
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
使用python实现模拟登陆并爬取返回页面的时候出现了乱码,目标网页的编码使用utf-8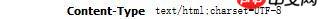
相关代码:
#coding=utf-8
import urllib
import urllib2
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36'
}
payload={
'_eventId':'submit',
'lt':'_cF2A0EB3F-D044-046C-6F4A-C828DE0ACE8E_k8B4BE5F5-4CAD-375D-0DDC-FB84A18445DF',
'password':'',
'submit':'登 录',
'username':''
}
payload=urllib.urlencode(payload)
request = urllib2.Request(posturl, payload, headers)
print request
response = urllib2.urlopen(request)
text = response.read()
print text
控制台输出信息:
第一次遇见这种乱码比较懵逼

PHPz2017-04-18 10:36:03
urllib2 ne gère pas les problèmes de compression, il faut utiliser gzip pour décompresser, comme ça
from StringIO import StringIO
import gzip
if response.info().get('Content-Encoding') == 'gzip':
buf = StringIO(text)
f = gzip.GzipFile(fileobj=buf)
data = f.read()
En résumé, urllib2 est de niveau relativement bas, et il est recommandé d'utiliser des requêtes
