
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
处理的是一个.js文件,中间包含大量insert命令和update命令。一个命令占一行。
文件大小为222M.
错误信息如下: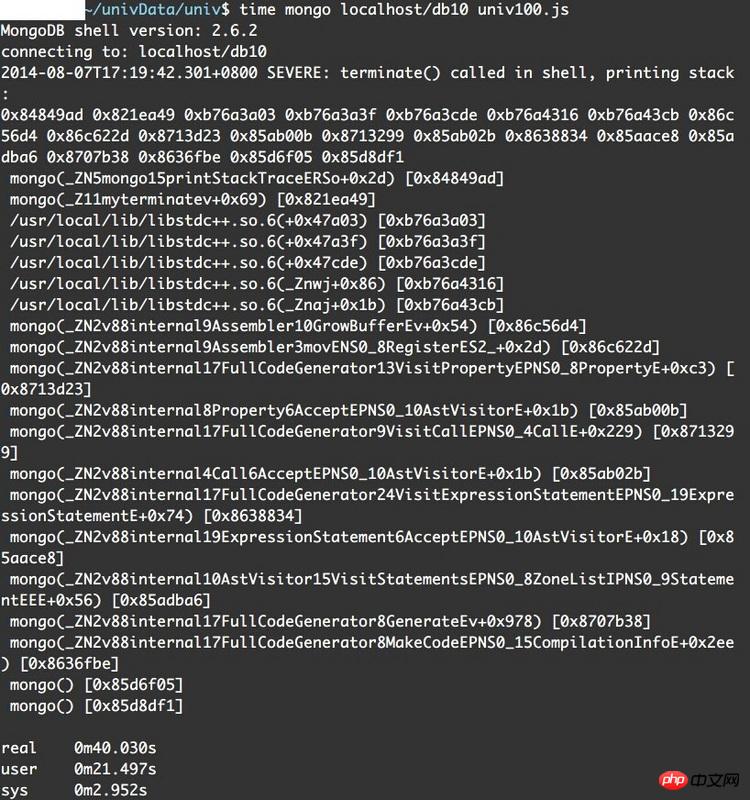
我猜测可能是因为单条命令太长的缘故,但是用mongo直接处理.js文件按理说不会有这样的问题才对吧
系统是debian 32位,版本2.6.32-5-386
在stackoverflow和segmentfault找,也只看到有人遇到堆栈信息中是_ZN5开头的。
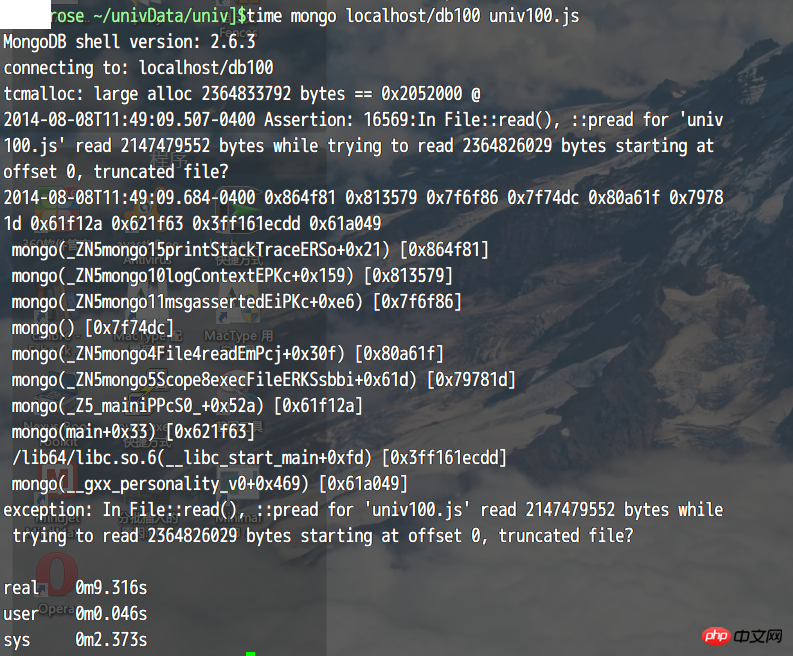
在64位mongodb上运行成功了。
但是64位加载2.3G文件的时候又有错误,好在这次有明确信息了。
拆成200多M的文件就能处理了。
很奇怪,我在mongodb文档中没看到说有这种限制啊
connecting to: localhost/test
tcmalloc: large alloc 2364833792 bytes == 0x2658000 @
2014-08-19T21:49:28.069-0400 Assertion: 16569:In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
2014-08-19T21:49:28.164-0400 0x864f81 0x813579 0x7f6f86 0x7f74dc 0x80a61f 0x79781d 0x61f12a 0x621f63 0x3ff161ecdd 0x61a049
mongo(_ZN5mongo15printStackTraceERSo+0x21) [0x864f81]
mongo(_ZN5mongo10logContextEPKc+0x159) [0x813579]
mongo(_ZN5mongo11msgassertedEiPKc+0xe6) [0x7f6f86]
mongo() [0x7f74dc]
mongo(_ZN5mongo4File4readEmPcj+0x30f) [0x80a61f]
mongo(_ZN5mongo5Scope8execFileERKSsbbi+0x61d) [0x79781d]
mongo(_Z5_mainiPPcS0_+0x52a) [0x61f12a]
mongo(main+0x33) [0x621f63]
/lib64/libc.so.6(__libc_start_main+0xfd) [0x3ff161ecdd]
mongo(__gxx_personality_v0+0x469) [0x61a049]
exception: In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
real 0m7.922s
user 0m0.045s
sys 0m2.477s

高洛峰2017-04-24 09:12:13
Merci beaucoup pour votre rapport.
Tout d'abord, la trace de la pile est mutilée par gcc et peut être vue à l'envers à l'aide du démangleur.
En supposant que votre serveur soit 2.6.3 comme le shell, le problème réside directement ici. Le shell va lire l'intégralité du fichier script en mémoire puis le compiler. Cela peut s'expliquer par un problème avec le fichier 2.3G sur un 32. -machine à bits. Mais cela ne devrait pas poser de problèmes sur les machines 64 bits.
Il y a deux questions ici.
