
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
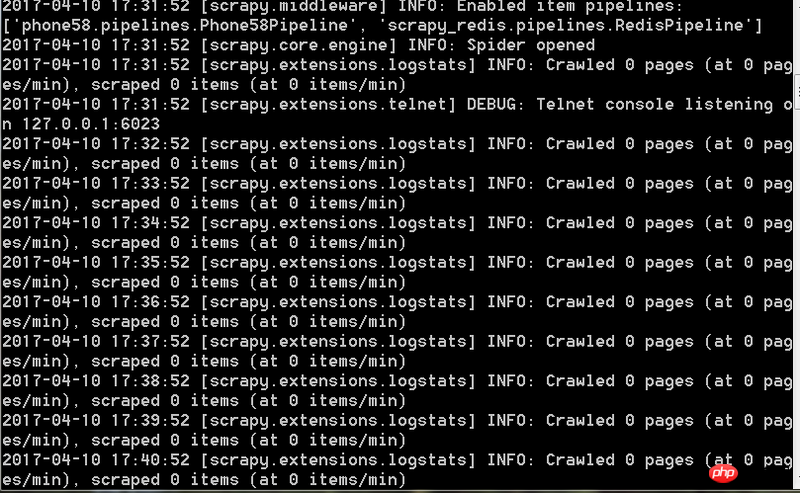
爬虫运行时一直是这样的每一分钟出现一条这样的信息,无限循环。不能爬取下来数据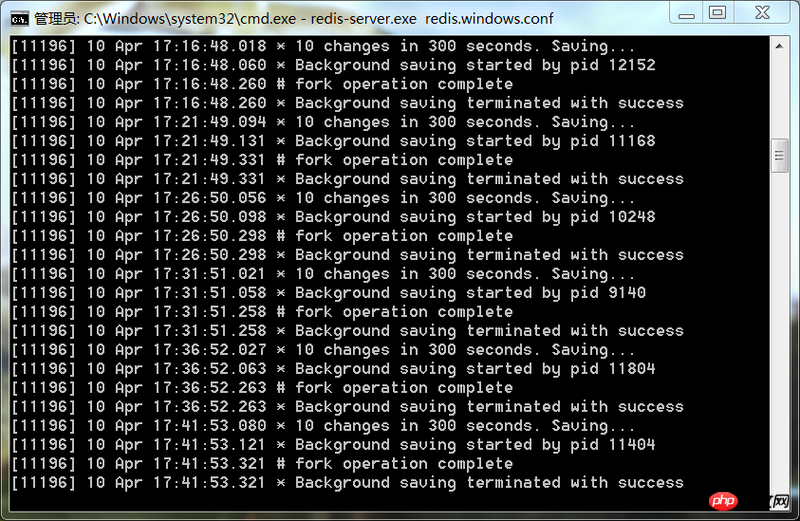
这是redis服务端的显示
这样是什么问题,望有高手可以为我解惑,谢谢。

大家讲道理2017-04-18 10:34:53
En utilisant scrapy_redis, vous devez placer l'URL pour que l'araignée puisse explorer. L'avez-vous placée ?
Par exemple
redis-cli lpush myspider:start_urls http://google.com