


先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下:

只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF!
所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少。
最后实现的功能:
1、输入要爬取的微博用户的user_id,获得该用户的所有微博
2、文字内容保存到以%user_id命名文本文件中,所有高清原图保存在weibo_image文件夹中
具体操作:
首先我们要获得自己的cookie,这里只说chrome的获取方法。
1、用chrome打开新浪微博移动端
2、option+command+i调出开发者工具
3、点开Network,将Preserve log选项选中
4、输入账号密码,登录新浪微博
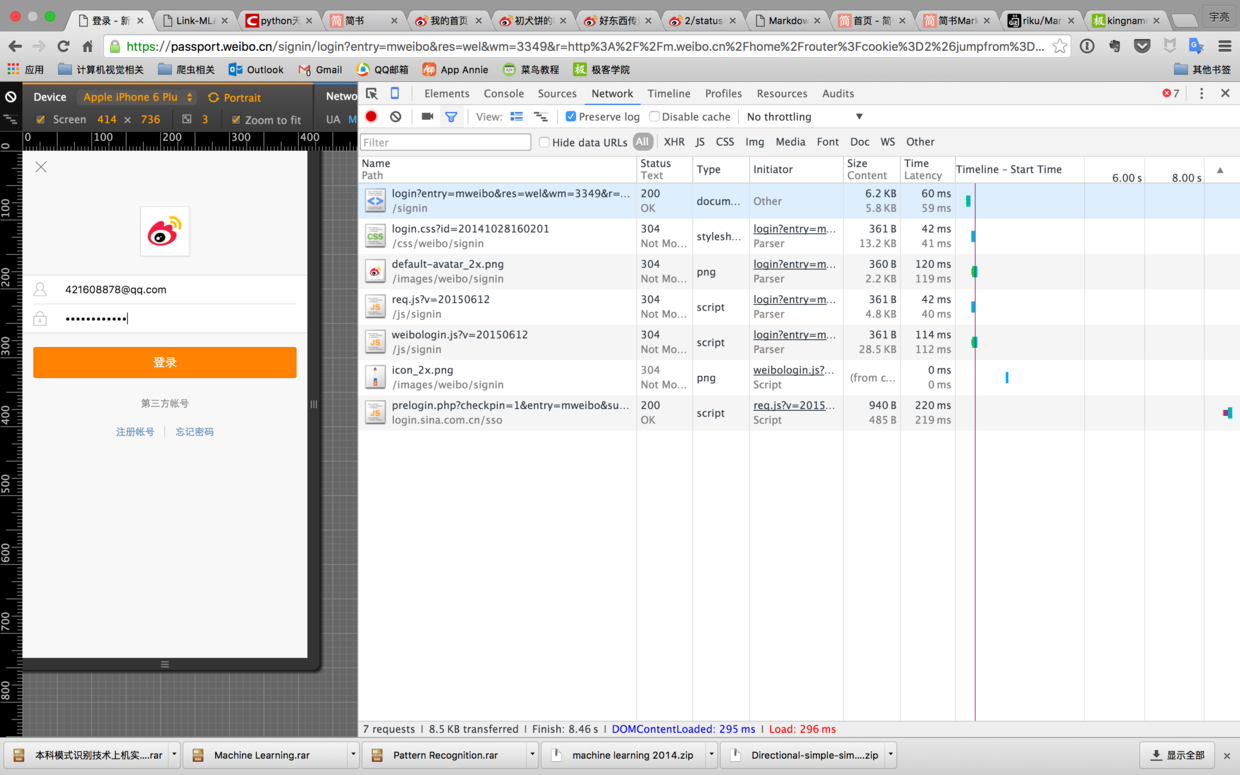
5、找到m.weibo.cn->Headers->Cookie,把cookie复制到代码中的#your cookie处
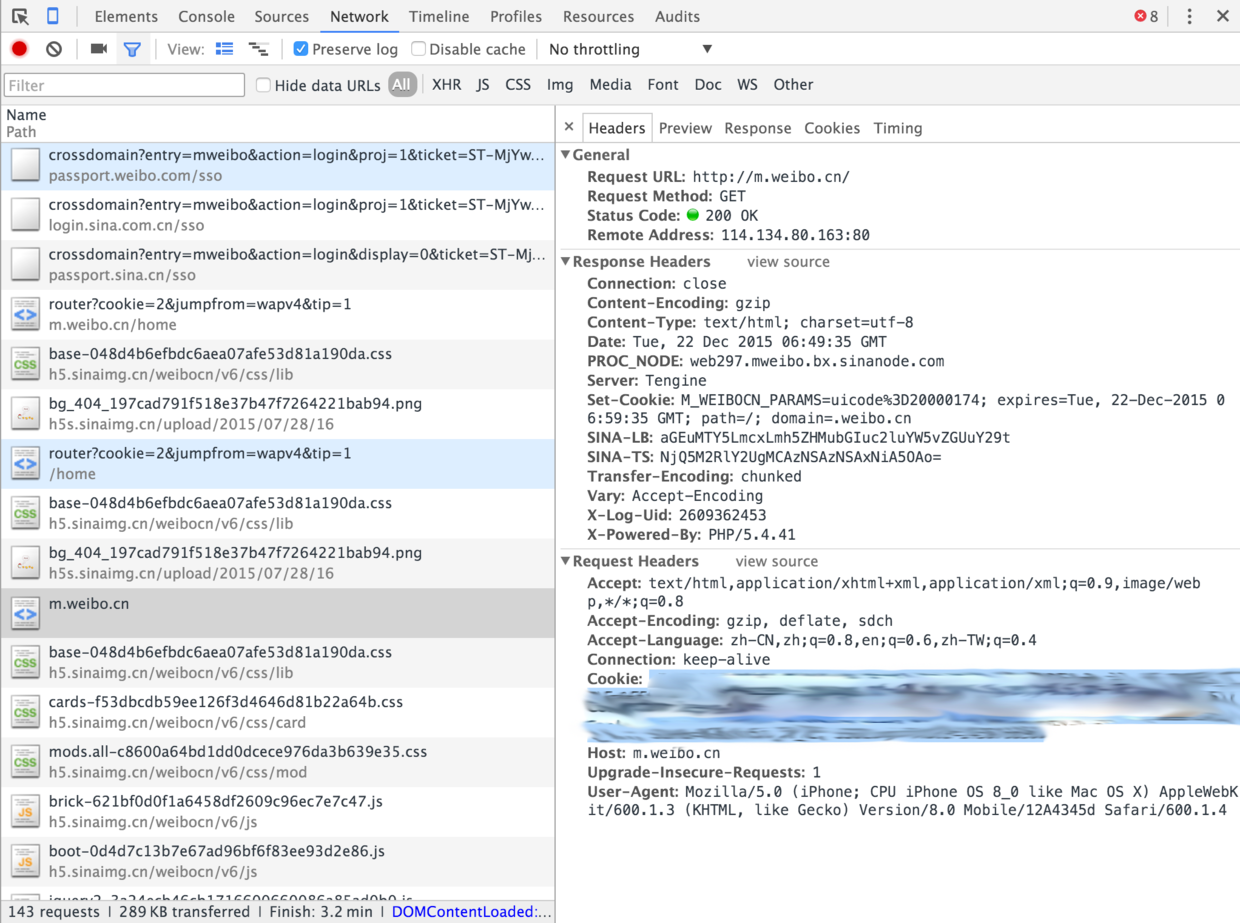
然后再获取你想爬取的用户的user_id,这个我不用多说啥了吧,点开用户主页,地址栏里面那个号码就是user_id
将python代码保存到weibo_spider.py文件中
定位到当前目录下后,命令行执行python weibo_spider.py user_id
当然如果你忘记在后面加user_id,执行的时候命令行也会提示你输入
最后执行结束
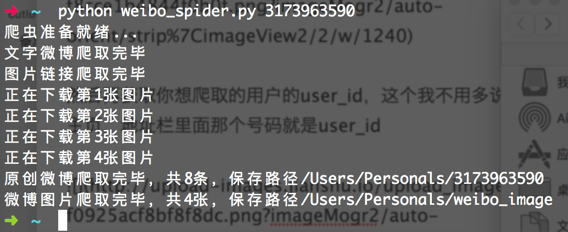
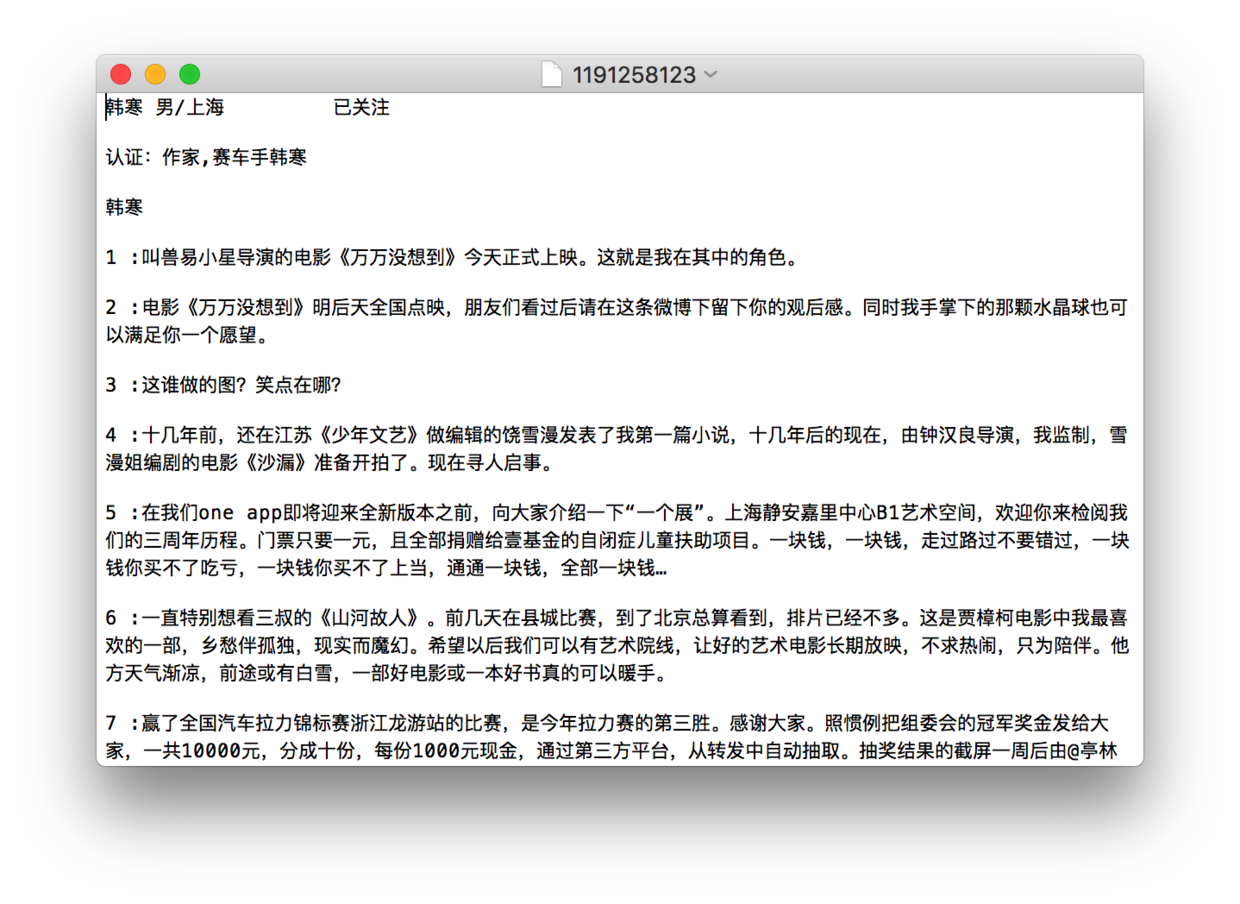
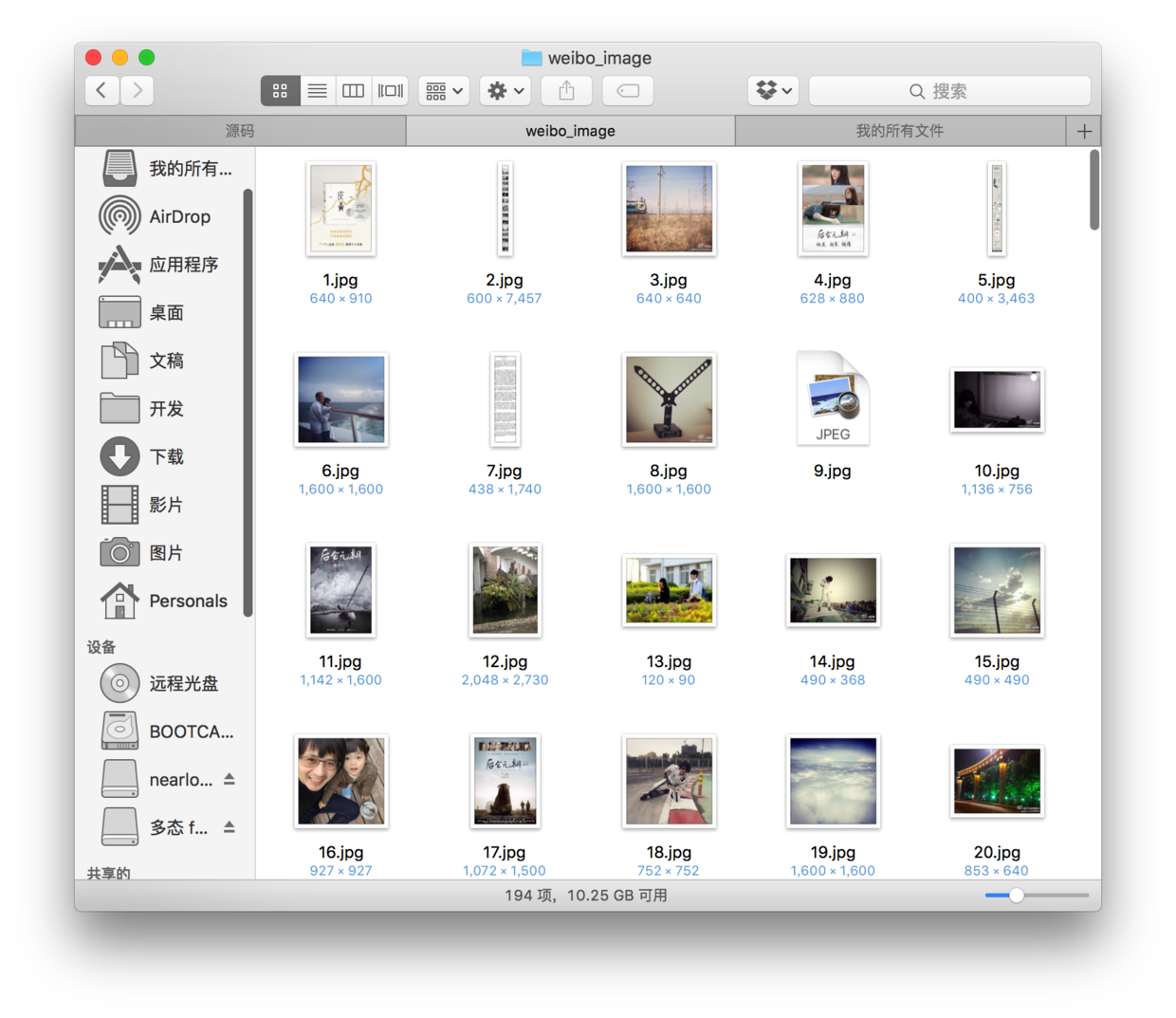
小问题:在我的测试中,有的时候会出现图片下载失败的问题,具体原因还不是很清楚,可能是网速问题,因为我宿舍的网速实在太不稳定了,当然也有可能是别的问题,所以在程序根目录下面,我还生成了一个userid_imageurls的文本文件,里面存储了爬取的所有图片的下载链接,如果出现大片的图片下载失败,可以将该链接群一股脑导进迅雷等下载工具进行下载。
