


JavaScript の構文がいかに悲惨であるかは誰もが知っています。
まず写真を撮りましょう
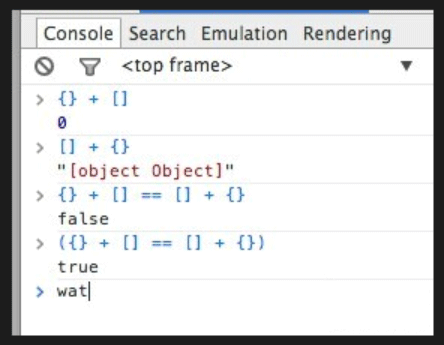
コードは次のとおりです:
{} // 0
[ ] {} // "[オブジェクト オブジェクト]"
{} [] == [] {} // false
({} [] == [] {}); true
このような厄介な構文の落とし穴は、おそらく JavaScript のような奇妙なものでのみ見られます。
JavaScript コンパイラを勉強していないほとんどの子供たちはまったく理解できないと思います。 (少なくとも私は信じられないほどだと思います)
その後、母の特別訪問に行って、はたと気づきました!
次に、このコードを見てみましょう:
{
a: 1
}
ほとんどの子供用靴は、一見するとこれがオブジェクトの直接的な量であると考えると思います。
このコードはどうでしょうか?
{
var a = 1;
}
ブラウザでは構文エラーが表示されますか?
明らかにそうではありません!よく考えてみると、これはステートメントブロックであることがわかります。
if (isNumber) {
var a = 1 ;
}
この時点で、熱心な方ならお気づきかもしれませんが、{ で始まる JavaScript にはあいまいさが存在します。
JavaScript コンパイラーはこの曖昧さにどのように対処するのでしょうか?
この問題を解決するために、ECMA の方法は非常に単純かつ粗雑です。文法解析中に、ステートメントが "{" で始まる場合、それはステートメント ブロックとしてのみ解釈されます。
これは本当に不正な対処方法です。
これらはすべてステートメントブロックであるのに、なぜ {a:1} には文法上の誤りがないのでしょうか?
実際、ここでは、 a はパーサーによってタグとして理解されます。ラベルは、方向へのジャンプを行うために、break および continue ステートメントとともに使用されます。
したがって、次のように記述すると例外がスローされます:
{
a: function () {}
}
function () {} は関数宣言でも関数式でもないからです。
この時点で、誰もが {} の奇妙な処理についての基本的な概念を理解できるはずです。記事の冒頭で述べた文を振り返ってみましょう:
{} // 0
[ ] {} // "[オブジェクト オブジェクト]"
{} [] == [] {} // false
({} [] == [] {}); true
最初のコードは、{} がステートメント ブロックであるため、コードは次のように理解できます:
if (1) {}
[]
つまり、戻り値は 0 です。
2 番目に、{} がステートメントの先頭にないため、通常のオブジェクトの直接量であり、空の配列と空のオブジェクトが直接追加され、「[object Object]」が返されます。
最初の項目と 2 番目の項目は理解できました。3 番目の項目はもう説明する必要はありません。
4 番目の式は () で始まるため、最初の {} はオブジェクト リテラルとして解析されるため、2 つの式は等しく、true を返します。

