- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
我想要爬取豆瓣音乐music.douban.com上的 新碟榜 和 近期热门歌单 ,看源代码好像都是js生成的,请教大家有什么办法可以爬到这些数据?谢谢!

高洛峰2017-04-17 17:58:25
J'utilise Jsoup pour écrire un robot d'exploration et je rencontre généralement du HTML qui ne renvoie aucun contenu. Mais le navigateur affiche du contenu. Ils analysent tous le journal des requêtes http de la page. Analysez le code JS de la page pour le résoudre.
1. Certains éléments de la page sont masqués->Changez le sélecteur pour résoudre le problème
2. Certaines données sont enregistrées dans les objets js/json->Interceptez la chaîne correspondante et analysez la solution
3. Via l'interface API Appel-> Fausse demande pour obtenir des données
Il existe également une méthode ultime
4. Utilisez un navigateur sans tête comme phantomjs ou casperjs

黄舟2017-04-17 17:58:25
Certaines des réponses mentionnent qu'il est possible d'analyser l'interface et d'explorer l'interface directement. De plus, si vous explorez directement l'interface, vous n'avez pas besoin d'analyser le code HTML vous-même, car la plupart des interfaces renvoient du json. Je me sens heureux rien que d'y penser ~
Cependant, il existe encore d'autres méthodes, comme l'utilisation de Phantomjs, qui est simple et facile à utiliser. Python n'est pas omnipotent, et il aura plus de valeur lorsqu'il sera associé à d'autres outils. J'ai aussi quelques petits projets qui le sont. une telle combinaison.
Il s'agit d'un exemple de code officiel, qui peut être réalisé avec une petite modification.
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://phantomjs.org/';
page.open(url, function (status) {
//Page is loaded!
phantom.exit();
});Rénovation
var page = require('webpage').create();
var url = 'http://phantomjs.org/';
page.open(url, function (status) {
page.evaluate(function() {
// 页面被执行完之后,一般js生成的内容也可以获得了,但是Ajax生成的内容则不一定
document.getElementById('xxx'); // 可以操作DOM,这里你就可以尝试获取你想要的内容了
// ...
})
phantom.exit();
});
Mais en fait, dans de nombreux cas, vous devez attendre qu'Ajax soit exécuté avant de commencer à analyser le contenu de la page. À ce stade, vous pouvez utiliser un exemple de code officiel. En utilisant cette fonction, vous pouvez attendre. toutes les demandes pour cette page doivent être chargées. Continuez ensuite le traitement, vous obtiendrez alors la page entièrement chargée, et vous pourrez alors faire tout ce que vous devez faire.


高洛峰2017-04-17 17:58:25
Exemple d'utilisation du sélénium pour extraire de nouvelles cartes de disques :
from selenium import webdriver
dirver = webdriver.Chrome()
dirver.get('https://music.douban.com/')
for i in dirver.find_elements_by_css_selector('.new-albums .album-title'):
print i.text
Résultat :
Ouvert aujourd'hui
L'histoire au chevet de Jay Chou
H.A.M.
3집EX'ACT
Wild
Femme dangereuse
Dans le noir
L'année dernière était Compliqué

阿神2017-04-17 17:58:25
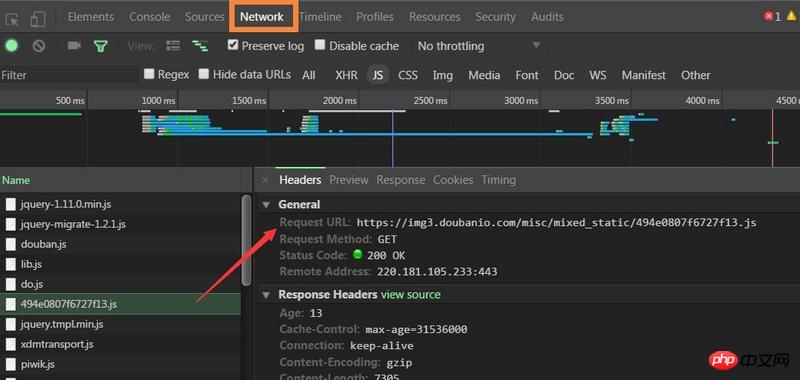
Chrome, appuyez sur F12, cliquez, affichez la requête, il est facile de trouver l'URL et les paramètres, construisez-la simplement vous-même, puis analysez le contenu renvoyé.

PHP中文网2017-04-17 17:58:25
Cette ligne de js est citée sous index.html.
<script type="text/javascript" src="https://img3.doubanio.com/misc/mixed_static/37fa28b9fa94889c.js"></script><script type="text/javascript">
Ouvrez ce fichier js et vous pourrez voir
React.render(React.createElement(component, {"moreUrl":"\/chart","sections":[{"albums":[{"name":"今日營業中","performers":"林宥.................PHP中文网2017-04-17 17:58:25
Ouvrez Chrome pour inspecter l'élément et recherchez js dans le réseau. Généralement, le js avec un nom spécial peut être ce que vous recherchez. Par exemple, celui-ci,