
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
目标url:
http://www.xiaopian.com/html/...
这个是chrome里显示的源代码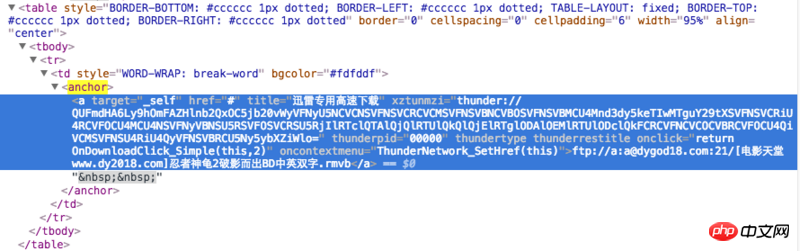
这个是scrapy shell url后用response.css().extract()显示东西
我想知道为何二者不一致?scrapy爬取到的信息并没有对应的thunder链接,而是明面上的ftp链接

黄舟2017-04-18 09:43:53
Pour afficher le code source d'une page Web, le robot doit cliquer avec le bouton droit sur > Afficher le code source de la page Web Au lieu de dans l'élément de révision, le code vu ici a été rendu par js, ce qui est différent. à partir du code d'origine, et le code obtenu par le robot d'exploration n'est pas rendu par js, c'est-à-dire le code d'origine.
J'ai jeté un coup d'œil et j'ai découvert que l'adresse de téléchargement de Thunder était calculée par js
Le code spécifique est le suivant :
function ThunderEncode(t_url) {
var thunderPrefix = "AA";
var thunderPosix = "ZZ";
var thunderTitle = "thunder://";
var thunderUrl = thunderTitle + base64encode(utf16to8(thunderPrefix + t_url + thunderPosix));
return thunderUrl;
}Je l'ai testé :
Passez l'adresse ftp://a:a@dygod18.com:21/[电影天堂www.dy2018.com]忍者神龟2破影而出BD中英双字.rmvb en paramètre et vous obtiendrez une connexion Thunder, mais ce n'est pas la même que celle de la page Web. Après décodage, l'URL encode le chinois. caractères. Tant que l'encodage est unifié, il n'y aura pas de problème.
