


「通訳モード」とは何ですか?
まず「GOF」を開いて定義を確認します。
言語が与えられ、その文法の表現を定義し、この表現を使用してその言語の文を解釈するインタプリタを定義します。
始める前に、いくつかの概念を広める必要があります。
抽象構文ツリー:
インタープリター モードでは、抽象構文の作成方法が説明されません。木。構文解析は含まれません。抽象構文ツリーは、テーブル駆動パーサーによって完成することも、手書き (通常は再帰降下) パーサーによって作成することも、クライアントによって直接提供することもできます。
パーサー:
は、クライアント呼び出し要件を記述する式を解析して抽象構文ツリーを形成するプログラムを指します。
インタープリタ:
は、抽象構文ツリーを解釈し、各ノードに対応する関数を実行するプログラムを指します。
インタプリタ モードを使用するには、重要な前提条件は、文法とも呼ばれる一連の文法規則を定義することです。この文法の規則が単純であるか複雑であるかに関係なく、インタプリタ モードはこれらの規則に従って対応する機能を解析して実行するため、これらの規則を適用する必要があります。
まず、インタープリター モードの構造図と説明を見てみましょう:

AbstractExpression: インタプリタのインターフェースを定義し、インタプリタの解釈操作に同意します。
ターミナル式: ターミナル インタープリターは、文法規則のターミナル記号に関連する操作を実装するために使用されます。結合モードを使用して抽象構文ツリーを構築する場合、これは完全に機能します。複合モードのリーフ オブジェクトでは、複数のターミナル インタプリタが存在する可能性があります。
NonterminalExpression: 非終端記号に関連する操作を文法規則に実装するために使用される、通常、1 つのインタープリターが文法規則に対応し、結合モードが使用される場合は他のインタープリターを含めることができます。抽象構文ツリーでは、組み合わせパターンにおける組み合わせオブジェクトに相当します。複数の非端末インタープリターが存在する可能性があります。
コンテキスト: コンテキストには通常、各インタープリターに必要なデータまたはパブリック関数が含まれています。
クライアント: クライアントは、インタプリタを使用するクライアントを指します。通常、言語の文法に従って作成された式は、インタプリタ オブジェクトを使用して記述された抽象構文ツリーに変換され、Explain と呼ばれます。手術。
以下では、インタープリター モードを理解するために XML の例を使用します。
まず、普遍性を保つために、root を使用してルート要素、abc などを表します。要素を表す単純な xml 次のように:
🎜>
合意された式の文法は次のとおりです。
1. 単一の要素の値を取得します。ルート要素から開始して、値を取得する要素に移動します。ルート要素の前に「/」で区切ります。「/」を追加しないでください。例えば、「root/a/b/c」という表現は、ルート要素以下のa要素、a要素、b要素、c要素の値を取得することを意味する。
2. 単一の要素の属性の値を取得します。値を取得する属性は、式の最後の要素の属性である必要があります。最後の要素の後に「.」を追加します。次に、属性の名前を追加します。例えば、「root/a/b/c.name」という表現は、ルート要素以下の要素a、要素b、要素cのname属性の値を取得することを意味する。
3. 同じ要素名の値を取得します。値を取得する要素は式の最後の要素である必要があり、最後の要素の後に「$」を追加します。例えば、「root/a/b/d$」という表現は、root要素以下、a要素以下、b要素以下の複数のd要素の値の集合を取得することを意味します。
4. 同じ要素名の属性の値を取得します。もちろん複数あります。属性値を取得する要素は式の最後の要素である必要があり、最後の要素の後に「$」を追加します。例えば、「root/a/b/d$.id$」という表現は、root要素以下、a要素以下、b要素以下の複数のd要素のid属性値の集合を取得することを意味します。
上記の XML、対応する抽象構文ツリー、可能な構造は図に示すとおりです。
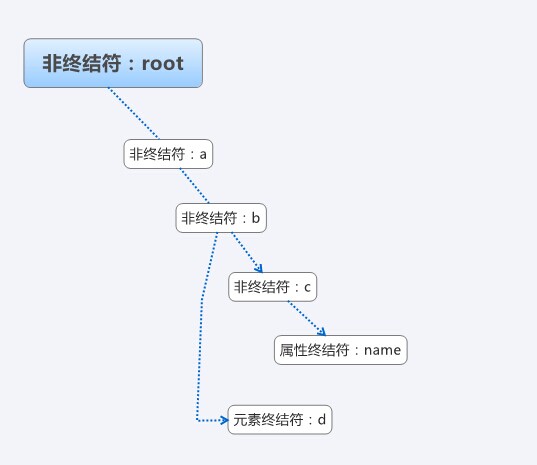
具体的なコードを見てみましょう:
1. コンテキストを定義します:
/**
* コンテキスト。インタープリターに必要なグローバル情報を含めるために使用されます。
* @param {String} filePathName [読み取る必要がある XML のパスと名前]
*/
function Context(filePathName) {
// 前に処理された要素
this.preEle = null;
// xml Document オブジェクト
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// コンテキストを再初期化します
reInit: function () {
this.preEle = null;
},
/**
* さまざまな式で一般的に使用されるメソッド
* 親要素の名前と現在の要素に基づいて現在の要素を取得します
