



Mahout简介 Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序 Mahout相关资源 Mahout主页:http://mahout.apache.org/ Mahout 最新版本0.8下
Mahout简介
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序
Mahout相关资源
- Mahout主页:http://mahout.apache.org/
- Mahout 最新版本0.8下载:?http://mirrors.hust.edu.cn/apache/mahout/0.8/?使用mahout-distribution-0.8.tar.gz可试跑,源码在mahout-distribution-0.8-src.tar.gz中
- Mahout 简要安装步骤:
如无需修改源代码,只是试用试跑,请无需安装maven(网上许多教程会有这个弯路,请跳过),具体可以参考以下教程
http://www.hadoopor.com/thread-983-1-1.html
如果需要能修改源代码并重新编译打包,需要安装maven,请参考如下图文教程:http://wenku.baidu.com/view/dbd15bd276a20029bd642d55.html
- Mahout 专业教程 : Mahout in action?http://yunpan.taobao.com/share/link/R56BdLH5O
注: 出版时间2012年, 对应mahout版本0.5, 是目前mahout最新的书籍读物。目前只有英文版,但是翻了一下,里面词汇基本都是计算机基础词汇,且配图和源代码,是适合阅读的。
- IBM mahout简介:?http://www.ibm.com/developerworks/cn/java/j-mahout/
注:中文版, 更新是时间为09年,但是里面对于mahout阐述较全面,推荐阅读,特别是最后的书籍清单,适合深入了解
Mahout模块详解
- Mahout模块详解
Mahout目前专注于推荐(RECOMMENDATIONS)、聚类(CLUSTERING)、分类(CLASSIFICATION)三大部分,具体事例可见Mahout In Action
推荐(RECOMMENDATIONS)
推荐算法介绍
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
Item Based Algothrim
https://cwiki.apache.org/confluence/display/MAHOUT/Itembased+Collaborative+Filtering
Collaborative Filtering using a parallel matrix factorization
https://cwiki.apache.org/confluence/display/MAHOUT/Collaborative+Filtering+with+ALS-WR
注:基于矩阵因子分解的方法,由于需要不断迭代,所以在mapreduce框架下效率会受影响
Non-distributed recommenders
https://cwiki.apache.org/confluence/display/MAHOUT/Recommender+Documentatio
注:mahout中也提供了推荐算法的非分布式的实现,其中有代号为”taste”的开源推荐引擎
分类(CLUSTERING)
Bayesian 贝叶斯分类
http://blog.echen.me/2011/08/22/introduction-to-latent-dirichlet-allocation/
注:其中同时实现了Naive Bayes和Complementary Naive
BayesRandom Forests 随机森林
https://cwiki.apache.org/confluence/display/MAHOUT/Random+Forests
注:在公司内部,GBDT(内部称treelink)有着广泛的引用,附介绍文章
http://www.searchtb.com/2010/12/an-introduction-to-treelink.html?(tbsearch博客)
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html?(介绍随机森林与GBDT的博客)
Logistic Regression(逻辑回归)
https://cwiki.apache.org/confluence/display/MAHOUT/Logistic+Regression
注:是用SGD(Stochastic Gradient Descent,随机梯度下降)的方法实现的
也可用liblinear:?http://www.csie.ntu.edu.tw/~cjlin/liblinear/?(其中支持L1&L2 regularized logistic regression)
SVM(支持向量机)
目前mahout这个模块还在开发,尚未集成入发布包,如有需要,建议使用台大的libSVM包
libSVM:http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/
聚类(CLASSIFICATION)
聚类方法简述
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy3/
Canopy Clustering模块分析
http://www.cnblogs.com/vivounicorn/archive/2011/09/23/2186483.html?(中文博客)
