
ホームページ >ウェブフロントエンド >jsチュートリアル >Node.js は、detail_node.js に BigPipe を実装します。
Node.js は、detail_node.js に BigPipe を実装します。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2016-05-16 16:29:031671ブラウズ
BigPipe は、Web ページの読み込み速度を最適化するために Facebook によって開発されたテクノロジーです。実際、node.js に限らず、他の言語での BigPipe 実装はインターネット上にほとんどありません。このテクノロジーが登場してからしばらくの間、私は、Web ページのフレーム全体が最初に送信された後、別の、またはいくつかの ajax リクエストを使用してページ内のモジュールをリクエストすると考えていました。つい最近まで、BigPipe の中心的な概念は HTTP リクエストを 1 つだけ使用することですが、ページ要素は順番どおりに送信されないことを知りました。
この中心的な概念を理解すると、node.js の非同期機能のおかげで、node.js を使用して BigPipe を実装するのが簡単になります。この記事では、BigPipe テクノロジーの起源と、node.js に基づく簡単な実装について、例を段階的に説明します。
簡単にするために、Express を使用してテンプレート エンジンとして Jade を選択し、エンジンのサブテンプレート (部分) 機能を使用せず、サブテンプレートの後に HTML を使用します。親テンプレートのデータとしてレンダリングされます。
まず、nodejs-bigpipe フォルダーを作成し、次のように package.json ファイルを作成します。
{
"名前": "ビッグパイプ実験"
、「バージョン」: "0.1.0"
、「プライベート」: true
、「依存関係」: {
"エクスプレス": "3.x.x"
、「統合」: 「最新」
、"翡翠": "最新"
}
}
npm install を実行して、これら 3 つのライブラリをインストールします。consolidate は、jade の呼び出しを容易にするために使用されます。
最初に最も単純な 2 つのファイルを試してみましょう:
app.js:
var Express = require('express')
、cons = require('consolidate')
、jade = require('jade')
、パス = require('パス')
var app =express()
app.engine('jade', cons.jade)
app.set('views', path.join(__dirname, 'views'))
app.set('ビューエンジン', 'jade')
app.use(function (req, res) {
res.render('レイアウト', {
s1: 「こんにちは、最初のセクションです。」
、s2: 「こんにちは、二課です。」
})
})
app.listen(3000)
views/layout.jade
doctype html
頭
タイトル Hello, World!
スタイル
セクション {
マージン: 20px 自動;
境界線: 1 ピクセルの点線グレー;
幅: 80%;
