
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
爬取了一个用户的论坛数据,但是这个数据库中有重复的数据,于是我想把重复的数据项给去掉。数据库的结构如下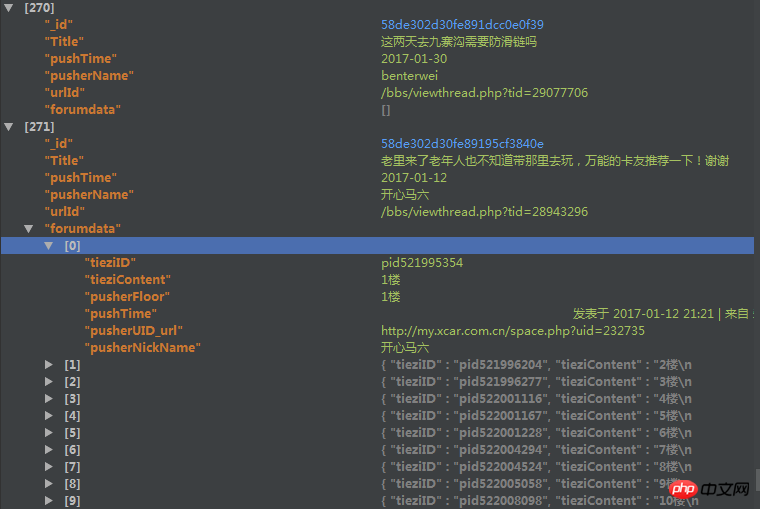
里边的forundata是这个帖子的每个楼层的发言情况。
但是因为帖子爬取的时候有可能重复爬取了,我现在想根据里边的urlId来去掉重复的帖子,但是在去除的时候我想保留帖子的forumdata(是list类型)字段中列表长度最长的那个。
用mongodb的distinct方法只能返回重复了的帖子urlId,都不返回重复帖子的其他信息,我没法定位。。。假如重复50000个,那么我还要根据这些返回的urlId去数据库中find之后再在mongodb外边代码修改吗?可是即使这样,我发现运行的时候速度特别慢。
之后我用了group函数,但是在reduce函数中,因为我要比较forumdata函数的大小,然后决定保留哪一个forumdata,所以我要传入forumdata,但是有些forumdata大小超过了16M,导致报错,然后这样有什么解决办法吗?
或者用第三种方法,用Map_reduce,但是我在map-reduce中的reduce传入的forumdata大小限制竟然是8M,还是报错。。。
代码如下
group的代码:
reducefunc=Code(
'function(doc,prev){'
'if (prev==null){'
'prev=doc'
'}'
'if(prev!=null){'
'if (doc.forumdata.lenth>prev.forumdata.lenth){'
'prev=doc'
'}'
'}'
'}'
)
map_reduce的代码:
reducefunc=Code(
'function(urlId,forumdata){'
'if(forumdata.lenth=1){'
'return forumdata[0];'
'}'
'else if(forumdata[0].lenth>forumdata[1].lenth){'
'return forumdata[0];'
'}'
'else{'
'return forumdata[1]}'
'}'
)
mapfunc=Code(
'function(){'
'emit(this.urlId,this.forumdata)'
'}'
)望各位高手帮我看看这个问题该怎么解决,三个方案中随便各一个就好,或者重新帮我分析一个思路,感激不尽。
鄙人新人,问题有描述不到位的地方请提出来,我会立即补充完善。

黄舟2017-04-18 10:34:12
Si ce problème n'a pas encore été résolu, vous souhaiterez peut-être envisager les idées suivantes :
1. L'agrégation est recommandée dans MongoDB, mais map-reduce n'est pas recommandé ;
2. Parmi vos exigences, un point très important est d'obtenir la longueur de Forumdata : la longueur du tableau, afin de trouver le document avec la longueur de tableau la plus longue. Votre article d'origine disait que Forumdata est une liste (il devrait s'agir d'un tableau dans MongoDB) ; MongoDB fournit l'opérateur $size pour obtenir la taille du tableau.
Veuillez vous référer aux marrons ci-dessous :
> db.data.aggregate([ {$project : { "_id" : 1, "name" : 1, "num" : 1, "length" : { $size : "$num"}}}])
{ "_id" : ObjectId("58e631a5f21e5d618900ec20"), "name" : "a", "num" : [ 12, 123, 22, 34, 1 ], "length" : 5 }
{ "_id" : ObjectId("58e631a5f21e5d618900ec21"), "name" : "b", "num" : [ 42, 22 ], "length" : 2 }
{ "_id" : ObjectId("58e631a7f21e5d618900ec22"), "name" : "c", "num" : [ 49 ], "length" : 1 }3. Après avoir obtenu les données ci-dessus, vous pouvez ensuite utiliser $sort, $group, etc. en agrégation pour trouver l'objectId du document qui répond à vos besoins. Pour des méthodes spécifiques, veuillez vous référer au post suivant : <🎜. >
https://segmentfault.com/q/10...4. Enfin, supprimez les ObjectIds associés par lots
Similaire à :
var dupls = [] Enregistrez l'ID d'objet à supprimer
db.collectionName.remove({_id:{$in:dupls}})
J'adore MongoDB ! Amusez-vous !

迷茫2017-04-18 10:34:12
Si la quantité de données n'est pas très importante, vous pouvez envisager de l'explorer à nouveau et de l'interroger à chaque fois que vous l'enregistrez. Seul l'ensemble de données contenant le plus de données sera enregistré.
Excellente stratégie de robot d'exploration>>Excellente stratégie de nettoyage des données

PHPz2017-04-18 10:34:12
Merci les internautes. Dans le groupe qq, quelqu'un a donné une idée. Dans map, forumdata est d'abord traité avec urlId, et urlId et forumdatad.length sont ensuite traités en réduisant, en gardant forumdata.length au maximum. . Celui-ci et l'urlId correspondant sont finalement enregistrés dans une base de données, puis toutes les données sont lues à partir de la base de données d'origine via l'urlId de cette base de données. Je l'ai essayé. Bien que l'efficacité ne soit pas celle à laquelle je m'attendais, la vitesse est toujours beaucoup plus rapide que l'utilisation de Python auparavant.
Joindre la carte et réduire les codes :
'''javaScript
mapfunc=Code(
'function(){'
'data=new Array();'
'data={lenth:this.forumdata.length,'
'id:this._id};'
# 'data=this._id;'
'emit({"id":this.urlId},data);'
'}'
)
reducefunc=Code(
'function(tieziID,dataset){'
'reduceid=null;'
'reducelenth=0;'
''
''
'redecenum1=0;'
'redecenum2=0;'
''
'dataset.forEach(function(val){'
'if(reducelenth<=val["lenth"]){'
'reducelenth=val["lenth"];'
'reduceid=val["id"];'
'redecenum1+=1;'
'}'
'redecenum2+=1;'
'});'
'return {"lenth":reducelenth,"id":reduceid};'
'}'
)上边是先导出一个新的数据库的代码,下边是处理这个数据库的代码:
mapfunc=Code(
'function(){'
# 'data=new Array();'
'lenth=this.forumdata.length;'
''
'emit(this.urlId,lenth);'
'}')
reducefunc=Code(
'function(key,value){'
'return value;'
'}')
之后添加到相应的map_reduce中就行了。
感觉Bgou回答的不错,所以就选他的答案了,还没有去实践。上边是我的做法,就当以后给遇到同样问题的人有一个参考。