https://cwiki.apache.org/confluence/display/MAHOUT/Canopy+Clustering?(英文文档)
Kmeans模块分析
http://www.cnblogs.com/vivounicorn/archive/2011/10/08/2201986.html?(中文博客)
https://cwiki.apache.org/confluence/display/MAHOUT/K-Means+Clustering?(英文文档)
Fuzz Kmeans
https://cwiki.apache.org/confluence/display/MAHOUT/Fuzzy+K-Means
Mean Shift Clustering
https://cwiki.apache.org/confluence/display/MAHOUT/Mean+Shift+Clustering
注:目前主要用于图像分割和跟踪等计算机视觉领域
Latent Dirichlet Allocation(LDA)
https://cwiki.apache.org/confluence/display/MAHOUT/Latent+Dirichlet+Allocation
注:经典方法,附论文英文原著论文?http://machinelearning.wustl.edu/mlpapers/paper_files/BleiNJ03.pdf?(引用数:6829)
http://www.docin.com/p-413125834.html?(基于LDA话题演化研究方法综述)
http://leyew.blog.51cto.com/5043877/860255?(中文博客学习笔记)
http://blog.echen.me/2011/08/22/introduction-to-latent-dirichlet-allocation/?(英文入门博客)
Pattern Mining 模式挖掘
Parallel Frequent Pattern Mining 并行频繁模式挖掘
https://cwiki.apache.org/confluence/display/MAHOUT/Parallel+Frequent+Pattern+Mining
论文http://wenku.baidu.com/view/9cce67ed172ded630b1cb615.html(在Query推荐中的应用)
Dimension reduction 降维
Singular Value Decomposition(SVD) 奇异值分解
https://cwiki.apache.org/confluence/display/MAHOUT/Dimensional+Reduction
SVD介绍:?http://wenku.baidu.com/view/7f483a6b561252d380eb6ea6.html
Evolutionary Algorithms 进化算法
进化算法框架
进化算法介绍:
http://www.geatbx.com/docu/algindex.html
框架使用方法:
https://cwiki.apache.org/confluence/display/MAHOUT/Mahout.GA.Tutorial
注:目前mahout只是提供一套进化算法的并行化实现框架,但具体的进化算法,如遗传算法、模拟退火算法、蚁群算法等,还未集成到开发包中。
相关工具书
- 统计学习书籍
1. 统计学习基础 — 数据挖掘、推理与预测(中文版)
http://yunpan.taobao.com/share/link/R56BeLI6O
注:此书英文版每年都在更新,但是中文版只有2004年一版,而且网上纸质书早就脱销了,由于是统计学习基础,所以大多数经典内容还是可读的;
2. 统计学习基础 — 数据挖掘、推理与预测(英文版)(The Elements of Statistical Learning)
http://yunpan.taobao.com/share/link/D56BeLKYE
目前的最新版,第二版(09年)的的第10次印刷版本(13年)
可与中文版对照看
- 概率论与数理统计基础书籍
1. 浙大概率论与数理统计第三版
http://yunpan.taobao.com/share/link/U56BeLWBT
经典的教科书
2. 统计学完全教程(中文版)
http://yunpan.taobao.com/share/link/756BeLYAa
统计学的百科全书
- 数据挖掘概述书籍
1. 数据挖掘导论(中文版)
http://yunpan.taobao.com/share/link/O56BeLoPx
2. Data Mining.Concepts and Techniques.3Ed(英文版)
http://yunpan.taobao.com/share/link/256BeLopX
注:中文版还是2000年的老版,起不到参考作用,所以放了最新的英文版
- 统计学习在自然语言处理方面应用的书籍
1.统计自然语言处理基础(中文版)
http://yunpan.taobao.com/share/link/25VBpL7X
其它
更多更新可见wiki:?http://searchwiki.taobao.ali.com/index.php/PbaseLearning/mahout


 Python ORM 性能基准测试:比较不同 ORM 框架Mar 18, 2024 am 09:10 AM
