
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
代码
'{"code":"A00185","data":"\\u5bf9\\u4e0d\\u8d77\\uff0c\\u60a8\\u77ed\\u65f6\\u95f4\\u53d1\\u8868\\u535a\\u6587\\u8fc7\\u591a\\uff0c\\u8bf7\\u591a\\u4f11\\u606f\\uff0c\\u6ce8\\u610f\\u8eab\\u4f53\\uff01\\u611f\\u8c22\\u60a8\\u5bf9\\u65b0\\u6d6a\\u535a\\u5ba2\\u7684\\u652f\\u6301\\u548c\\u5173\\u6ce8\\uff01"}'用正则不行,用replace不行,应该是\是属于转义符,不过因为访问的源码中,想把这个替换一下,要怎么处理!?
问题补充:
我是想把\\替换成\ 请问要怎么处理?
错如如下!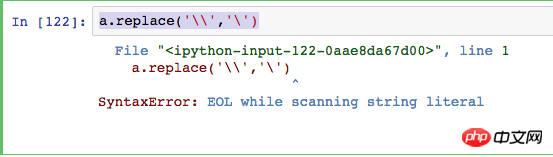
楼下一楼的大哥一直答不对题,我也是比较郁闷.我就想把一个字符串
\\的替换成\
然后想要如下结果:

其他的原理什么的其实我一点也不关心,最好是用一行代码就能回答问题的,万分感谢!

怪我咯2017-04-18 09:16:00
Dans le cas de
caractères de transfert, \=.
L'affiche originale disait non, alors je l'ai testé spécifiquement.
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
b = a.replace('\','hehehehe')
print(b);Le résultat est
{"code":"A00185","data":"heheheheu5bf9heheheheu4e0dheheheheu8d77heheheheuff0cheheheheu60a8heheheheu77edheheheheu65f6heh
heheu95f4heheheheu53d1heheheheu8868heheheheu535aheheheheu6587heheheheu8fc7heheheheu591aheheheheuff0cheheheheu8bf7hehehe
eu591aheheheheu4f11heheheheu606fheheheheuff0cheheheheu6ce8heheheheu610fheheheheu8eabheheheheu4f53heheheheuff01heheheheu
11fheheheheu8c22heheheheu60a8heheheheu5bf9heheheheu65b0heheheheu6d6aheheheheu535aheheheheu5ba2heheheheu7684heheheheu652
heheheheu6301heheheheu548cheheheheu5173heheheheu6ce8heheheheuff01"}J'ai vu l'extrait de code dans le nouveau message de l'affiche et je l'ai mis à jour à nouveau. L'affiche est devenue rouge sans voir l'invite de code ?
a.replace('\','\')Cette phrase est initialement mal écrite, car après ' escape échappe à un guillemet fermant, la deuxième chaîne est incomplète et, bien sûr, une erreur sera signalée.
De plus, selon la demande du questionneur, il n'est pas nécessaire de la remplacer, car cette chaîne est à l'origine un Lors de la définition d'une chaîne, écrire deux \ équivaut à un vrai . .
Peut être vérifié avec le code suivant :
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
print(a);Résultats de sortie
{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf
7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u630
1\u548c\u5173\u6ce8\uff01"}Après plusieurs négociations, j'ai enfin découvert le but de la question, qui est d'analyser le chinois en json. . .
Très simple
import json
a = '{"code":"A00185","data":"\u5bf9\u4e0d\u8d77\uff0c\u60a8\u77ed\u65f6\u95f4\u53d1\u8868\u535a\u6587\u8fc7\u591a\uff0c\u8bf7\u591a\u4f11\u606f\uff0c\u6ce8\u610f\u8eab\u4f53\uff01\u611f\u8c22\u60a8\u5bf9\u65b0\u6d6a\u535a\u5ba2\u7684\u652f\u6301\u548c\u5173\u6ce8\uff01"}'
js = json.loads(a)
print (js)Sortie
{'data': '对不起,您短时间发表博文过多,请多休息,注意身体!感谢您对新浪博客的支持和关注!', 'code': 'A00185'}