
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
需要爬取三峡水库的实时水情数据,可以在网页中选择日期显示水情信息,如果一天天选择再复制数据发现很是耗时,我现在需要将下图中三峡水利枢纽2014年-2016年每天的数据爬下来。

网址如下:
http://www.ctgpc.com.cn/sxjt/...
通过浏览器自带的检查工具,右键检查元素,查看 network,查看调用的 ajax API 地址:初步分析后发现是通过ajax调用了以下网址,并用POST传递了一个日期数据,例如今天2017-02-15给该网址:
http://www.ctgpc.com.cn/eport...
Header如下:
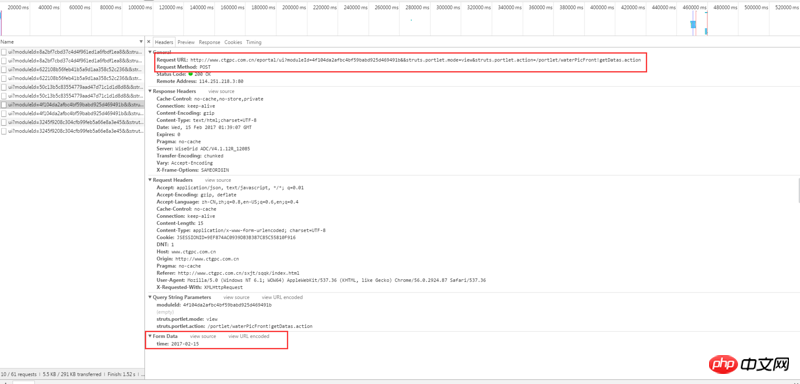
Response如下:

之前有搜索到类似的问题:https://segmentfault.com/q/10...
但是按照回答并没能解决我的疑惑,因此在这里求助各位前辈,麻烦大家了

伊谢尔伦2017-04-18 10:21:32
Vous pouvez utiliser la bibliothèque de requêtes pour simuler la soumission d'une publication. À partir de l'outil d'inspection du navigateur, vous pouvez voir que le paramètre transmis est time:2017-02-07. Définissez data={"time": date telle que 2017-02-07}. Ensuite, vous pouvez écrire une boucle qui parcourt la date et y ajoute un jour. Alors juste r = requests.post("url", data=data, header=****). Retirez les données et enregistrez-les dans la base de données. Si chaque cycle est trop lent, vous pouvez ajouter gevent, une bibliothèque de coroutines, pour accélérer le processus. Si vous souhaitez capturer 2 ans de données, effectuez un cycle 365*2 fois et tout ira bien
伊谢尔伦2017-04-18 10:21:32
Vous avez vu la demande avec des données, alors quelle est votre question ?

迷茫2017-04-18 10:21:32
Capturez le paquet, puis simulez la publication ou obtenez
Regardez le contenu suivant
Vidéo et code de mots d'association de robots Python
https://zhuanlan.zhihu.com/p/...
Apprenez le robot d'exploration Python pour capturer l'adresse IP du proxy et la vérification de Brother Huang.
https://zhuanlan.zhihu.com/p/...
Apprenez l'adresse IP du robot d'exploration Python auprès de frère Huang
https://zhuanlan.zhihu.com/p/...
