
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
最近想提取出特定的URL,遇到问题为预期提取出URL中带有webshell或者phpinfo字段的URL,但是全部URL都匹配出来了:
for url in urls:
if "webshell" or "phpinfo" in url:
print url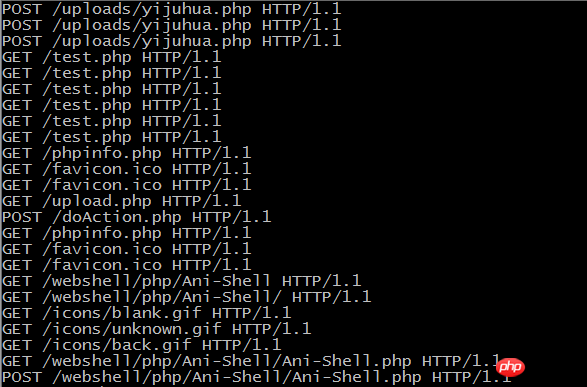
改成and语句也不符合预期,只提取出了含有phpinfo的url:
for url in urls:
if "webshell" and "phpinfo" in url:
print url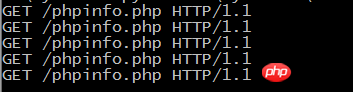

ringa_lee2017-04-18 09:07:15
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url
C'est ok, vous avez initialement jugé "webshell" en premier, et s'il n'est pas nul, alors jugez "phpinfo" dans l'url "webshell" et "phpinfo" dans l'url sont liés...

天蓬老师2017-04-18 09:07:15
if "webshell" or "phpinfo" in url: signifie if "webshell" ou if "phpinfo" in url et le premier est toujours vrai.
if "webshell" and "phpinfo" in url:Ce que cela signifie, c'est if "phpinfo" in url parce que if "webshell" est toujours vrai.
La solution est essentiellement comme @lock l'a dit :
for url in urls:
if "webshell" in url or "phpinfo" in url:
print url S'il y a beaucoup de mots utilisés pour correspondre aujourd'hui :
urls = [
'https://www.example.com/aaa',
'https://www.example.com/bbb',
'https://www.example.com/ccc',
]
def urlcontain(url, lst):
return any(seg for seg in url.split('/') if seg and seg in lst)
for url in urls:
if urlcontain(url, ['aaa', 'bbb']):
print(url)Résultat :
https://www.example.com/aaa
https://www.example.com/bbburlcontain(url, lst) Vous pouvez demander à url s'il y a une chaînelst dans
De cette façon, comparer dix mots-clés n’entraînera pas une instruction if trop longue.
Bien sûr, vous pouvez utiliser re, mais personnellement, je n'aime pas re c'est tout...
Questions auxquelles j'ai répondu : Python-QA