高さ: 150px;
}
セクション#s1!=s1
セクション#s2!=s2
効果は次のとおりです:
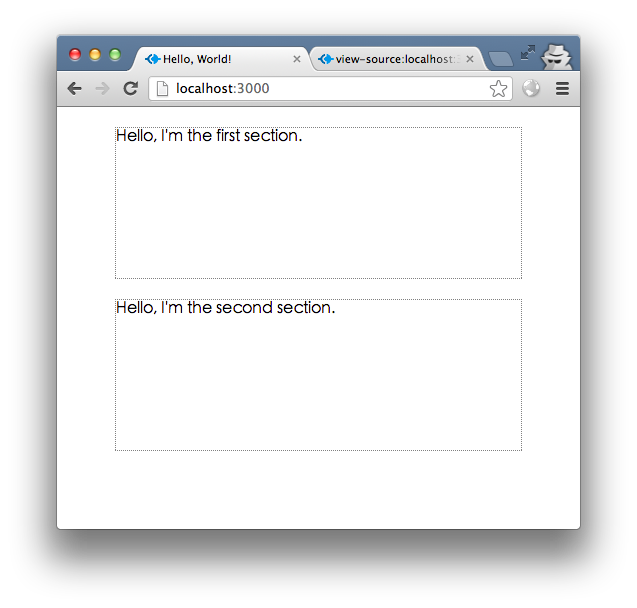
次に、2 つのセクション テンプレートを 2 つの異なるテンプレート ファイルに配置します。
views/s1.jade:
h1 部分 1
.content!=コンテンツ
views/s2.jade:
h1 部分 2
.content!=コンテンツ
layout.jade のスタイルにいくつかのスタイルを追加します
セクション h1 {
フォントサイズ: 1.5;
パディング: 10px 20px;
マージン: 0;
border-bottom: 1px 点線グレー;
}
セクション div {
マージン: 10px;
}
app.js の app.use() 部分を次のように変更します:
var temp = {
s1: jade.compile(fs.readFileSync(path.join(__dirname, 'views', 's1.jade')))
、s2: jade.compile(fs.readFileSync(path.join(__dirname, 'views', 's2.jade')))
}
app.use(function (req, res) {
res.render('レイアウト', {
s1: temp.s1({ content: "こんにちは、最初のセクションです。" })
, s2: temp.s2({ content: "こんにちは、二課です。" })
})
})
前に「サブテンプレートが親テンプレートのデータとしてレンダリングされた後に HTML を使用する」と述べましたが、それは 2 つのメソッド temp.s1 と temp.s2 が 2 つのファイル s1.jade を生成することを意味します。 s2.jade.HTML コードを作成し、これら 2 つのコードをlayout.jade の 2 つの変数 s1 と s2 の値として使用します。
ページは次のようになります:
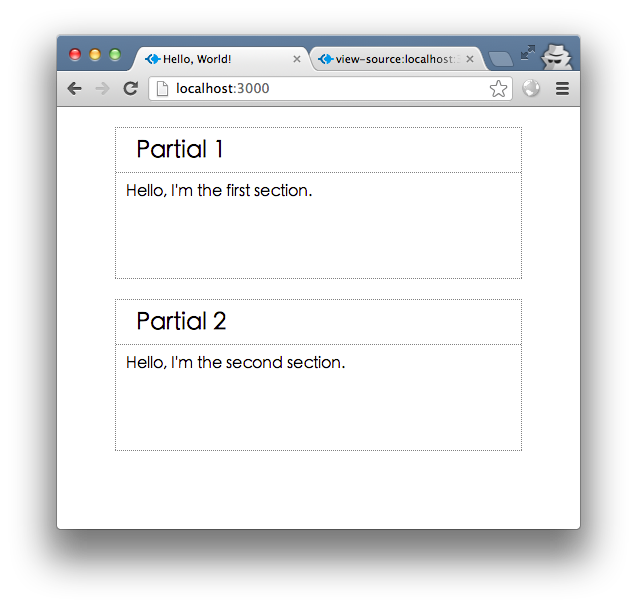
一般に、2 つのセクションのデータはデータベースにクエリするか RESTful リクエストによって個別に取得されます。このような非同期操作をシミュレートするために 2 つの関数を使用します。
var getData = {
d1: 関数 (fn) {
setTimeout(fn, 3000, null, { content: "こんにちは、最初のセクションです。" })
}
、d2: 関数 (fn) {
setTimeout(fn, 5000, null, { content: "こんにちは、二課です。" })
}
}
このように、app.use() のロジックはより複雑になります。これに対処する最も簡単な方法は次のとおりです。
getData.d1(関数 (err, s1data) {
GetData.d2(関数 (err, s2data) {
res.render('レイアウト', {
s1: temp.s1(s1data)
、 、 s2: temp.s2(s2data)
})
})
})
})
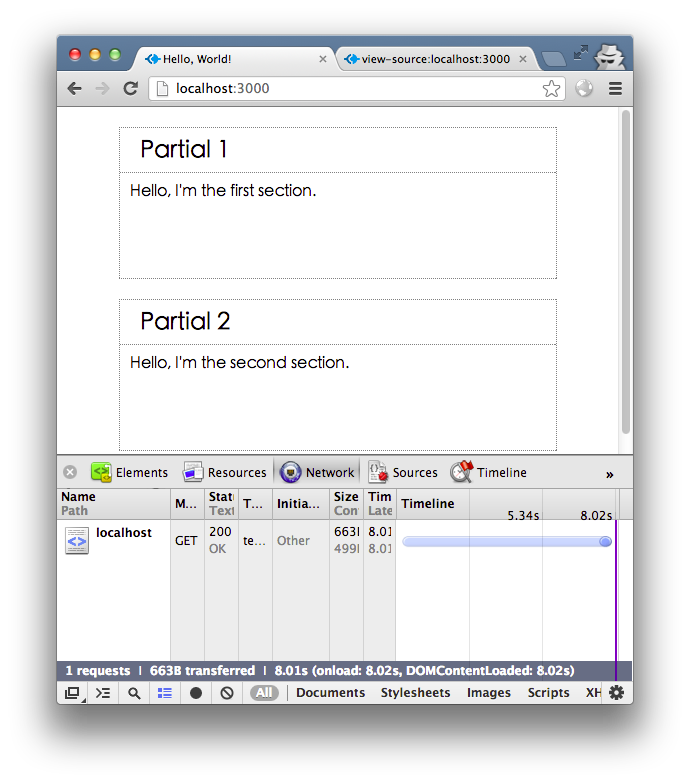
var n = 2
、結果 = {}
getData.d1(関数 (err, s1data) {
