
ホームページ >ウェブフロントエンド >jsチュートリアル >JavaScriptの文字セットについての簡単な説明_基礎知識
JavaScriptの文字セットについての簡単な説明_基礎知識

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 16:47:151464ブラウズ
JavaScript では大文字と小文字が区別されます:
キーワード、変数、関数名、およびすべての識別子は、大文字と小文字を一貫して使用する必要があります (通常は小文字で記述します)。これは、私が最初に C# を学んだときのマルチスタイルの記述方法とは大きく異なります。
例: (ここでは変数 str と Str を例として取り上げます)
var str='abc';
var Str ='ABC';
alert(str);//abc を出力
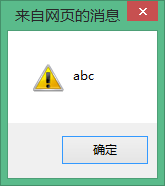
str と Str が同じ変数の場合、alert(str); の場合、出力結果は上記の abc ではなく ABC になるはずです。これは、JavaScript では大文字と小文字が区別されることを示しています。
Unicode エスケープ シーケンス
Unicode 文字セットの登場は、ASCII コードでは 128 文字しか表現できないという制限を補うためのものです。日常生活で漢字や日本語を表示したい場合、ASCII は明らかに不可能です。したがって、Unicode は ASCII と Latin-1 のスーパーセットです。まず、JavaScript プログラムは Unicode 文字セットを使用して記述されていますが、一部のコンピューター ハードウェアおよびソフトウェアでは、この現象を解決するために、Unicode 文字の完全なセットを表示または入力することができません。 JavaScript は特別なシーケンスを定義します。このシーケンスは 6 つの ASCII 文字を使用して 16 ビット Unicode 内部コードを表します。この特別なシーケンスは、先頭に u が付き、その後に 4 つの 16 進数
が続きます。例:
var str='cafu00e9';
var Str ='café';
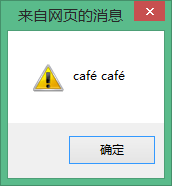
alert(Str ' ' str);// 表示効果は同じであることがわかります。
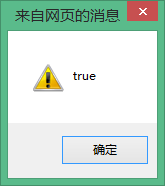
alert (Str===str);//true を出力
しかし、上記の é エスケープの例で示されているように、Unicode では複数のメソッドで同じ文字をエンコードできることに注意してください:
é:
1. Unicode 文字 u00E9 を使用して
を表すことができます。2.
を表すために eu0301 (イントネーション文字) を使用することもできます。var str='cafu00e9';
var Str ='cafeu0301';
alert(str ' ' Str); //下図のように、Str と str の出力結果は同じです
alert(Str===str); //結果は同じですが、バイナリエンコード表現が根本的に異なるため、出力は false
テキストエディタに表示される結果は同じですが、バイナリエンコード表現が根本的に異なります。プログラミング言語は最終的にはローカルプラットフォームのコンピュータ機械コード(バイナリエンコード)に変換され、コンピュータは処理することしかできません。バイナリ 結果はコードを比較することによってのみ知ることができるため、比較の最終結果は false のみになる可能性があります
これは、「Unicode では複数のメソッドで同じ文字をエンコードできる」ということの最も適切な説明になります。Unicode 標準では、テキストを適切な比較のために統一した Unicode 形式に変換するための、すべての文字の優先エンコード形式が定義されているからです。
例として é を再度使用します:
é in faceとcafeは同じですか?
face とカフェの é は両方とも u00E9 に変換されるか、両方とも eu0301 に変換され、face とカフェの é を比較できるようになります