


大規模モデルの波の中で、最先端の高密度セット LLM のトレーニングとデプロイは、特に数百億または数千億のパラメーターの規模で、計算要件と関連コストの点で大きな課題を引き起こします。これらの課題に対処するために、専門家混合 (MoE) モデルなどのスパース モデルの重要性がますます高まっています。 これらのモデルは、さまざまな特殊なサブモデル、つまり「エキスパート」に計算を分散することで経済的に実行可能な代替手段を提供し、リソース要件が非常に低い高密度セット モデルのパフォーマンスに匹敵する、またはそれを超える可能性があります。
6 月 3 日、オープンソースの大規模モデルの分野から別の重要なニュースが届きました。Kunlun Wanwei は、強力なパフォーマンスを維持しながら推論のコストを大幅に削減する、2,000 億のスパース大規模モデル Skywork-MoE のオープンソースを発表しました。
Kunlun Wanwei の以前のオープンソース Skywork-13B モデル中間チェックポイントに基づいて拡張された、MoE Upcycling テクノロジーを完全に適用および実装した最初のオープンソースの 1,000 億 MoE 大型モデルでもあります。単一の 4090 サーバーで数千億の MoE の大規模モデル。
大規模なモデル コミュニティにとってさらに注目を集めているのは、Skywork-MoE のモデルの重みと技術レポートが完全にオープンソースであり、商用利用が無料で、申請も必要ないことです。
モデルウェイトのダウンロードアドレス:
○ https://huggingface.co/Skywork/Skywork-MoE-base
○ https://huggingface.co/Skywork/Skywork-MoE-Base-FP8
モデルオープンソースウェアハウス: https://github.com/SkyworkAI/Skywork-MoE
モデル技術レポート: https://github.com/SkyworkAI/Skywork-MoE/blob/main/skywork-moe - tech-report.pdf
モデル推論コード: (8x4090 サーバーで 8 ビット量子化負荷推論をサポート) https://github.com/SkyworkAI/vllm
Skywork-MoE は現在、以下を推論できます。 8x4090 サーバー 最大のオープンソース MoE モデル。 8x4090 サーバーには合計 192GB の GPU メモリが搭載されており、FP8 量子化 (重みは 146GB を占有) では、Kunlun Wanwei チームが開発した不均一 Tensor Parallel 並列推論手法を使用して、Skywork-MoE は適切な範囲内で 2200 トークン/秒に達します。バッチサイズ。