result.s1data = s1data
--n || writeResult()
})
getData.d2(関数 (err, s2data) {
result.s2data = s2data
--n || writeResult()
})
関数 writeResult() {
res.render('レイアウト', {
s1: temp.s1(result.s1data)
、s2: temp.s2(result.s2data)
})
}
})
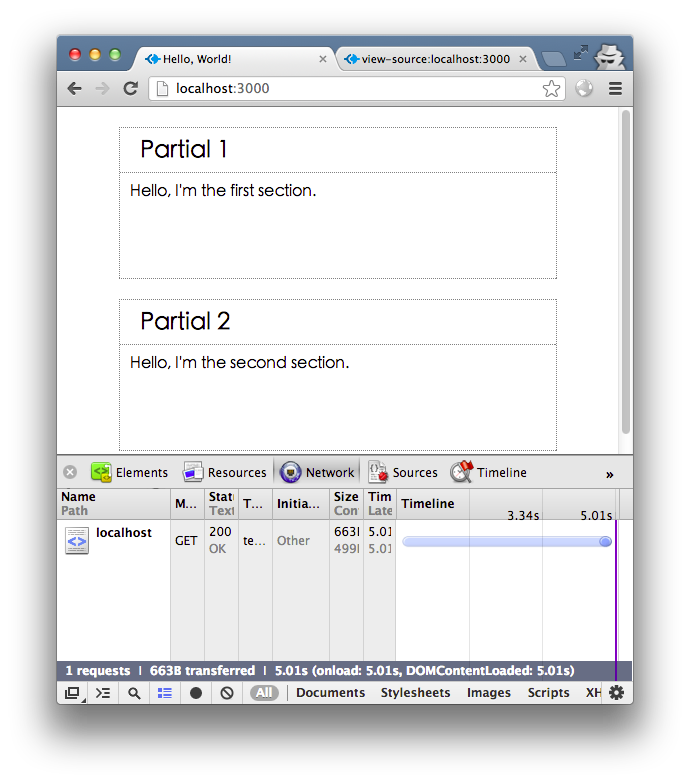
cd 静的
カール http://code.jquery.com/jquery-1.8.3.min.js -o jquery.js
ln -s ../node_modules/jade/runtime.min.js jade.js
そして、layout.jade の style タグ内のコードを取り出して static/style.css に配置し、head タグを次のように変更します。
頭
タイトル Hello, World!
link(href="/static/style.css", rel="スタイルシート")
スクリプト(src="/static/jquery.js")
スクリプト(src="/static/jade.js")
app.js では、両方のダウンロード速度を 2 秒にシミュレートし、 app.use(function (req, res) { の前に
を追加します)
var static =express.static(path.join(__dirname, 'static'))
app.use('/static', function (req, res, next) {
setTimeout(static, 2000, req, res, next)
})
外部の静的ファイルにより、ページは約 7 秒で読み込まれるようになりました。
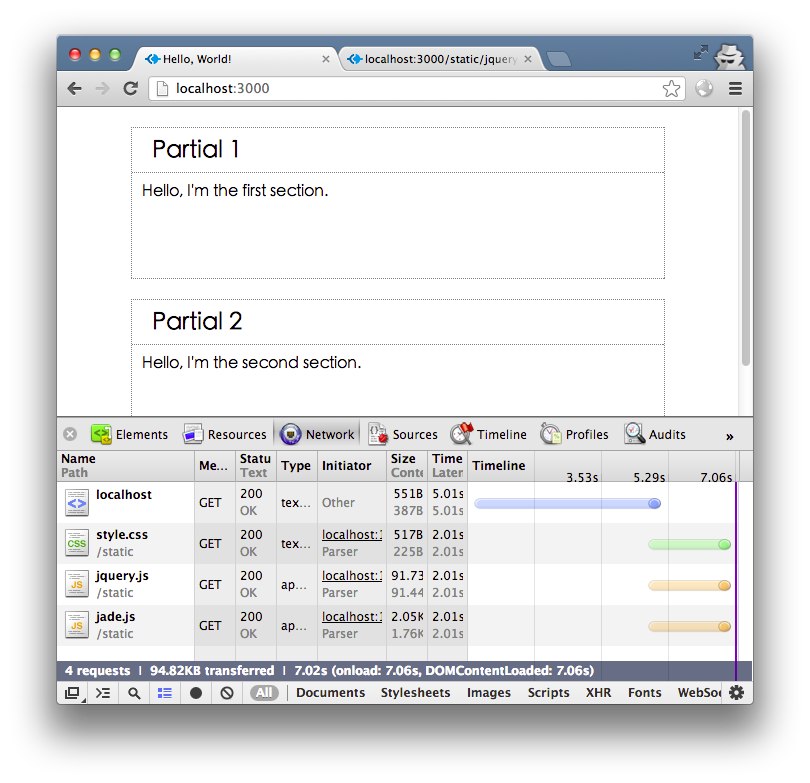
HTTP リクエストを受信したらすぐにヘッド部分を返し、その後 2 つのセクションが非同期操作が完了するまで待ってから返す場合、これは HTTP チャンク転送エンコーディング メカニズムを使用しています。 node.js では、res.write() メソッドを使用している限り、Transfer-Encoding: chunked ヘッダーが自動的に追加されます。このように、ブラウザーが静的ファイルをロードしている間、ノードサーバーは非同期呼び出しの結果を待っています。まず、layout.jade 内の次の 2 行を削除しましょう。
セクション#s2!=s2
を手動で追加しました。
res.render('レイアウト', function (err, str) {
(err) の場合は、res.req.next(err)
を返します res.setHeader('content-type', 'text/html; charset=utf-8')
res.write(str)
})
var n = 2
getData.d1(関数 (err, s1data) {
res.write('
--n || res.end()
})
getData.d2(関数 (err, s2data) {
res.write('
--n || res.end()
})
})
