
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
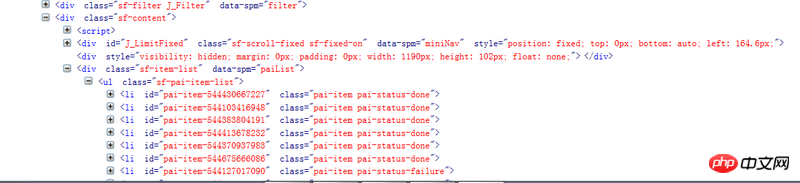
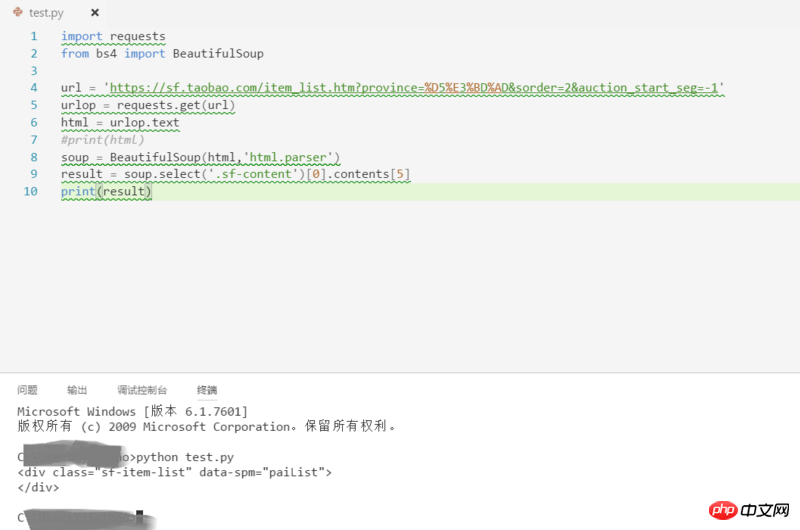
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~

ringa_lee2017-04-18 10:20:51
N'avez-vous jamais envisagé le chargement dynamique avec javascript ?

伊谢尔伦2017-04-18 10:20:51
Questionneur, si vous utilisez Chrome F12 pour le visualiser, il y aura du contenu chargé dynamiquement, et vous ne pouvez pas obtenir ce contenu en demandant directement l'URL de la page. Il est recommandé de cliquer avec le bouton droit pour afficher le code source de la page Web et de le comparer avec le contenu de F12. S'il n'y a pas de contenu dans le code source, vérifiez les autres requêtes du réseau pour voir s'il y a des données que vous avez. besoin.
