
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
最近初学用Python写网页爬虫视图扒取一个站点上的特定数据。
最近碰到的一个现象是,当爬虫运行了一段时间后(根据Fiddler抓包的结果来看,大概是发送了将近3万个http请求后),爬虫的获取的http响应的StatusCode骤然都变成了 504, 之后就再也获取不到200的响应了。
想请教一下各位大神,这种现象是否是由于扒取对象的站点的反爬虫策略造成的?
如果是的话,有什么常用的回避策略么?
P.S.
还注意到一个现象,不知与上述现象是否有关,一并描述:
即当爬虫的响应变成504之后,发现我的浏览器的代理选项被自动勾上了,如下所示:
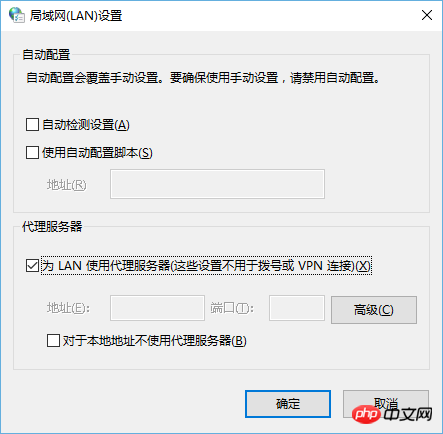

PHP中文网2017-04-17 17:27:54
L'option proxy est cochée, ce qui est dû à un violoniste. Dans le passé, j'utilisais souvent fiddler pour capturer des paquets. Après un certain temps, je ne pouvais plus accéder au réseau. Décocher l'option proxy a résolu le problème
.
ringa_lee2017-04-17 17:27:54
Vous pouvez prêter attention à un composant open source que j'ai écrit, mettant en place un pool de serveurs proxy pour empêcher le blocage des stratégies anti-crawler, et ajustant automatiquement la fréquence des requêtes, traitant les requêtes anormales et donnant la priorité aux agents avec des réponses rapides. . https://github.com/letcheng/ProxyPool

PHP中文网2017-04-17 17:27:54
1.Agent
2. Simuler une demande complète
3. Intervalles raisonnables
4.Déconnexion ADSL et recomposition

PHPz2017-04-17 17:27:54
Méthode :
Changez l'IP et utilisez une IP proxy. Il en existe de nombreuses gratuites et payantes en ligne
IP gratuite : http://www.uuip.net/
IP payante : http://www.daili666.net/


天蓬老师2017-04-17 17:27:54
Pourquoi la réponse à cette question est-elle ainsi ? L'erreur 50x réside dans le site Web lui-même