* @param {Element} pEle [親要素]
* @param {String} eleName [現在の要素名]
* @return {Element|null} [現在の要素が見つかりました]
*/
getNowEle: function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i
if (nowEle .nodeName === eleName)
今すぐ戻るEル;
return null;
getPreEle: function () {
return this.preEle;
},
setPreEle: function (preEle) {
this.preEle = preEle;
},
getDocument: function () {
return this.document;
}
};
// ツール オブジェクト
// xml を解析し、対応する Document オブジェクトを取得します
var ;
var xmldom = parser.parseFromString('
xmldom; を返します
以下はインタープリターコードです:
コードをコピー
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
Element TerminalExpression.prototype = {
解釈: function (context) {
var pEle = context.getPreEle();
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
要素の値を取得する
/**
* 終端記号としての属性に対応するインタープリタ
* @param {String} propName [属性の名前]
function Property TerminalExpression(propName) {
this.propName = propName;
}
Property TerminalExpression.prototype = {
解釈: function (context) {
// 最後の要素属性の値を直接取得します
}
};
まず、インタープリターを使用して単一要素の値を取得する方法を見てみましょう:
コードをコピー
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b' );
var cEle = new Element TerminalExpression ('c');
// 組み合わせ
root.addEle(aEle);
aEle.addEle(bEle); bEle.addEle(cEle);
console.log('c の値は = ' root.interpret(c));
}();
出力: c の値は = 12345
コードをコピー
void function () {
var c = new Context();
// 次の式の値である d 要素の id 属性を取得したい: "a/ b/c .name"
// この時点では c は終了していません。c を ElementExpression
に変更する必要があります。 var root = new ElementExpression('root');
var aEle = new ElementExpression(' a');
var bEle = new ElementExpression('b');
var cEle = new ElementExpression('c');
var prop = new Property TerminalExpression('name');
// 組み合わせ
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('c の属性名の値は = ' root.interpret(c));
// 継続的な解析に同じコンテキストを使用したい場合は、コンテキスト オブジェクトを再初期化する必要があります
// たとえば、属性名の値を継続的に再取得したい場合は、もちろん要素を再結合することもできます
// 再解析します。同じコンテキストを使用している限り、コンテキスト オブジェクトを再初期化する必要があります
c.reInit() ));
} ();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
インタプリタ オブジェクトが文法規則を担当する仕組みがあるからこそ、新しい文法を拡張することが非常に簡単になります。新しい構文を拡張するには、対応するインタープリター オブジェクトを作成し、抽象構文ツリーの作成時にこの新しいインタープリター オブジェクトを使用するだけです。
欠点:
複雑な構文には適していません
文法が特に複雑な場合、インタプリタモードに必要な抽象構文ツリーを構築する作業は非常に困難であり、複数の抽象構文ツリーを構築する必要がある場合があります。したがって、インタープリター モードは複雑な文法には適していません。パーサーまたはコンパイラー ジェネレーターを使用した方がよい場合があります。
いつ使用しますか?