另外,我的系统是OSX EI Capitan10.11.2,Python的版本是2.7,依赖库用sudo pip install XXXX就可以安装,具体配置问题可以自行stackoverflow,这里就不展开讲了。
下面我就给出实现代码
#-*-coding:utf8-*-
import re
import string
import sys
import os
import urllib
import urllib2
from bs4 import BeautifulSoup
import requests
from lxml import etree
reload(sys)
sys.setdefaultencoding('utf-8')
if(len(sys.argv)>=2):
user_id = (int)(sys.argv[1])
else:
user_id = (int)(raw_input(u"请输入user_id: "))
cookie = {"Cookie": "#your cookie"}
url = 'http://weibo.cn/u/%d?filter=1&page=1'%user_id
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum = (int)(selector.xpath('//input[@name="mp"]')[0].attrib['value'])
result = ""
urllist_set = set()
word_count = 1
image_count = 1
print u'爬虫准备就绪...'
for page in range(1,pageNum+1):
#获取lxml页面
url = 'http://weibo.cn/u/%d?filter=1&page=%d'%(user_id,page)
lxml = requests.get(url, cookies = cookie).content
#文字爬取
selector = etree.HTML(lxml)
content = selector.xpath('//span[@class="ctt"]')
for each in content:
text = each.xpath('string(.)')
if word_count>=4:
text = "%d :"%(word_count-3) +text+"\n\n"
else :
text = text+"\n\n"
result = result + text
word_count += 1
#图片爬取
soup = BeautifulSoup(lxml, "lxml")
urllist = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first = 0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url)
image_count +=1
fo = open("/Users/Personals/%s"%user_id, "wb")
fo.write(result)
word_path=os.getcwd()+'/%d'%user_id
print u'文字微博爬取完毕'
link = ""
fo2 = open("/Users/Personals/%s_imageurls"%user_id, "wb")
for eachlink in urllist_set:
link = link + eachlink +"\n"
fo2.write(link)
print u'图片链接爬取完毕'
if not urllist_set:
print u'该页面中不存在图片'
else:
#下载图片,保存在当前目录的pythonimg文件夹下
image_path=os.getcwd()+'/weibo_image'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp= image_path + '/%s.jpg' % x
print u'正在下载第%s张图片' % x
try:
urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp)
except:
print u"该图片下载失败:%s"%imgurl
