- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte

PHP中文网2017-04-18 10:34:17
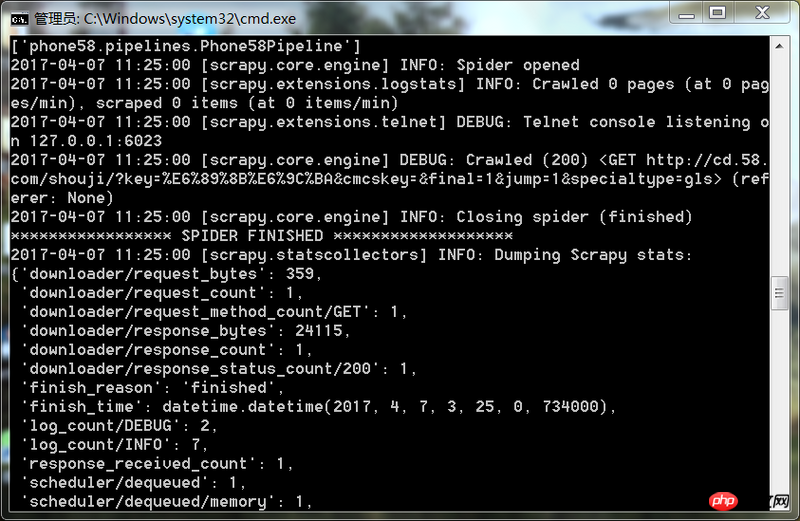
Il est probable que vos règles d'exploration soient fausses, c'est-à-dire que les règles XPath (ou d'autres outils d'analyse) dans votre code Spider sont fausses. En conséquence, il n’a pas été exploré. Vous pouvez imprimer l'URL et voir si c'est le cas []