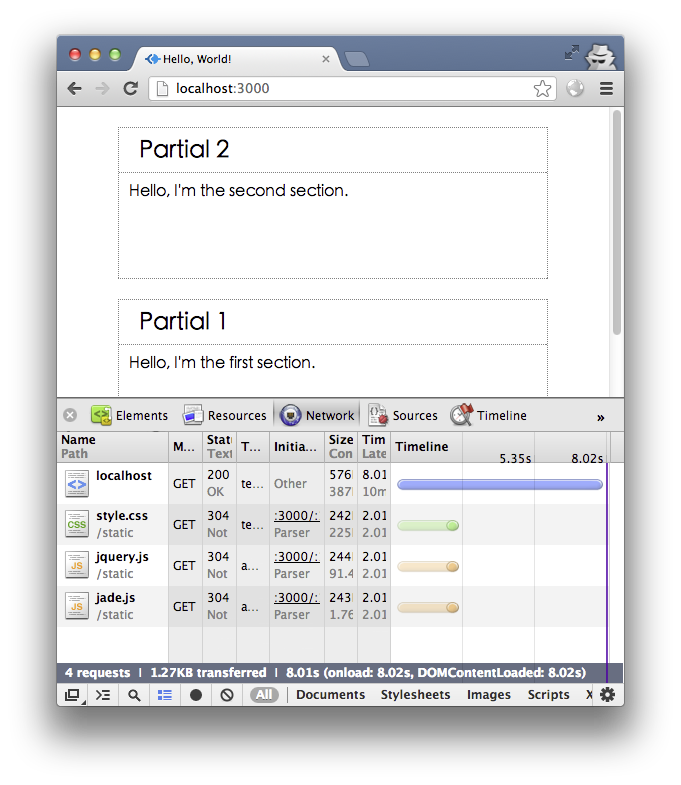
ただし、この効果は getData.d1 が getData.d2 よりも高速であるため実現できることに注意してください。つまり、Web ページ内のどのブロックが最初に返されるかは、最初に返されるインターフェイスの非同期呼び出しの結果によって決まります。 getData を 8 秒に変更して返すと、Partial 2 が最初に返され、s1 と s2 の順序が逆になり、Web ページの最終的な結果は期待と一致しません。
基本的な考え方は、最初に Web ページ全体の一般的なフレームを転送し、後で転送する必要がある部分は空の div (または他のタグ) で表されます。
res.render('レイアウト', function (err, str) {
if (err) return res.req.next(err)
res.setHeader('content-type', 'text/html; charset=utf-8')
res.write(str)
res.write('')
})
次に、JavaScript を使用して返されたデータを書き込みます
getData.d1(関数 (err, s1data) {
res.write('<script>$("#s1").html("'temp.s1(s1data).replace(/"/g, '\"') '")</script>')
--n || res.end()
})
s2 も同様に処理されます。このとき、Web ページのリクエストの 2 秒目に 2 つの空白の点線ボックスが表示され、5 秒目に部分 2 部分が表示され、8 秒目に部分 1 部分が表示され、Web ページが表示されます。リクエストが完了しました。
この時点で、最も単純な BigPipe テクノロジーを実装した Web ページが完成しました。
書き込まれる Web ページのフラグメントには script タグがあることに注意してください。たとえば、s1.jade を次のように変更します。
.content!=コンテンツ
スクリプト
alert("s1.jadeからのアラート")
var resProto = require('express/lib/response')
resProto.pipe = 関数 (セレクター、HTML、置換) {
this.write('<script>' '$("' セレクター '").' <br> (replace === true ? 'replaceWith' : 'html') <br> '("' html.replace(/"/g, '\"').replace(/</script>/g, '<\/script>')
'")')
}
function PipeName (res, name) {
res.pipeCount = res.pipeCount || 0
res.pipeMap = res.pipeMap || {}
if (res.pipeMap[名前]) return
res.pipeCount
res.pipeMap[name] = this.id = ['pipe', Math.random().toString().substring(2), (new Date()).valueOf()].join('_')
this.res = レス
this.name = 名前
}
resProto.pipeName = 関数 (名前) {
