- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte

伊谢尔伦2017-04-18 09:33:41
Après des tests réels, la conclusion est que bs4 modifie l'ordre des attributs.
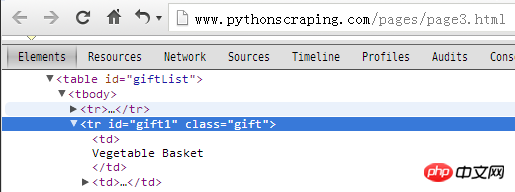
Élément d'inspection
Afficher le code source de la page Web
import re
ptn_tr = re.compile(r'<tr[^>]+>')
import requests as req
rsp=req.get('http://www.pythonscraping.com/pages/page3.html')
html = rsp.text
print('requests:\t', ptn_tr.findall(html)[0])
from urllib.request import urlopen
rsp = urlopen("http://www.pythonscraping.com/pages/page3.html")
html = rsp.read().decode()
print('urlopen:\t', ptn_tr.findall(html)[0])
from bs4 import BeautifulSoup
html = str(BeautifulSoup(html,"lxml"))
print('bs4Soup:\t', ptn_tr.findall(html)[0])
Résultat :
requests: <tr id="gift1" class="gift">
urlopen: <tr id="gift1" class="gift">
bs4Soup: <tr class="gift" id="gift1">
阿神2017-04-18 09:33:41
L'ordre de la classe et de l'identifiant est simplement différent.
Lorsque vous utilisez Chrome et Firefox pour afficher le code source de la même page Web, l'ordre est également différent.

高洛峰2017-04-18 09:33:41
Il est recommandé à la personne qui pose la question de publier le site Web ou même son propre code afin que d'autres puissent vous aider à le déboguer. Il est normal d'être différent. Si le contenu analysé par votre robot d'exploration est enregistré en tant que page statique et est différent de ce que vous voyez avec le navigateur, alors le mécanisme anti-crawler de l'autre partie doit l'avoir reconnu, donc le serveur renverra des informations différentes. . Il existe de nombreuses façons d'identifier les robots d'exploration. Si vous avez des questions, n'hésitez pas à les poser
.巴扎黑2017-04-18 09:33:41
L'affiche vous recommande de publier tout le code source, car le site Web peut identifier si vous utilisez un navigateur humain ou un robot d'exploration.
En regardant le code actuel, il est recommandé d'ajouter des informations d'en-tête ! use-agent Cette ligne de code !