関連する完全な推論フレームワーク コードとインストール環境については、https://github.com/SkyworkAI/Skywork-MoE を参照してください。 Tiangong 3.0 R&D モデル シリーズはミッドレンジ モデル (Skywork-MoE-Medium) で、モデルの総パラメータ量は 146B、起動パラメータ量は 22B、各エキスパートのサイズは合計 13B です。 、毎回そのうちの2つがアクティブになります。
Tiangong 3.0 は、このオープンソースには含まれていない 2 つの MoE モデル、75B (Skywork-MoE-Small) と 400B (Skywork-MoE-Large) もトレーニングしていることがわかります。 Kunlun Wanwei は、現在の主要モデルの評価リストに基づいて Skywork-MoE を評価しました。同じ 20B の起動パラメータ量 (推論計算量) の下で、Skywork-MoE の機能は 70B Dense モデルに近い業界の最前線にあります。これにより、モデルの推論コストが 3 倍近く削減されます。
Skywork-MoE の合計パラメーター サイズは DeepSeekV2 の合計パラメーター サイズより 1/3 小さく、より小さいパラメーター サイズで同様の機能を実現していることは注目に値します。技術革新
 困難な MoE モデルのトレーニングと貧弱な汎化パフォーマンスの問題を解決するために、Skywork-MoE は 2 つのトレーニング最適化アルゴリズムを設計しました:
困難な MoE モデルのトレーニングと貧弱な汎化パフォーマンスの問題を解決するために、Skywork-MoE は 2 つのトレーニング最適化アルゴリズムを設計しました:
Skywork-MoE のゲーティング正規化操作が層のトークン配布ロジックに追加されました。これにより、ゲート層のパラメータ学習が選択された上位 2 つの専門家により偏り、上位 2 の MoE モデルの信頼性が高まります:
適応型 Aux 損失
は、固定係数 (固定ハイパーパラメータ) を使用した従来の Aux 損失とは異なり、モデルが MoE トレーニングのさまざまな段階で適切な Aux 損失ハイパーパラメータ係数を適応的に選択できるため、ドロップ トークン レートを範囲内に維持できます。適切な間隔を設定すると、エキスパートの分散のバランスが取れ、エキスパートの学習を差別化できるため、モデルの全体的なパフォーマンスと汎化レベルが向上します。 MoE トレーニングの初期段階では、パラメーターの学習が不十分なため、ドロップ トークン レートが高すぎます (トークンの分布が異なりすぎます)。このとき、後の段階でトークンの負荷分散を支援するために、より大きな AUX 損失が必要になります。 Skywork-MoE チームは、ゲーティングがトークンをランダムに配布する傾向を回避するために、エキスパート間である程度の差別化が依然として確保されていることを期待しているため、修正を減らすには補助損失を低くする必要があります。 トレーニングインフラ
