


之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用。
为什么要使用Cookie呢?
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
在此之前呢,我们必须先介绍一个opener的概念。
1.Opener
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
2.Cookielib
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
1)获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们使用以上方法将cookie保存到变量中,然后打印出了cookie中的值,运行结果如下
Name = BAIDUID Value = B07B663B645729F11F659C02AAE65B4C:FG=1 Name = BAIDUPSID Value = B07B663B645729F11F659C02AAE65B4C Name = H_PS_PSSID Value = 12527_11076_1438_10633 Name = BDSVRTM Value = 0 Name = BD_HOME Value = 0
2)保存Cookie到文件
在上面的方法中,我们将cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中该怎么做呢?这时,我们就要用到
FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存
import cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
关于最后save方法的两个参数在此说明一下:
官方解释如下:
ignore_discard: save even cookies set to be discarded.
ignore_expires: save even cookies that have expiredThe file is overwritten if it already exists
由此可见,ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中,我们查看一下内容,附图如下
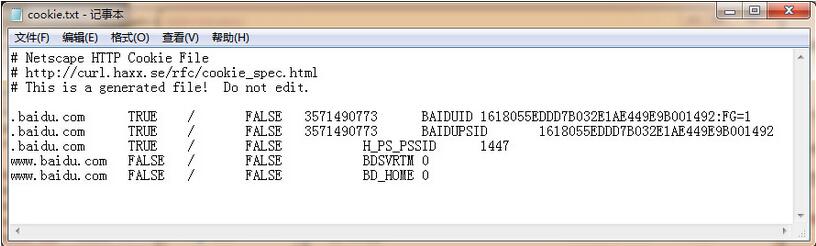
3)从文件中获取Cookie并访问
那么我们已经做到把Cookie保存到文件中了,如果以后想使用,可以利用下面的方法来读取cookie并访问网站,感受一下
import cookielib
import urllib2
#创建MozillaCookieJar实例对象
cookie = cookielib.MozillaCookieJar()
#从文件中读取cookie内容到变量
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
#创建请求的request
req = urllib2.Request("http://www.baidu.com")
#利用urllib2的build_opener方法创建一个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open(req)
print response.read()
设想,如果我们的 cookie.txt 文件中保存的是某个人登录百度的cookie,那么我们提取出这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
4)利用cookie模拟网站登录
下面我们以我们学校的教育系统为例,利用cookie实现模拟登录,并将cookie信息保存到文本文件中,来感受一下cookie大法吧!
注意:密码我改了啊,别偷偷登录本宫的选课系统 o(╯□╰)o
import urllib
import urllib2
import cookielib
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'23342321'
})
#登录教务系统的URL
loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
#模拟登录,并把cookie保存到变量
result = opener.open(loginUrl,postdata)
#保存cookie到cookie.txt中
cookie.save(ignore_discard=True, ignore_expires=True)
#利用cookie请求访问另一个网址,此网址是成绩查询网址
gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'
#请求访问成绩查询网址
result = opener.open(gradeUrl)
print result.read()
以上程序的原理如下
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
如登录之后才能查看的成绩查询呀,本学期课表呀等等网址,模拟登录就这么实现啦,是不是很酷炫?
好,小伙伴们要加油哦!我们现在可以顺利获取网站信息了,接下来就是把网站里面有效内容提取出来,下一篇文章我们去会会正则表达式!

 Python vs. C:重要な違いを理解しますApr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解しますApr 21, 2025 am 12:18 AMPythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
 Python vs. C:プロジェクトのためにどの言語を選択しますか?Apr 21, 2025 am 12:17 AM
Python vs. C:プロジェクトのためにどの言語を選択しますか?Apr 21, 2025 am 12:17 AMPythonまたはCの選択は、プロジェクトの要件に依存します。1)迅速な開発、データ処理、およびプロトタイプ設計が必要な場合は、Pythonを選択します。 2)高性能、低レイテンシ、および緊密なハードウェアコントロールが必要な場合は、Cを選択します。
 Pythonの目標に到達する:毎日2時間のパワーApr 20, 2025 am 12:21 AM
Pythonの目標に到達する:毎日2時間のパワーApr 20, 2025 am 12:21 AM毎日2時間のPython学習を投資することで、プログラミングスキルを効果的に改善できます。 1.新しい知識を学ぶ:ドキュメントを読むか、チュートリアルを見る。 2。練習:コードと完全な演習を書きます。 3。レビュー:学んだコンテンツを統合します。 4。プロジェクトの実践:実際のプロジェクトで学んだことを適用します。このような構造化された学習計画は、Pythonを体系的にマスターし、キャリア目標を達成するのに役立ちます。
 2時間の最大化:効果的なPython学習戦略Apr 20, 2025 am 12:20 AM
2時間の最大化:効果的なPython学習戦略Apr 20, 2025 am 12:20 AM2時間以内にPythonを効率的に学習する方法は次のとおりです。1。基本的な知識を確認し、Pythonのインストールと基本的な構文に精通していることを確認します。 2。変数、リスト、関数など、Pythonのコア概念を理解します。 3.例を使用して、基本的および高度な使用をマスターします。 4.一般的なエラーとデバッグテクニックを学習します。 5.リストの概念を使用したり、PEP8スタイルガイドに従ったりするなど、パフォーマンスの最適化とベストプラクティスを適用します。
 PythonとCのどちらかを選択:あなたに適した言語Apr 20, 2025 am 12:20 AM
PythonとCのどちらかを選択:あなたに適した言語Apr 20, 2025 am 12:20 AMPythonは初心者やデータサイエンスに適しており、Cはシステムプログラミングとゲーム開発に適しています。 1. Pythonはシンプルで使いやすく、データサイエンスやWeb開発に適しています。 2.Cは、ゲーム開発とシステムプログラミングに適した、高性能と制御を提供します。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Python vs. C:プログラミング言語の比較分析Apr 20, 2025 am 12:14 AM
Python vs. C:プログラミング言語の比較分析Apr 20, 2025 am 12:14 AMPythonはデータサイエンスと迅速な発展により適していますが、Cは高性能およびシステムプログラミングにより適しています。 1. Python構文は簡潔で学習しやすく、データ処理と科学的コンピューティングに適しています。 2.Cには複雑な構文がありますが、優れたパフォーマンスがあり、ゲーム開発とシステムプログラミングでよく使用されます。
 1日2時間:Python学習の可能性Apr 20, 2025 am 12:14 AM
1日2時間:Python学習の可能性Apr 20, 2025 am 12:14 AMPythonを学ぶために1日2時間投資することは可能です。 1.新しい知識を学ぶ:リストや辞書など、1時間で新しい概念を学びます。 2。練習と練習:1時間を使用して、小さなプログラムを書くなどのプログラミング演習を実行します。合理的な計画と忍耐力を通じて、Pythonのコアコンセプトを短時間で習得できます。
 Python vs. C:曲線と使いやすさの学習Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習Apr 19, 2025 am 12:20 AMPythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

