
ホームページ >ウェブフロントエンド >jsチュートリアル >データ構造分析より: for each...in を使用した方が for...in よりも高速です_基礎知識
データ構造分析より: for each...in を使用した方が for...in よりも高速です_基礎知識

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 17:36:51998ブラウズ
Firefox の JS エンジンは、次のコードのような構文で for each をサポートしていると聞きました:
var arr = [10,20,30,40,50];
for each(var k in arr)
console.log(k );
は、arr 配列の内容を直接走査できます。
FireFox のみがこの機能をサポートしているため、ほとんどすべての JS コードはこの機能を使用しません。
ただし、ActionScript は本質的に for each 構文をサポートしており、配列、ベクトル、辞書に関係なく、列挙可能なオブジェクトである限り、for in および for each in を使用できます。
以前は、「each」という単語を入力するのが面倒だったので、いつも使い慣れた for in を使って横断していました。
でも、今日よく考えてデータ構造の観点から分析してみると、JSでもASでも、for inとfor each inでは根本的に効率が違うような気がします。
理由は簡単です。配列は本当の意味での配列ではありません。
配列の本当の意味は何ですか?もちろん、これは従来の言語で type[] で定義されたデータ型であり、すべての要素が継続的に保存されます。
「配列」は配列という意味もありますが、JS に詳しい人は、これが実際には非線形の擬似配列であり、添え字は任意の数であることを知っています。 arr[1000000] と記述すると、実際には 100 万要素を収容するためのスペースが適用されませんが、1000000 が対応するハッシュ値に変換され、小さな記憶スペースに相当するため、メモリが大幅に節約されます。
たとえば、次の配列があります:
var arr = [ ];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000;
arr[200] = 9000;
for...in を使用して配列を走査するのは、非常に面倒なプロセスです。
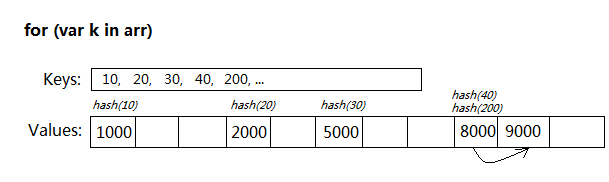
トラバーサル中に arr[k] がアクセスされるたびに、Hash(k) 計算が実行され、ハッシュ テーブルの容量に従ってモジュロが取得され、その結果が最終的に競合リンク リストで見つかります。
for each...in 構文がサポートされている場合、その内部データ構造により、はるかに高速になることが決定されます。
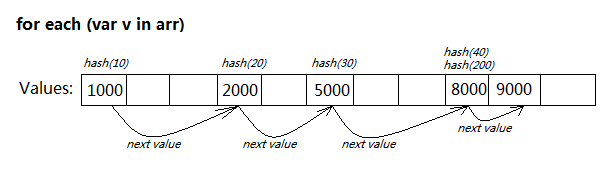
配列はキーのリストを格納し、各値をリンクされたリストとして関連付けます。値が追加または削除されるたびに、そのリンク関係が更新されます。
for each...in をトラバースする場合、ハッシュ計算を行わずに、最初のノードから逆方向に反復するだけで済みます。
もちろん、AS3 の Vector などの線形配列の場合、両者に大きな違いはありません。同様に、HTML5 のバイナリ配列 ArrayBuffer にも同じことが当てはまります。ただし、理論的な観点から見ると、たとえ arr が連続線形配列であっても、各 in の方が依然として高速です:
for...in をトラバースする場合、arr[k] にアクセスするたびに添え字の範囲外チェックを実行する必要があります。一方、各 in について、反復変数は以下に基づいて最下層から直接フィードバックされます。内部リンク リストを使用して、範囲外チェックのプロセスを節約します。