新しい PipeName(this, name) を返します
}
resProto.pipeLayout = 関数 (ビュー、オプション) {
var res = これ
Object.keys(オプション).forEach(関数(キー) {
if (options[key] instanceof PipeName) options[key] = ''
})
res.render(view, options, function (err, str) {
if (err) return res.req.next(err)
res.setHeader('content-type', 'text/html; charset=utf-8')
res.write(str)
if (!res.pipeCount) res.end()
})
}
resProto.pipePartial = 関数 (名前、ビュー、オプション) {
var res = これ
res.render(view, options, function (err, str) {
if (err) return res.req.next(err)
res.pipe('#' res.pipeMap[名前], str, true)
--res.pipeCount || res.end()
})
}
app.get('/', function (req, res) {
res.pipeLayout('レイアウト', {
s1: res.pipeName('s1name')
、s2: res.pipeName('s2name')
})
getData.d1(関数 (err, s1data) {
res.pipePartial('s1name', 's1', s1data)
})
getData.d2(関数 (err, s2data) {
res.pipePartial('s2name', 's2', s2data)
})
})
还要layout.jade把握两个セクション追加回来:
セクション#s1!=s1
セクション#s2!=s2
ここでの考えは、必要な Pipe のコンテンツは、最初にスパンを使用して占有され、データを取得して染まり、対応する HTML のコードを完了した後に再出力され、jQuery の replaceWith メソッドを使用してスパンを占有します。
本文の代コード在https://github.com/undozen/bigpipe-on-node 、我掴每一步做成一个 commit 了、希望你 clone へ本地实际运行并 hack 一下看ご覧のとおり、次の手順は追加シーケンスに関係しているため、自分でブラウザを起動して図から確認することはできません (これは gif アニメーションを使用して実行できますが、私たちはこれを実現しました)。
BigPipe の実践に関しては、非常に大きな拡張空間があり、パイプのコンテンツは、開始時間の設定が最適であり、実行された場合にデータがすぐに返され、BigPipe を使用する必要がなく、直接ネットワーク送信を生成します。つまり、BigPipe を使用すると、ajax と比較して、ノードから Node.js サーバーへのリクエスト数が節約され、また、node.js サーバーからデータ ソースへのリクエスト数も節約されます。普及と実践の方法は、Snowball ネットワーク上の BigPipe に保存され、その後再共有されます。