x+=1
print u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path)
print u'微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path)
一个简单的微博爬虫就完成了,希望对大家的学习有所帮助。

 Pythonの2つのリストを連結する代替品は何ですか?May 09, 2025 am 12:16 AM
Pythonの2つのリストを連結する代替品は何ですか?May 09, 2025 am 12:16 AMPythonに2つのリストを接続する多くの方法があります。1。オペレーターを使用しますが、これはシンプルですが、大きなリストでは非効率的です。 2。効率的ですが、元のリストを変更する拡張メソッドを使用します。 3。=演算子を使用します。これは効率的で読み取り可能です。 4。itertools.chain関数を使用します。これはメモリ効率が高いが、追加のインポートが必要です。 5。リストの解析を使用します。これはエレガントですが、複雑すぎる場合があります。選択方法は、コードのコンテキストと要件に基づいている必要があります。
 Python:2つのリストをマージする効率的な方法May 09, 2025 am 12:15 AM
Python:2つのリストをマージする効率的な方法May 09, 2025 am 12:15 AMPythonリストをマージするには多くの方法があります。1。オペレーターを使用します。オペレーターは、シンプルですが、大きなリストではメモリ効率的ではありません。 2。効率的ですが、元のリストを変更する拡張メソッドを使用します。 3. Itertools.chainを使用します。これは、大規模なデータセットに適しています。 4.使用 *オペレーター、1つのコードで小規模から中型のリストをマージします。 5. numpy.concatenateを使用します。これは、パフォーマンス要件の高い大規模なデータセットとシナリオに適しています。 6.小さなリストに適したが、非効率的な追加方法を使用します。メソッドを選択するときは、リストのサイズとアプリケーションのシナリオを考慮する必要があります。