解釈して実行する必要がある言語があり、その言語内の文が抽象構文ツリーとして表現できる場合は、インタープリター モードの使用を検討できます。
インタープリター モードを使用する場合は、他にも 2 つの特性を考慮する必要があります。1 つは、構文が比較的単純である必要があるということです。もう 1 つは、インタープリター モードの使用には適していないということです。要件はそれほど高くないため、使用には適していません。
前回の記事では、単一要素の値と単一要素属性の値を取得する方法を紹介しました。複数の要素の値と、その名前の値を取得する方法を見てみましょう。複数の要素と以前のテストと同様に、人工的に組み立てられた抽象構文ツリーについては、以前に定義された文法に準拠する式を以前に実装されたインタープリターの抽象構文ツリーに変換する次の単純なパーサーも実装しました。直接:
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
mapPath[ele] = pm;
listEle.push(ele);
}
// 2 番目のステップの実装を開始します ---------------------------------------------------

 JavaScriptコメント://および / * *を使用するためのガイドMay 13, 2025 pm 03:49 PM
JavaScriptコメント://および / * *を使用するためのガイドMay 13, 2025 pm 03:49 PMjavascriptusestwotypesofcomments:シングルライン(//)およびマルチライン(//)
 Python vs. JavaScript:開発者の比較分析May 09, 2025 am 12:22 AM
Python vs. JavaScript:開発者の比較分析May 09, 2025 am 12:22 AMPythonとJavaScriptの主な違いは、タイプシステムとアプリケーションシナリオです。 1。Pythonは、科学的コンピューティングとデータ分析に適した動的タイプを使用します。 2。JavaScriptは弱いタイプを採用し、フロントエンドとフルスタックの開発で広く使用されています。この2つは、非同期プログラミングとパフォーマンスの最適化に独自の利点があり、選択する際にプロジェクトの要件に従って決定する必要があります。
 Python vs. JavaScript:ジョブに適したツールを選択するMay 08, 2025 am 12:10 AM
Python vs. JavaScript:ジョブに適したツールを選択するMay 08, 2025 am 12:10 AMPythonまたはJavaScriptを選択するかどうかは、プロジェクトの種類によって異なります。1)データサイエンスおよび自動化タスクのPythonを選択します。 2)フロントエンドとフルスタック開発のためにJavaScriptを選択します。 Pythonは、データ処理と自動化における強力なライブラリに好まれていますが、JavaScriptはWebインタラクションとフルスタック開発の利点に不可欠です。
 PythonとJavaScript:それぞれの強みを理解するMay 06, 2025 am 12:15 AM
PythonとJavaScript:それぞれの強みを理解するMay 06, 2025 am 12:15 AMPythonとJavaScriptにはそれぞれ独自の利点があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1. Pythonは、データサイエンスやバックエンド開発に適した簡潔な構文を備えた学習が簡単ですが、実行速度が遅くなっています。 2。JavaScriptはフロントエンド開発のいたるところにあり、強力な非同期プログラミング機能を備えています。 node.jsはフルスタックの開発に適していますが、構文は複雑でエラーが発生しやすい場合があります。
 JavaScriptのコア:CまたはCの上に構築されていますか?May 05, 2025 am 12:07 AM
JavaScriptのコア:CまたはCの上に構築されていますか?May 05, 2025 am 12:07 AMjavascriptisnotbuiltoncorc;それは、解釈されていることを解釈しました。
 JavaScriptアプリケーション:フロントエンドからバックエンドまでMay 04, 2025 am 12:12 AM
JavaScriptアプリケーション:フロントエンドからバックエンドまでMay 04, 2025 am 12:12 AMJavaScriptは、フロントエンドおよびバックエンド開発に使用できます。フロントエンドは、DOM操作を介してユーザーエクスペリエンスを強化し、バックエンドはnode.jsを介してサーバータスクを処理することを処理します。 1.フロントエンドの例:Webページテキストのコンテンツを変更します。 2。バックエンドの例:node.jsサーバーを作成します。
 Python vs. Javascript:どの言語を学ぶべきですか?May 03, 2025 am 12:10 AM
Python vs. Javascript:どの言語を学ぶべきですか?May 03, 2025 am 12:10 AMPythonまたはJavaScriptの選択は、キャリア開発、学習曲線、エコシステムに基づいている必要があります。1)キャリア開発:Pythonはデータサイエンスとバックエンド開発に適していますが、JavaScriptはフロントエンドおよびフルスタック開発に適しています。 2)学習曲線:Python構文は簡潔で初心者に適しています。 JavaScriptの構文は柔軟です。 3)エコシステム:Pythonには豊富な科学コンピューティングライブラリがあり、JavaScriptには強力なフロントエンドフレームワークがあります。
 JavaScriptフレームワーク:最新のWeb開発のパワーMay 02, 2025 am 12:04 AM
JavaScriptフレームワーク:最新のWeb開発のパワーMay 02, 2025 am 12:04 AMJavaScriptフレームワークのパワーは、開発を簡素化し、ユーザーエクスペリエンスとアプリケーションのパフォーマンスを向上させることにあります。フレームワークを選択するときは、次のことを検討してください。1。プロジェクトのサイズと複雑さ、2。チームエクスペリエンス、3。エコシステムとコミュニティサポート。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

WebStorm Mac版
便利なJavaScript開発ツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

