
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
本人最近在特运通的电脑客户端内发现了感兴趣的信息,我现在想把里面的数据信息通过爬虫的形式获取下来,我想问下可以通过什么样的思路实现?
现在的基本思路是,通过fiddle或者Wireshark抓包,通过抓包的信息查看数据原链接,然后找规律去用python爬取,但是抓包的数据不知道如何使用,所以求大神指教~~
下图是抓包数据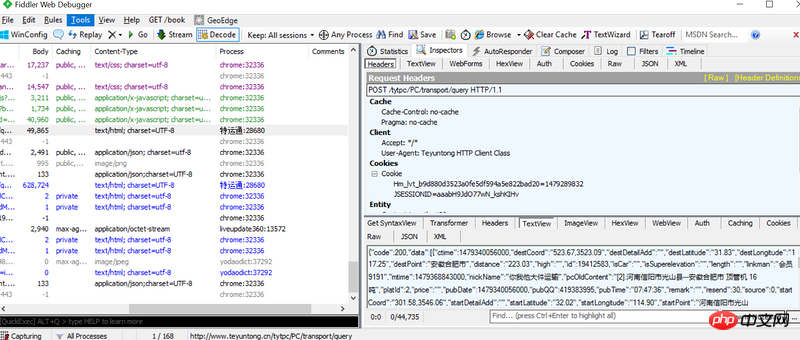


阿神2017-04-18 09:59:43
Apportez simplement les paramètres à la requête, générez l'URL et obtenez le contenu de l'URL
Regardez votre capture d'écran, les données json renvoyées, c'est facile à analyser. Je ne sais pas avec quelle étape vous rencontrez des difficultés en ce moment.
