
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
http://apk.hiapk.com/appinfo/...
我想要爬取这个网页中的用户评论
但是却发现使用urllib2.urlopen(request)获取的html页面不完整
代码如图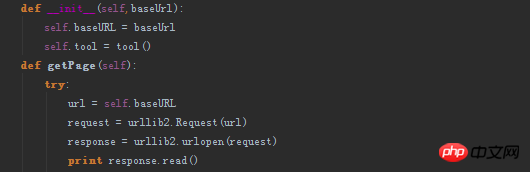

输出如图
但是实际上这个页面里面是有东西的
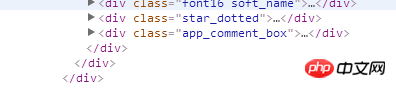
请问一下为什么获取到的html不全呢

PHP中文网2017-04-18 09:58:27
Ce n'est pas que la récupération soit incomplète. Les commentaires sur cette page sont générés via le post-chargement javascript. Le html demandé est renvoyé dans urllib2.urlopen et le javascript de la page ne sera pas exécuté
.Vous pouvez directement demander http://apk.hiapk.com/web/api.... Cette adresse peut renvoyer tous les commentaires, et c'est toujours du json, ce qui est très simple à gérer
