



AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

図 2(a): Python プログラミングでは、元のコードは正しいにもかかわらず、変数の定義と使用が異なる構文エラーに分割されています。トレーニング シーケンスに導入されると、後続のトレーニング シーケンスで一部の変数が未定義になり、モデルが間違ったパターンを学習し、下流のタスクで幻覚が発生する可能性があります。たとえば、プログラム合成タスクでは、モデルは変数を定義せずに直接使用することがあります。 図 2(b): 切り捨ても情報の完全性を損ないます。たとえば、概要内の「月曜日の朝」はトレーニング シーケンス内のどのコンテキストとも一致しないため、コンテンツが不正確になります。この種の不完全な情報により、コンテキスト情報に対するモデルの感度が大幅に低下し、生成されたコンテンツが実際の状況と不一致になる、いわゆる不忠実な生成が発生します。 図 2(c): テキスト内の知識の表現は完全な文または段落に依存することが多いため、切り捨てはトレーニング中の知識の獲得も妨げます。たとえば、会議名と場所は異なるトレーニング シーケンスに分散されているため、モデルは ICML 会議の場所を学習できません。
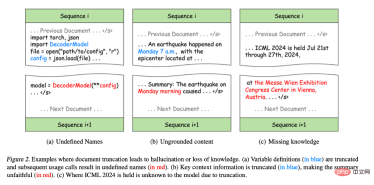
図 2. 錯覚や知識の喪失につながる文書の切り捨ての例。 (a) 変数定義 (青色の部分) が切り詰められ、後続の使用呼び出しでは未定義の名前 (赤色の部分) が生成されます。 (b) 重要なコンテキスト情報が切り詰められているため (青色の部分)、要約は元のテキスト (赤色の部分) よりも正確さが低くなります。 (c) 切り捨てのため、モデルでは ICML 2024 がどこで開催されるかがわかりません。





