
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
def save_file(boy,girl,count):
file_name_boy = 'boy' + str(count) + '.txt'
file_name_girl = 'girl' + str(count) + '.txt'
boy_file = open(file_name_boy, 'w')
girl_file = open(file_name_girl, 'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close() #把两人的对话分别放到命名不同的文件里
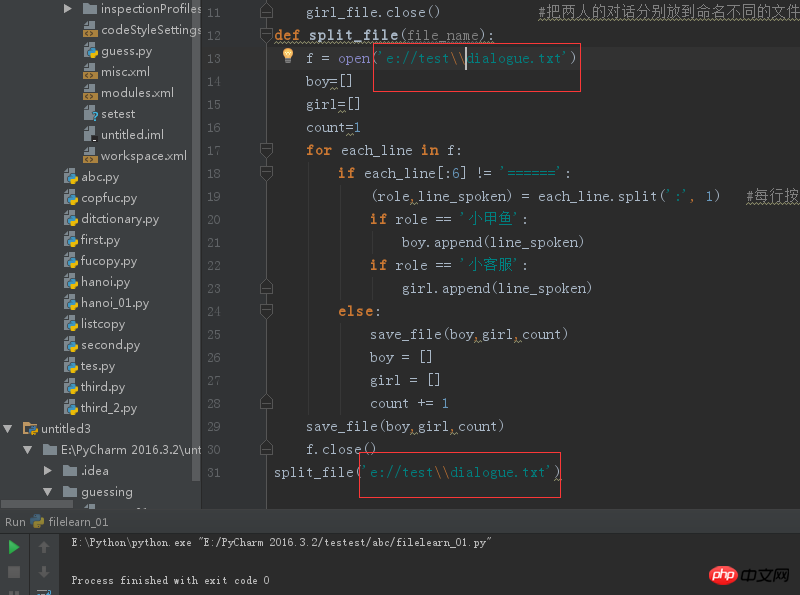
def split_file(file_name):
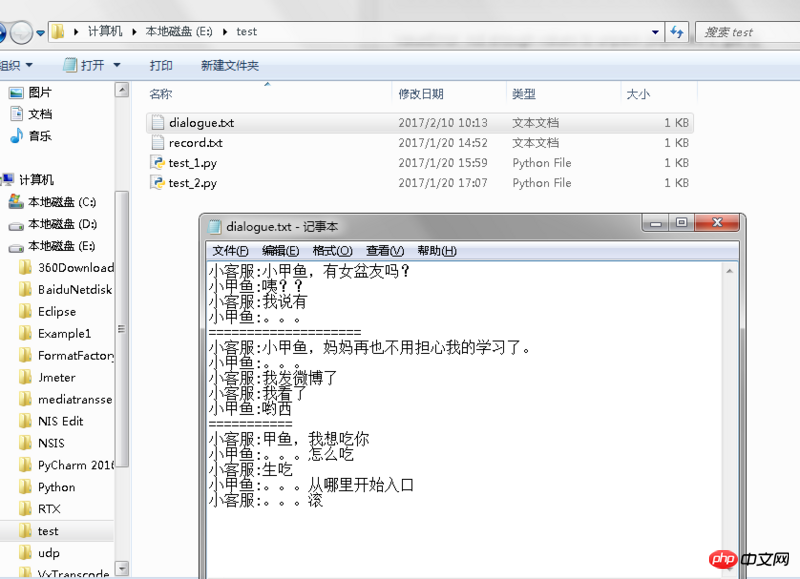
f = open('E:/test/dialogue.txt')
boy=[]
girl=[]
count=1
for each_line in f:
if each_line[:6] != '======':
(role,line_spoken) = each_line.split(':', 1) #每行按照:分割成1+1个子字符串,分别赋值给=前面的对象
if role == '小甲鱼':
boy.append(line_spoken)
if role == '小客服':
girl.append(line_spoken)
else:
save_file(boy,girl,count)
boy = []
girl = []
count += 1
save_file(boy,girl,count)
f.close()
split_file('E:/test/dialogue.txt')E:\Python\python.exe "E:/PyCharm 2016.3.2/testest/abc/filelearn_01.py"
Process finished with exit code 0http://edu.csdn.net/course/de... 是这个视频里的

天蓬老师2017-04-18 10:20:13
Déjà réussi. Recherche de mots-clés trouvés dans l'environnement de travail
De plus, 'e:test/dialogue.txt' est utilisé comme premier//, ce dernier peut être//ou ou/ou lorsque le premier//ou ; , ce dernier ne peut être utilisé que seul en pente.
Si vous êtes intéressé, vous pouvez l'essayer et me dire pourquoi

PHPz2017-04-18 10:20:13
Le message d'erreur n'est pas bien affiché. Il semble que l'erreur soit causée par ce code (role, line_spoken) = each_line.split(':', 1)
Lorsque la variable each_line ne contient pas :, un une erreur sera provoquée

阿神2017-04-18 10:20:13
Les problèmes d'encodage auront un plus grand impact dans python2, alors faites particulièrement attention
;L'encodage par défaut lors de l'enregistrement dans le Bloc-notes sous Windows est GBK, tandis que python2 le traite selon l'Unicode, donc lors de l'ouverture du fichier, il est recommandé de convertir d'abord l'encodage en Unicode pour éviter plus de problèmes ;
De plus, le caractère de nouvelle ligne dans le Bloc-notes est "n". Lorsque Python lit le fichier, il lira également le caractère de nouvelle ligne. Cela peut également causer des problèmes inutiles pour votre traitement ultérieur. caractère de nouvelle ligne. Talisman
Ensuite, il y a le problème des deux-points. La raison de l'erreur est que la méthode split ne peut pas trouver les deux-points donnés par votre code dans la chaîne each_line. Les deux points que vous avez donnés sont les deux points de l'état anglais, tandis que les deux points dans le fichier sont les deux points de l'état chinois. Mais si vous le changez directement en deux points chinois, il doit également être unifié en deux points chinois de la chaîne Unicode
L'étape suivante est le cas de comparaison chinois de role == 'Little Turtle'. Vous devez toujours indiquer à Python que vous utilisez des chaînes Unicode, afin de pouvoir effectuer la comparaison de manière relativement précise.
def split_file(file_name):
f = open('E:/test/dialogue.txt')
boy=[]
girl=[]
count=1
for each_line in f:
each_line = each_line.strip().decode('gbk') # strip()方法用来去掉"\n";decode()方法用来把编码从gbk解码到unicode
if each_line[:6] != '======':
# (role,line_spoken) = each_line.split(':', 1) #每行按照:分割成1+1个子字符串,分别赋值给=前面的对象
(role,line_spoken) = each_line.split(u':', 1) #注意这里的冒号是中文的冒号,u是告诉python这是个unicode的字符串
# if role == '小甲鱼':
if role == u'小甲鱼':
boy.append(line_spoken)
# if role == '小客服':
if role == u'小客服':
girl.append(line_spoken)
else:
save_file(boy,girl,count)
boy = []
girl = []
count += 1
save_file(boy,girl,count)
f.close()
高洛峰2017-04-18 10:20:13
Je pense que c’est une question de pleine largeur ou de demi-largeur.
Mais votre méthode n'est pas adaptée à la tolérance aux pannes.
Ma suggestion est :
split_result = each_line.split(':', 1)
if len(split_result) < 2:
raise RuntimeError()
(role,line_spoken) = (split_result[0], split_result[1])