
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
各位好,我写了1个非常简单的爬虫去爬取51job里的招聘信息。从下面的链接里提取出每个招聘岗位的链接(一共50个链接)
http://search.51job.com/jobse...
再根据每个招聘岗位的url为每个岗位生成一个id,并且爬取每个岗位链接中的标题。最后把生成的信息打印到屏幕上。每次运行时内存占用率都会持续上升,最后导致电脑停止响应。代码非常简单,但是找不到哪里有问题。。我的环境是Ubuntu16.04,Python3.5,Pycharm.
尝试了下不用Pycharm直接运行还是不行,只输出了十几条信息后就停了。运行的时候一开始cpu很高,内存持续增长到2g多,电脑基本停止响应,用手机拍了一个图。过了几分钟后,cpu使用率掉下来了,但是内存占用还是80%左右。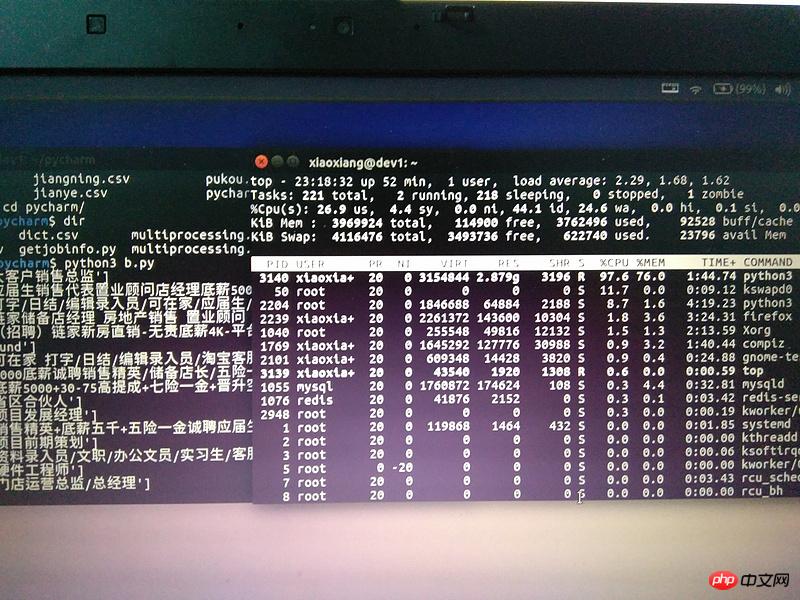
import requests
from lxml import etree
import re
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en-US,en;q=0.5",
"Connection": "keep-alive",
"Host": "jobs.51job.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
def generate_info(url):
html = requests.get(url, headers=headers)
html.encoding = 'GBK'
select = etree.HTML(html.text.encode('utf-8'))
job_id = re.sub('[^0-9]', '', url)
job_title=select.xpath('/html/body//h1/text()')
print(job_id,job_title)
sum_page='http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=070200%2C00&district=000000&funtype=0000&industrytype=00&issuedate=9&providesalary=06%2C07%2C08%2C09%2C10&keywordtype=2&curr_page=1&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&dibiaoid=0&confirmdate=9'
sum_html=requests.get(sum_page)
sum_select=etree.HTML(sum_html.text.encode('utf-8'))
urls= sum_select.xpath('//*[@id="resultList"]/p/p/span/a/@href')
for url in urls:
generate_info(url)

高洛峰2017-04-18 10:33:41
C'est un bug inactif
Enregistrez simplement les résultats dans un fichier~

阿神2017-04-18 10:33:41
J'ai essayé d'exécuter votre code et j'ai constaté qu'il n'occupait pas trop de mémoire. L'utilisation maximale de la mémoire n'était que de 30 Mo.
Je vous suggère d'essayer ce qui suit
Exécutez python xxx.py directement sur la ligne de commande sans utiliser Pycharm pour voir si cela est causé par Pycharm
Confirmez l'utilisation de la mémoire et l'utilisation du processeur pendant l'exécution
Comme vous l'avez dit, ce code est très simple et la charge de travail n'est pas importante, donc ce problème ne devrait pas se produire

黄舟2017-04-18 10:33:41
Pycharm rencontre parfois ce genre de difficulté. Il est recommandé de l'exécuter directement dans l'environnement python.
