DETR システムによって先駆的に開発されました。
DETR の研究が登場して以来、Yann LeCun は、自分のお気に入りのアーキテクチャは低レベルの畳み込み/ストライド/プーリングと高レベルのセルフ アテンション ループであると述べました。
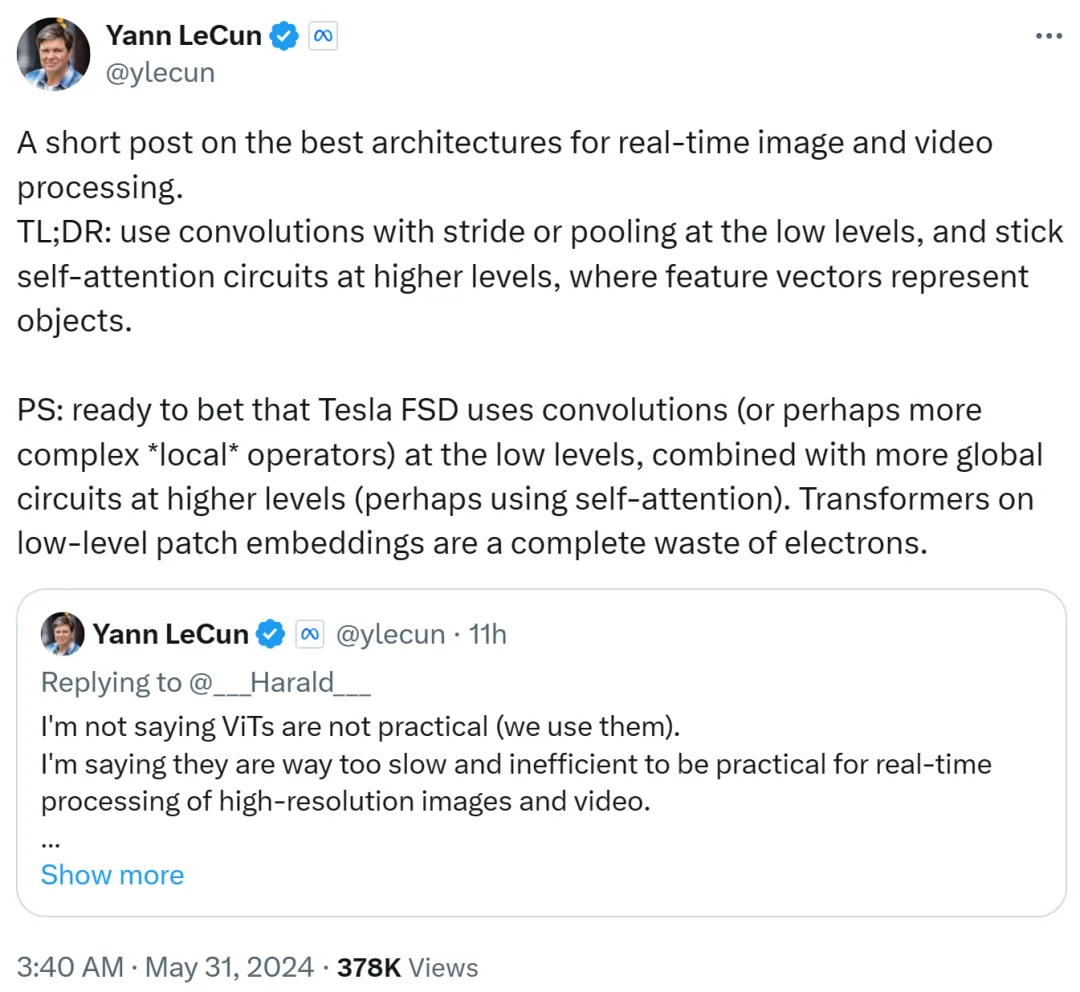
Yann LeCun が 2 番目の投稿でそれを要約しました。低レベルではストライドまたはプーリングによる畳み込みを使用し、高レベルではセルフ アテンション ループを使用し、オブジェクトを表すために特徴ベクトルを使用します。
彼はまた、テスラの完全自動運転 (FSD) が低レベルで畳み込み (またはより複雑なローカル演算子) を使用し、より高いレベルでよりグローバルなループ (おそらくセルフ アテンションを使用する) を組み合わせていると確信しています。したがって、低レベルのパッチ埋め込みで Transformer を使用することは完全に無駄です。
宿敵マスクは未だにコンボリューションルートを使っているのでしょうね。
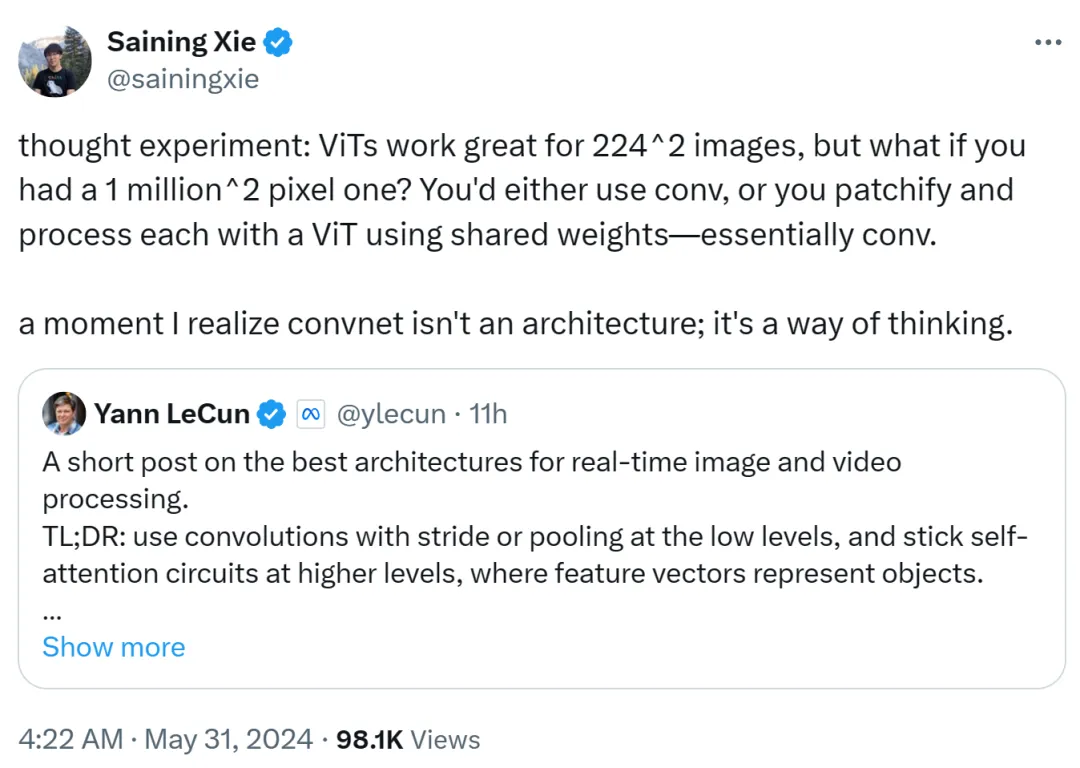