1. La taille du fichier JS doit être limitée à 2G pour être compatible avec les systèmes d'exploitation 32 bits. La logique actuelle est correcte, mais la limite supérieure est trop grande et ne correspond pas à la description.
2. Lors de la lecture d'un fichier, le système ne peut pas toujours garantir qu'il sera lu en un seul appel pread, il est donc préférable de le lire plusieurs fois dans file.cpp jusqu'à ce qu'il se termine ou qu'une erreur se produise.
J'espère avoir clarifié le problème. Une solution temporaire consiste à faire ce que vous avez fait et à diviser le fichier en morceaux plus petits. Ce serait formidable si vous pouviez soumettre ce problème dans Jira, en décrivant simplement le problème que vous rencontrez en anglais. Les ingénieurs du noyau l'amélioreront lors des développements futurs, et vous pourrez également suivre ce problème sur Jira. Si cela ne vous convient pas, je peux le soumettre pour vous.
Une meilleure façon est de forker le code MongoDB sur Github après avoir soumis le rapport sur Jira, de le modifier, puis de soumettre une Pull Request. L'ingénieur du noyau le révisera et enfin le fusionnera dans la base de code. Étant donné que ce problème est relativement rare, relativement indépendant et relativement clair, il est très approprié de soumettre une Pull Request après avoir terminé une petite tâche. Ensuite, les utilisateurs de MongoDB du monde entier exécutent le code que vous avez écrit. Je pense qu'avec le grand nombre d'utilisateurs de MongoDB en Chine, nous avons la possibilité de contribuer à la communauté MongoDB. Si vous avez d'autres questions, dites-le-moi.
P.S. Je suis curieux de savoir pourquoi vous avez besoin d'un script 2.3G, si vous pouvez me dire ce que vous essayez de faire, il existe peut-être une solution plus élégante.