トレーニングインフラ

Megatron-LM コミュニティの既存の EP (Expert Parallel) および ETP (Expert Tensor Parallel) 設計とは異なり、Skywork-MoE チームは Expert Data Parallel と呼ばれる並列設計ソリューションを提案しました。この並列ソリューションは Expert When the数が少ない場合でも、モデルを効率的にセグメント化することができ、Expert によって導入された all2all 通信も最適化して最大限にマスクすることができます。 EP の GPU 数の制限やキロカード クラスタでの ETP の非効率と比較して、EDP は大規模な分散トレーニング MoE の並行する問題点をより適切に解決できます。同時に、EDP の設計はシンプルで堅牢で、拡張が容易です。迅速な実装と検証が可能です。 E 最も単純な EDP の例の 1 つ、2 枚のカードの場合、TP = 2、EP = 2、アテンション部分は Tensor Parallel を使用し、Expert 部分は Expert Parallel を使用します
最初のステージの埋め込み計算と最後のステージの損失計算、およびパイプライン バッファーの存在により、各ステージの計算負荷とビデオ メモリ負荷に明らかな不均衡が生じます。レイヤーはパイプライン並列処理の下で均等に分割されます。 Skywork-MoE チームは、全体的なコンピューティング/グラフィックス メモリ負荷のバランスをより良くし、エンドツーエンドのトレーニング スループットを約 10% 向上させるために、不均一なパイプライン並列セグメンテーションと再計算レイヤ割り当て方法を提案しました。 均一セグメンテーションと不均一セグメンテーションの下でパイプラインの並列バブルを比較します: 24 層 LLM の場合、(a) は 4 つのステージに均等に分割され、各ステージの層の数は次のとおりです: [ 6 , 6, 6, 6] は最適化された不均一分割方法であり、各ステージのレイヤー数は [5, 5, 5, 5, 4] です。中段は流水で満たされており、不均一に分割された泡はさらに低くなります。
