- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
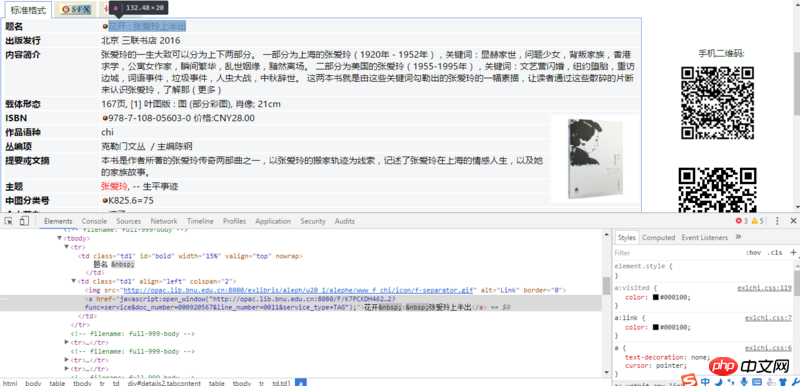
用scrapy爬了图书馆书籍的书名和评论,用Chrome的检查拔下来的Xpath,但是运行爬虫返回的是空元素,请问各位哪里出了问题,谢谢大家。
截图:
附上我的Scrapy源码,请大家多指教,谢谢!
from scrapy import Spider
from scrapy.selector import Selector
from CommentCrawl.items import CommentcrawlItem
class commentcrawl(Spider):
name = "commentcrawl"
allowed_domains = ["http://opac.lib.bnu.edu.cn:8080"]
start_urls = [
"http://opac.lib.bnu.edu.cn:8080/F/S9Q2QIQV5D9R9HBHPI2KNN8JH11TRIRSIEPKYQLTAQQ17LA6B6-16834?func=full-set-set&set_number=010408&set_entry=000001&format=999",
]
def parse(self,response):
item = CommentcrawlItem()
item['name'] = Selector(response).xpath('//*[@id="details2"]/table/tbody/tr[1]/td[2]/a/text()').extract()
item['comment'] = Selector(response).xpath('//*[@id="localreview"]/text()').extract()
yield item
黄舟2017-04-18 10:22:37
La page nécessite une connexion pour y accéder et ne dispose pas d'une opération de connexion.


伊谢尔伦2017-04-18 10:22:37
Imprimez ou enregistrez le contenu que vous avez réellement obtenu pour voir de quoi il s'agit. On estime que le contenu renvoyé ne correspond pas à votre XPath, vous devez donc vous connecter.