Xie Senin 氏も、ViT は 224x224 の低解像度画像に非常に適していると考えていますが、画像解像度が 100 万 x 100 万に達したらどうなるでしょうか?現時点では、畳み込みが使用されるか、共有重みを使用して ViT がパッチおよび処理されますが、これは本質的には畳み込みです。
したがって、Xie Senin 氏は、その瞬間、畳み込みネットワークはアーキテクチャではなく、考え方であることに気づいたと述べました。
この見解は、Yann LeCun によって認められています。

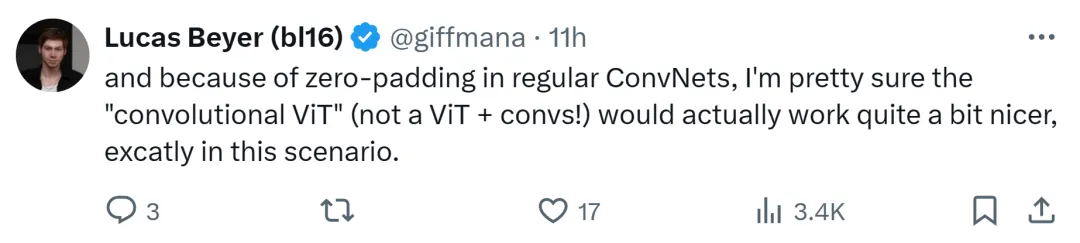
Google DeepMind の研究者である Lucas Beyer 氏も、従来の畳み込みネットワークのゼロ パディングのおかげで、「畳み込み ViT」(ViT + 畳み込みではなく) がうまく機能すると確信していると述べました。
ViT と CNN の間のこの議論は、将来別のより強力なアーキテクチャが登場するまで続くことが予測されます。
以上がYann LeCun: ViT は遅くて非効率です。リアルタイム画像処理は依然として畳み込みに依存しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。