従うことができる経験則は次のとおりです: MoE モデルのトレーニングの FLOP が Dense モデルのトレーニングの FLOP の 2 倍を超える場合は、Scratch から MoE をトレーニングすることを選択する方が良いでしょう。 MoE のトレーニングにアップサイクルを選択すると、トレーニング コストを大幅に削減できます。 
 さらに、Skywork-MoE は、どの制約がアップサイクルおよびフロムスクラッチトレーニング MoE モデルのパフォーマンスに影響を与えるかを調査するために、スケーリング則に基づいた一連の実験も実施しました。
さらに、Skywork-MoE は、どの制約がアップサイクルおよびフロムスクラッチトレーニング MoE モデルのパフォーマンスに影響を与えるかを調査するために、スケーリング則に基づいた一連の実験も実施しました。
以上が単一の 4090 推論可能、2000 億のスパース大規模モデル「Tiangong MoE」がオープンソースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

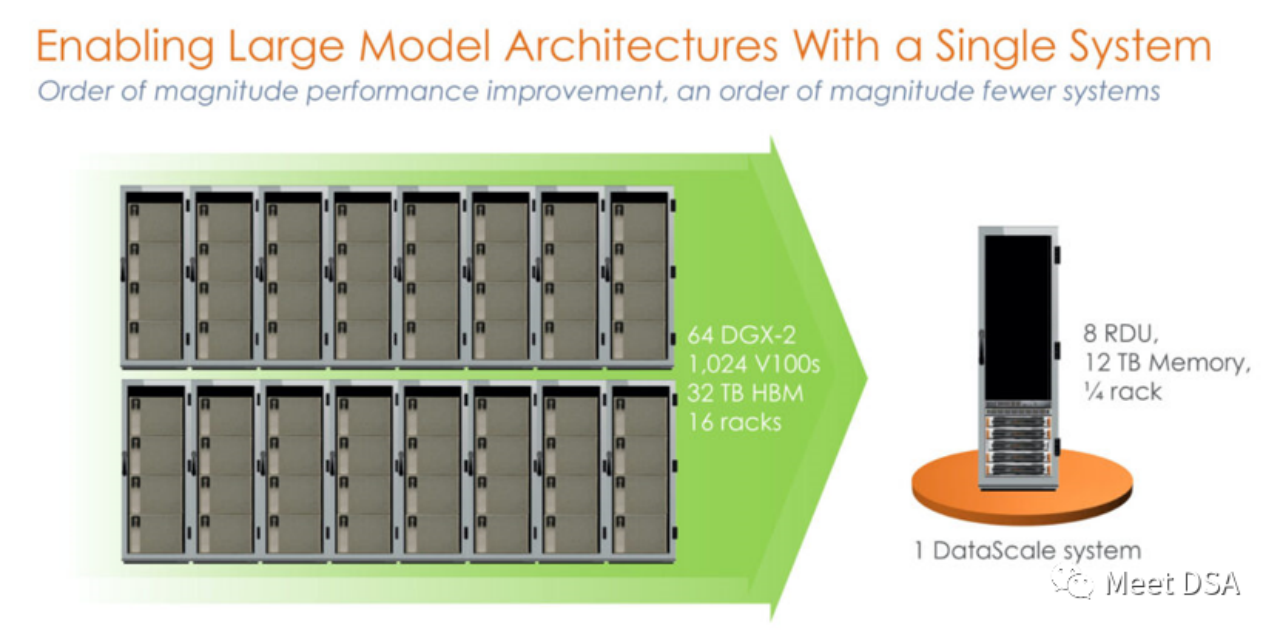 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
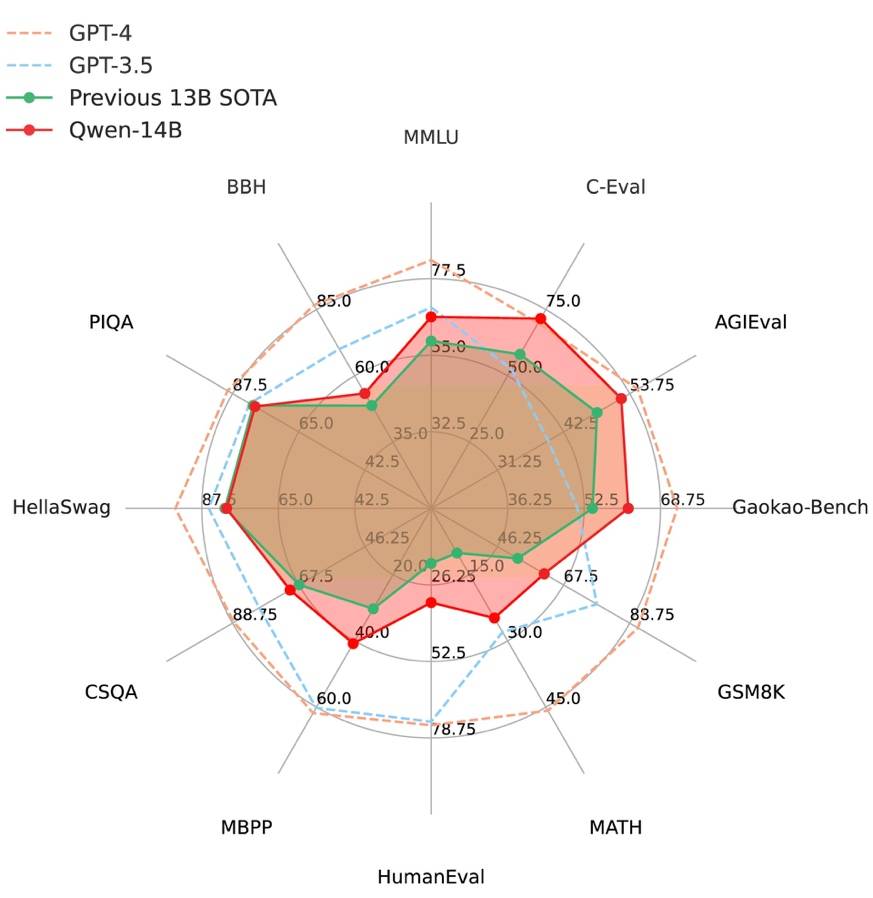 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
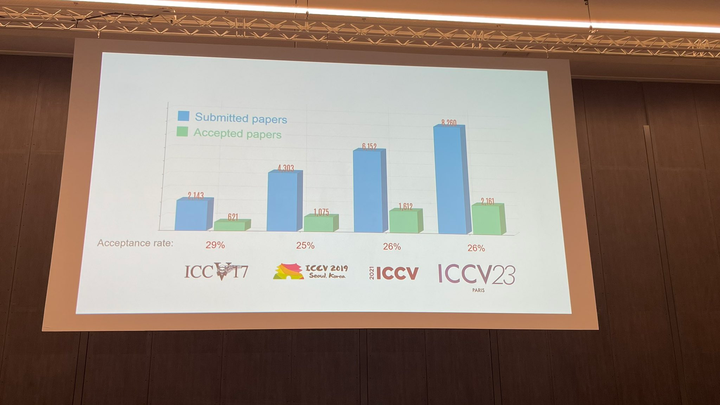 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
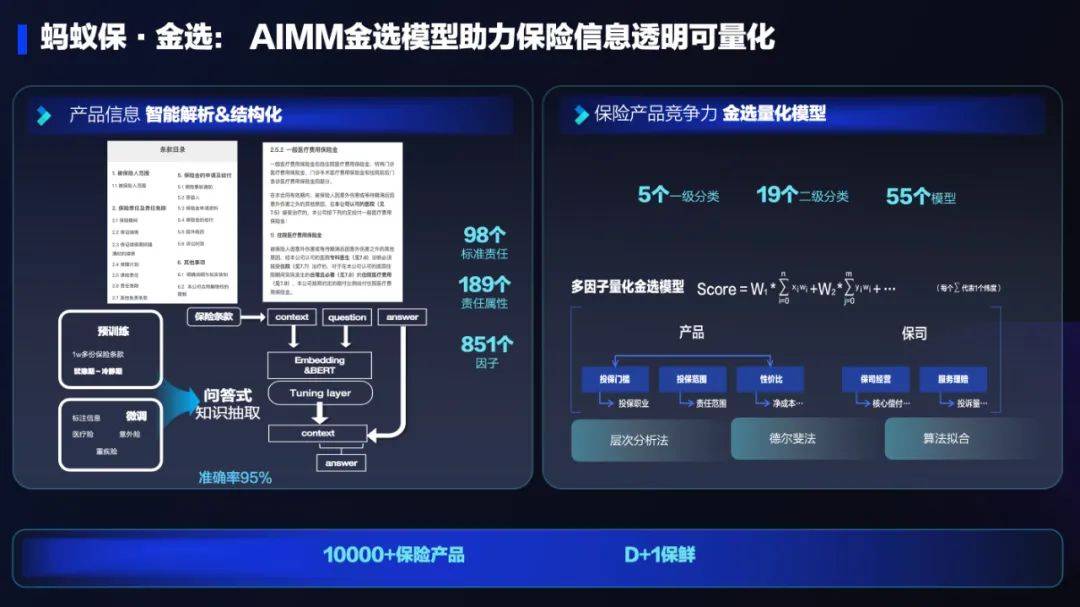 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 腾讯与中国宋庆龄基金会发布“AI编程第一课”,教育部等四部门联合推荐Sep 16, 2023 am 09:29 AM
腾讯与中国宋庆龄基金会发布“AI编程第一课”,教育部等四部门联合推荐Sep 16, 2023 am 09:29 AM腾讯与中国宋庆龄基金会合作,于9月1日发布了名为“AI编程第一课”的公益项目。该项目旨在为全国零基础的青少年提供AI和编程启蒙平台。只需在微信中搜索“腾讯AI编程第一课”,即可通过官方小程序免费体验该项目由北京师范大学任学术指导单位,邀请全球顶尖高校专家联合参研。“AI编程第一课”首批上线内容结合中国航天、未来交通两项国家重大科技议题,原创趣味探索故事,通过剧本式、“玩中学”的方式,让青少年在1小时的学习实践中认识A


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7434
7434 15135952
15135952