
ホームページ >ウェブフロントエンド >jsチュートリアル >JavaScript 配列 deduplication_javascript スキルの 3 つのメソッドのパフォーマンス テストと比較
JavaScript 配列 deduplication_javascript スキルの 3 つのメソッドのパフォーマンス テストと比較

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 17:39:131164ブラウズ
昨日参加したフロントエンドのインタビューで、配列の重複排除に関する質問があり、最初に思いついたのは、キーの値をオブジェクトに格納する方法です。コードは次のとおりです。
方法 1: (単純なキー値の保存)
コードをコピー コードは次のとおりです:
Array.prototype.distinct1 = function() {
var i=0 ,tmp={},that=this.slice(0)
this.length=0
for(;i< ;that.length;i ){
if(!(that[i] in tmp)){
this[this.length]=that[i];
tmp[that[i]]= true;
}
}
return this
} ;
上記のメソッドは複雑ではなく、考え方は単純ですが、さまざまなタイプについては同じ文字列に変換できる場合は、1 と "1" のように終了します。したがって、従来の方法が再度使用されます。二重ループ、コードは次のとおりです
方法 2: (二重ループ)
コードをコピーします コードは次のとおりです:
Array.prototype.distinct2 = function () {
var i=0,flag,that=this.slice(0);
for(;i
flag=true;
for(var j=0;j
}
if(flag)this[this.length]=tmp;
}
これを返します;
上記メソッドは目的の結果を取得しましたが、2 層のループ効率は比較的低くなります。最初のメソッドから始めて、文字列を追加して配列項目の型を保存します。新しい型がある場合は接続します。検索時に保存された型を見つけた場合は、その文字列を空に置き換えます。
方法 3 : (キーの値と型を保存する)
コードをコピー コードは次のとおりです。
Array .prototype.distinct4 = function() { var i=0,tmp={},t2,that=this.slice(0),one;
this.length=0; ione=that[i];
t2=typeof one;
this[this.length]= one; ]=t2;
}else if(tmp[one].indexOf(t2)==-1){
this[this.length]=one;
tmp [one] =t2; >}
}
return this;
};
異なるデータに対するさまざまなアルゴリズム間の効率の差を区別するには、まず、極端な例で確認します。配列の1から80まで全てが異なっていて1000回ループした状況では、まあIE6は弱いですね
。
IE9:
this.length=0; i
t2=typeof one;
this[this.length]= one; ]=t2;
}else if(tmp[one].indexOf(t2)==-1){
this[this.length]=one;
tmp [one] =t2; >}
}
return this;
};
異なるデータに対するさまざまなアルゴリズム間の効率の差を区別するには、まず、極端な例で確認します。配列の1から80まで全てが異なっていて1000回ループした状況では、まあIE6は弱いですね
。
IE9:
Chrome: 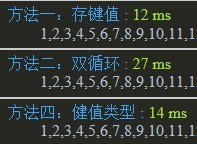 Firefox:
Firefox: IE6:
IE6: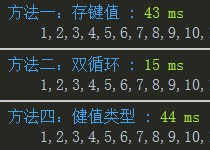 上記のデータを元に、80 項目すべてを 1000 回繰り返した場合は次のようになります。 IE6-8 と他のブラウザの二重ループのパフォーマンスは良好ですが、IE6-8 の二重ループは約 10 ~ 20 倍遅く、悲しいことがわかりました。 Web サイトが IE9 以降のみをサポートしている場合は、安心して二重ループ方式を使用できます。それ以外の場合は、データの状況に応じて方式 1 または方式 3 を使用する必要があります (図の方式 4)。画像を変更するには遅すぎることがわかりました。元の 3 番目の方法は Array の IndexOf を使用することでしたが、速度が遅く互換性がないためリリースされませんでした)
上記のデータを元に、80 項目すべてを 1000 回繰り返した場合は次のようになります。 IE6-8 と他のブラウザの二重ループのパフォーマンスは良好ですが、IE6-8 の二重ループは約 10 ~ 20 倍遅く、悲しいことがわかりました。 Web サイトが IE9 以降のみをサポートしている場合は、安心して二重ループ方式を使用できます。それ以外の場合は、データの状況に応じて方式 1 または方式 3 を使用する必要があります (図の方式 4)。画像を変更するには遅すぎることがわかりました。元の 3 番目の方法は Array の IndexOf を使用することでしたが、速度が遅く互換性がないためリリースされませんでした)
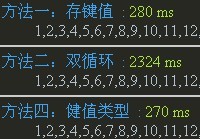
Chrome:
Firefox: IE6: 

声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。