 コンパイルされた通信言語:長所と短所May 09, 2025 am 12:06 AM
コンパイルされた通信言語:長所と短所May 09, 2025 am 12:06 AMcompiledlanguagesOfferspeedandsecurity、foredlanguagesprovideeaseofuseandportability.1)compiledlanguageslikec arefasterandsecurebuthavelOnderdevelopmentsplat dependency.2)
 Python:ループのために、そして最も完全なガイドMay 09, 2025 am 12:05 AM
Python:ループのために、そして最も完全なガイドMay 09, 2025 am 12:05 AMPythonでは、forループは反復可能なオブジェクトを通過するために使用され、条件が満たされたときに操作を繰り返し実行するためにしばらくループが使用されます。 1)ループの例:リストを通過し、要素を印刷します。 2)ループの例:正しいと推測するまで、数値ゲームを推測します。マスタリングサイクルの原則と最適化手法は、コードの効率と信頼性を向上させることができます。
 Python concatenateリストを文字列に入れますMay 09, 2025 am 12:02 AM
Python concatenateリストを文字列に入れますMay 09, 2025 am 12:02 AMリストを文字列に連結するには、PythonのJoin()メソッドを使用して最良の選択です。 1)join()メソッドを使用して、 '' .join(my_list)などのリスト要素を文字列に連結します。 2)数字を含むリストの場合、連結する前にマップ(str、数字)を文字列に変換します。 3) '、'などの複雑なフォーマットに発電機式を使用できます。 4)混合データ型を処理するときは、MAP(STR、Mixed_List)を使用して、すべての要素を文字列に変換できるようにします。 5)大規模なリストには、 '' .join(lage_li)を使用します