 JavaScriptエンジン:実装の比較Apr 13, 2025 am 12:05 AM
JavaScriptエンジン:実装の比較Apr 13, 2025 am 12:05 AMさまざまなJavaScriptエンジンは、各エンジンの実装原則と最適化戦略が異なるため、JavaScriptコードを解析および実行するときに異なる効果をもたらします。 1。語彙分析:ソースコードを語彙ユニットに変換します。 2。文法分析:抽象的な構文ツリーを生成します。 3。最適化とコンパイル:JITコンパイラを介してマシンコードを生成します。 4。実行:マシンコードを実行します。 V8エンジンはインスタントコンピレーションと非表示クラスを通じて最適化され、Spidermonkeyはタイプ推論システムを使用して、同じコードで異なるパフォーマンスパフォーマンスをもたらします。
 ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM
ブラウザを超えて:現実世界のJavaScriptApr 12, 2025 am 12:06 AM現実世界におけるJavaScriptのアプリケーションには、サーバー側のプログラミング、モバイルアプリケーション開発、モノのインターネット制御が含まれます。 2。モバイルアプリケーションの開発は、ReactNativeを通じて実行され、クロスプラットフォームの展開をサポートします。 3.ハードウェアの相互作用に適したJohnny-Fiveライブラリを介したIoTデバイス制御に使用されます。
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する(バックエンド統合)Apr 11, 2025 am 08:23 AM私はあなたの日常的な技術ツールを使用して機能的なマルチテナントSaaSアプリケーション(EDTECHアプリ)を作成しましたが、あなたは同じことをすることができます。 まず、マルチテナントSaaSアプリケーションとは何ですか? マルチテナントSaaSアプリケーションを使用すると、Singの複数の顧客にサービスを提供できます
 next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AM
next.jsを使用してマルチテナントSaaSアプリケーションを構築する方法(フロントエンド統合)Apr 11, 2025 am 08:22 AMこの記事では、許可によって保護されたバックエンドとのフロントエンド統合を示し、next.jsを使用して機能的なedtech SaaSアプリケーションを構築します。 FrontEndはユーザーのアクセス許可を取得してUIの可視性を制御し、APIリクエストがロールベースに付着することを保証します
 JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AM
JavaScript:Web言語の汎用性の調査Apr 11, 2025 am 12:01 AMJavaScriptは、現代のWeb開発のコア言語であり、その多様性と柔軟性に広く使用されています。 1)フロントエンド開発:DOM操作と最新のフレームワーク(React、Vue.JS、Angularなど)を通じて、動的なWebページとシングルページアプリケーションを構築します。 2)サーバー側の開発:node.jsは、非ブロッキングI/Oモデルを使用して、高い並行性とリアルタイムアプリケーションを処理します。 3)モバイルおよびデスクトップアプリケーション開発:クロスプラットフォーム開発は、反応および電子を通じて実現され、開発効率を向上させます。
 JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AM
JavaScriptの進化:現在の傾向と将来の見通しApr 10, 2025 am 09:33 AMJavaScriptの最新トレンドには、TypeScriptの台頭、最新のフレームワークとライブラリの人気、WebAssemblyの適用が含まれます。将来の見通しは、より強力なタイプシステム、サーバー側のJavaScriptの開発、人工知能と機械学習の拡大、およびIoTおよびEDGEコンピューティングの可能性をカバーしています。
 javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AM
javascriptの分解:それが何をするのか、なぜそれが重要なのかApr 09, 2025 am 12:07 AMJavaScriptは現代のWeb開発の基礎であり、その主な機能には、イベント駆動型のプログラミング、動的コンテンツ生成、非同期プログラミングが含まれます。 1)イベント駆動型プログラミングにより、Webページはユーザー操作に応じて動的に変更できます。 2)動的コンテンツ生成により、条件に応じてページコンテンツを調整できます。 3)非同期プログラミングにより、ユーザーインターフェイスがブロックされないようにします。 JavaScriptは、Webインタラクション、シングルページアプリケーション、サーバー側の開発で広く使用されており、ユーザーエクスペリエンスとクロスプラットフォーム開発の柔軟性を大幅に改善しています。
 pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AM
pythonまたはjavascriptの方がいいですか?Apr 06, 2025 am 12:14 AMPythonはデータサイエンスや機械学習により適していますが、JavaScriptはフロントエンドとフルスタックの開発により適しています。 1. Pythonは、簡潔な構文とリッチライブラリエコシステムで知られており、データ分析とWeb開発に適しています。 2。JavaScriptは、フロントエンド開発の中核です。 node.jsはサーバー側のプログラミングをサポートしており、フルスタック開発に適しています。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

WebStorm Mac版
便利なJavaScript開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

