
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
爬虫使用scrapy框架写的,使用脚本方式执行,配合APScheduler任务调度器定时执行,爬虫本身可以执行,只是定时执行失败,也没有报错误原因,日志见图,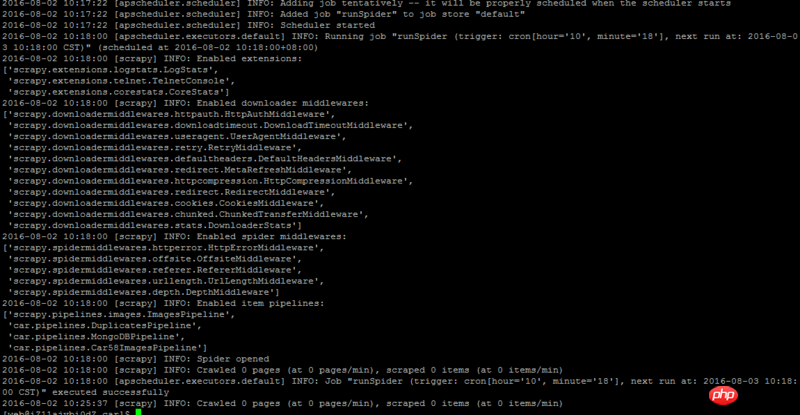
这是程序执行主要代码部分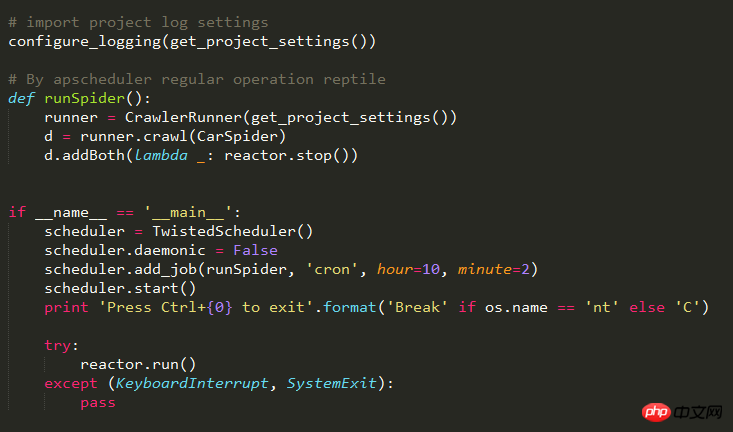
代码在windows系统可以运行,目前在Linux失败了,请问是什么原因?

ringa_lee2017-04-18 09:20:05
Après de nombreuses recherches et recherches sur le mur, je l'ai finalement fait fonctionner sous Linux. La première fois que j'ai planifié le travail du robot, il a été activé, mais il n'a pas analysé la page Web uniquement lorsque je l'ai planifié pour le. la deuxième fois, l'analyse a commencé et a fonctionné normalement. Je suppose que cela est lié à React.run(). Lorsque le cadre de planification des tâches Apscheduler est utilisé conjointement avec Scrapy, il doit être utilisé dans le cadre torsadé. Lorsque la tâche du robot doit être exécutée régulièrement, l'analyse ne sera pas effectuée pour la première fois, mais sera analysée pour la deuxième fois.