 Pythonのハイブリッドアプローチ:コンピレーションと解釈を組み合わせたMay 08, 2025 am 12:16 AM
Pythonのハイブリッドアプローチ:コンピレーションと解釈を組み合わせたMay 08, 2025 am 12:16 AMpythonusesahybridapproach、コンコイリティレーショントビテコードと解釈を組み合わせて、コードコンピレッドフォームと非依存性bytecode.2)
 Pythonの「for」と「while」ループの違いを学びますMay 08, 2025 am 12:11 AM
Pythonの「for」と「while」ループの違いを学びますMay 08, 2025 am 12:11 AMkeydifferencesは、「for」と「while "loopsare:1)" for "for" loopsareideal forterating overencesonownowiterations、while2) "for" for "for" for "for" for "for" for "for" for for for for "wide" loopsarebetterunuinguntinunuinguntinisisisisisisisisisisisisisisisisisisisisisisisisisisisations.un
 重複したPython ConcatenateリストMay 08, 2025 am 12:09 AM
重複したPython ConcatenateリストMay 08, 2025 am 12:09 AMPythonでは、さまざまな方法でリストを接続して重複要素を管理できます。1)オペレーターを使用するか、すべての重複要素を保持します。 2)セットに変換してから、リストに戻ってすべての重複要素を削除しますが、元の順序は失われます。 3)ループを使用するか、包含をリストしてセットを組み合わせて重複要素を削除し、元の順序を維持します。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

メモ帳++7.3.1
使いやすく無料のコードエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