対照的に、珍しい
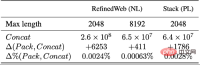
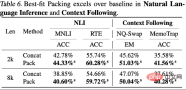
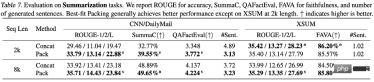
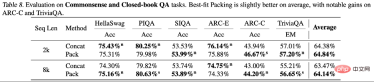
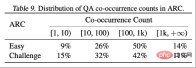
ARC-C と ARC-E の 2 つのテスト セットの結果を分析することにより、研究者らは、より一般的な知識を含む ARC-E と比較して、最適な適応パッケージングを使用すると、モデルの包含性が向上することを発見しました。 ARC-C では、末尾の知識が増えると、パフォーマンスがさらに大幅に向上します。
この発見は、Kandpal et al (2023) によって前処理された Wikipedia エンティティ マップ内の各質問と回答のペアの共起数をカウントすることでさらに検証されます。統計結果は、チャレンジ セット (ARC-C) にはより稀な共起ペアが含まれていることを示しており、最適な適応パッケージングがテール知識学習を効果的にサポートできるという仮説を検証し、従来の大規模言語モデルがロングテールを学習できない理由も説明しています。知識は、遭遇する困難についての説明を提供します。
この記事では、大規模言語モデルのトレーニングにおける一般的なドキュメントの切り捨ての問題を提起します。
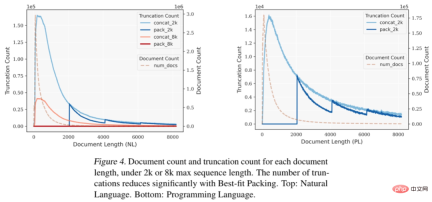
この切り捨て効果は、論理的一貫性と事実の一貫性を学習するモデルの能力に影響を与え、生成プロセス中の幻覚現象を増加させます。著者らは、データの並べ替えプロセスを最適化することで各文書の完全性を最大化するベストフィット パッキングを提案しました。この方法は、数十億のドキュメントを含む大規模なデータセットの処理に適しているだけでなく、データのコンパクトさの点でも従来の方法と同等です。
実験結果は、この方法が不必要な切り捨てを減らすのに非常に効果的であり、さまざまなテキストおよびコードタスクでモデルのパフォーマンスを大幅に向上させ、閉じたドメインでの言語生成の錯覚を効果的に軽減できることを示しています。この論文の実験は主に事前トレーニング段階に焦点を当てていますが、最適な適応パッケージングは微調整などの他の段階でも広く使用できます。この研究は、より効率的で信頼性の高い言語モデルの開発に貢献し、言語モデルのトレーニング技術の開発を前進させます。
研究の詳細については、原論文をご覧ください。仕事やインターンシップに興味がある場合は、この記事の著者に電子メール (zijwan@amazon.com) でご連絡ください。
以上がICML 2024 | 大規模言語モデルの事前トレーニングの新境地: 「ベスト アダプテーション パッケージング」が文書処理標準を再構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 効果的な加速主義または向社会的AI。 AIの未来は何ですか?Apr 16, 2025 am 11:09 AM
効果的な加速主義または向社会的AI。 AIの未来は何ですか?Apr 16, 2025 am 11:09 AMアクセラレーション主義者のビジョン:フルスピード先 略してE/ACCとして知られる効果的な加速主義は、2022年頃に、シリコンバレー以降で、その中核で著しく大幅な牽引力を獲得している技術的な最適主義運動として出現しました。
 Excelの相対的、絶対的、混合参照とは何ですか?Apr 16, 2025 am 11:03 AM
Excelの相対的、絶対的、混合参照とは何ですか?Apr 16, 2025 am 11:03 AM導入 私の最初のスプレッドシートの経験は、コピーしたときにフォーミュラの予測不可能な動作のためにイライラしていました。 私はその時のセルの参照を理解していませんでしたが、相対的、絶対的、混合された参照をマスターすることは私のスプレッドに革命をもたらしました
 Word2vecを使用したスマートサブジェクトの電子メールラインの生成Apr 16, 2025 am 11:01 AM
Word2vecを使用したスマートサブジェクトの電子メールラインの生成Apr 16, 2025 am 11:01 AMこの記事では、Word2VECエンボードを使用して効果的な電子メールの件名を生成する方法を示しています。 セマンティックな類似性を活用して、コンテキストに関連する件名を作成し、電子メールマーケティングを改善するシステムを構築することでガイドします。
 データアナリストの将来Apr 16, 2025 am 11:00 AM
データアナリストの将来Apr 16, 2025 am 11:00 AMデータ分析:進化する風景のナビゲート データが数字だけでなく、すべての経営陣の決定の礎石を想像してください。 この動的環境では、データアナリストは不可欠であり、生データを実行可能に変換します
 Excelの等式機能は何ですか? - 分析VidhyaApr 16, 2025 am 10:55 AM
Excelの等式機能は何ですか? - 分析VidhyaApr 16, 2025 am 10:55 AMExcelの等式関数:データ分析パワーハウス 合理化されたデータ分析のためのExcelの等式関数の力のロックを解除します。この汎用性のある関数は、合計と乗算機能を簡単に組み合わせて、追加に拡張し、減算
 データスクラビングとは何ですか?Apr 16, 2025 am 10:53 AM
データスクラビングとは何ですか?Apr 16, 2025 am 10:53 AMデータクレンジング:情報に基づいた意思決定のためのデータの正確性と信頼性を確保する 不正確なゲストリストで大家族の再会を計画していると想像してください。 準備が不十分なリストは、イベントを台無しにする可能性があります。 同様に
 chattts:テキストをスピーチに変えますApr 16, 2025 am 10:51 AM
chattts:テキストをスピーチに変えますApr 16, 2025 am 10:51 AMChattts:リアルな会話でテキストからスピーチに革命をもたらす 会話的に自然なオーディオでポッドキャストまたは仮想アシスタントを作成することを想像してください。 最先端のテキストからスピーチ(TTS)ツールであるChatttsは、書かれたテキストを著しくrに変換します
 データサイエンス分析Vidhyaにおけるキャンパス配置のためのヒントApr 16, 2025 am 10:40 AM
データサイエンス分析Vidhyaにおけるキャンパス配置のためのヒントApr 16, 2025 am 10:40 AMあなたの夢のデータ科学の仕事を着陸:キャンパスプレースメントガイド 毎年恒例の配置シーズンはこちらです! ジョブハントに圧倒されたと感じていますか?心配しないでください、あなたは一人ではありません。 完璧なデータサイエンスの役割を見つけるのは気が遠くなる可能性がありますが、戦略的アプローチc


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