Python ORM 性能基准测试:比较不同 ORM 框架Mar 18, 2024 am 09:10 AM对象关系映射(ORM)框架在python开发中扮演着至关重要的角色,它们通过在对象和关系数据库之间建立桥梁,简化了数据访问和管理。为了评估不同ORM框架的性能,本文将针对以下流行框架进行基准测试:sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM测试方法基准测试使用了一个包含100万条记录的SQLite数据库。测试对数据库执行了以下操作:插入:向表中插入10,000条新记录读取:读取表中的所有记录更新:更新表中所有记录的单个字段删除:删除表中的所有记录每个操作
 Python ORM 在大数据项目中的应用Mar 18, 2024 am 09:19 AM
Python ORM 在大数据项目中的应用Mar 18, 2024 am 09:19 AM对象关系映射(ORM)是一种编程技术,允许开发人员使用对象编程语言来操作数据库,而无需直接编写sql查询。python中的ORM工具(例如SQLAlchemy、Peewee和DjangoORM)简化了大数据项目的数据库交互。优点代码简洁性:ORM消除了编写冗长的SQL查询的需要,这提高了代码简洁性和可读性。数据抽象:ORM提供了一个抽象层,将应用程序代码与数据库实现细节隔离开来,提高了灵活性。性能优化:ORM通常会使用缓存和批量操作来优化数据库查询,从而提高性能。可移植性:ORM允许开发人员在不
 深入了解常用的7种Java设计模式Dec 23, 2023 pm 01:01 PM
深入了解常用的7种Java设计模式Dec 23, 2023 pm 01:01 PM了解Java设计模式:常用的7种设计模式简介,需要具体代码示例Java设计模式是一种解决软件设计问题的通用解决方案,它提供了一套被广泛接受的设计思想与行为准则。设计模式帮助我们更好地组织和规划代码结构,使得代码具有更好的可维护性、可读性和可扩展性。在本文中,我们将介绍Java中常用的7种设计模式,并提供相应的代码示例。单例模式(SingletonPatte
 Yii框架简介:了解Yii的核心概念Jun 21, 2023 am 09:39 AM
Yii框架简介:了解Yii的核心概念Jun 21, 2023 am 09:39 AMYii框架是一个高性能、高扩展性、高可维护性的PHP开发框架,在开发Web应用程序时具有很高的效率和可靠性。Yii框架的主要优点在于其独特的特性和开发方法,同时还集成了许多实用的工具和功能。Yii框架的核心概念MVC模式Yii采用了MVC(Model-View-Controller)模式,是一种将应用程序分为三个独立部分的模式,即业务逻辑处理模型、用户界面呈
 使用 Python ORM 实现高效的数据持久性Mar 18, 2024 am 09:25 AM
使用 Python ORM 实现高效的数据持久性Mar 18, 2024 am 09:25 AM对象关系映射(ORM)是一种技术,它允许在面向对象编程语言和关系数据库之间建立桥梁。使用pythonORM可以显著简化数据持久性操作,从而提高应用程序的开发效率和可维护性。优势使用PythonORM具有以下优势:减少样板代码:ORM自动生成sql查询,从而避免编写大量的样板代码。简化数据库交互:ORM提供了一个统一的接口,用于与数据库交互,简化了数据操作。提高安全性:ORM使用参数化查询,可以防止SQL注入等安全漏洞。促进数据一致性:ORM确保对象与数据库之间的同步,维护数据一致性。选择ORM有
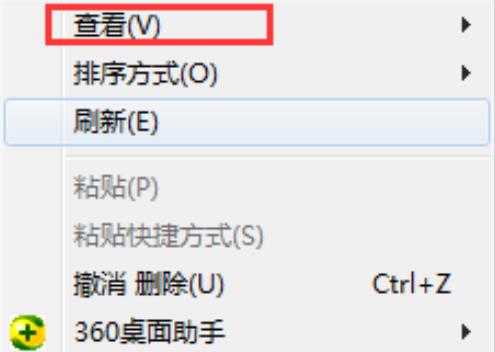 Win10桌面图标整理技巧Dec 27, 2023 pm 05:00 PM
Win10桌面图标整理技巧Dec 27, 2023 pm 05:00 PM使用电脑的小伙伴都希望自己的桌面排列干净看起来整整齐齐但是不知道怎么在win10系统中操作,今天就给你们带来了整理桌面图标win10方法,一起看看吧。整理桌面图标win10怎么整齐:1、右击桌面空白处,点击最上方的“查看”。2、在右侧的窗口中可以看到“自动排列图标”等功能。3、不要勾选“自动排列图标”这样就能够根据自己的需求来摆放图标了。4、而且这些选项是都可以全部选择的,但是这样就没法摆出自己的个性了。
 Python Pandas 数据处理利器,新手入门必读!Mar 20, 2024 pm 06:21 PM
Python Pandas 数据处理利器,新手入门必读!Mar 20, 2024 pm 06:21 PMpandas是python中强大的数据处理库,专门用于处理结构化数据(如表格)。它提供了丰富的功能,使数据探索、清洗、转换和建模变得简单。对于数据分析和科学领域的初学者来说,掌握Pandas至关重要。数据结构Pandas使用两种主要数据结构:Series:一维数组,类似于NumPy数组,但包含标签(索引)。DataFrame:二维表,包含具有标签的列和小数。数据导入和导出导入数据:使用read_csv()、read_excel()等函数从CSV、Excel和其他文件导入数据。导出数据:使用to_
 Python vs. Jython:谁是跨平台开发之王?Mar 22, 2024 pm 12:21 PM
Python vs. Jython:谁是跨平台开发之王?Mar 22, 2024 pm 12:21 PMpython和Jython都是流行的编程语言,但它们针对不同的用例进行了优化,并在跨平台开发方面具有独特的优势和劣势。Python优势:广泛的库和社区支持易于学习和使用,适合初学者可移植性强,可跨多个平台运行支持多种编程范式,包括面向对象、函数式和命令式编程劣势:性能较低,不适合处理密集型计算任务对内存消耗较高在某些平台上可能需要其他工具和配置Jython优势:完全与Python兼容,可以使用Python的所有库和工具运行在Java虚拟机(JVM)上,提供与Java生态系统的无缝集成性能优于Py


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

