
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
在抓取360问答的时候,前面抓取得好好的,但是每次抓到大约40条的时候,就打不开了,所有的问题都打不开了,直接全部跳转到首页!我抓包了看了下,是被302了,请问下,除了换ip,还有什么比较好的方法来突破这种限制?
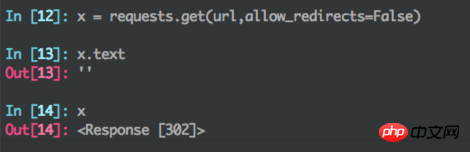
我设置了时间间隔,现在也不行了



阿神2017-04-18 09:50:26
La solution simple est de faire appel à un agent.
Définir l'intervalle de temps n'est généralement pas très utile dans le cas d'une exploration à grande échelle, si une adresse IP est consultée des centaines de fois, le code de vérification sera généralement redirigé.
