python爬虫 - Python 爬虫 提取网页信息
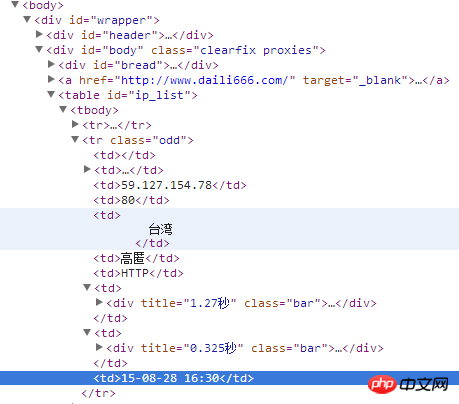
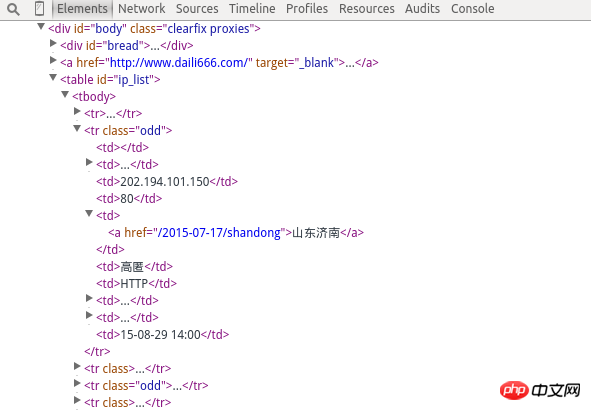
爬取网址是:http://www.xici.net.co/nn/1
以上是HTML网页内容,
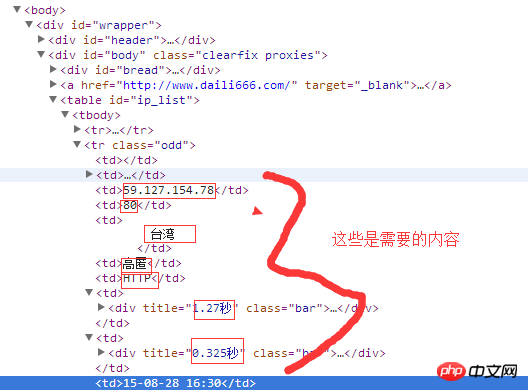
需获取IP地址,端口号,地方,是否高匿,两个时间
一下是我写的Python,但只能实现部分,请各位大神指点下
谢谢。。。。
import re
import urllib
a = raw_input('input url:')
s = urllib.urlopen(a)
s1 = s.read()
def getinfo(aaa):
#reg = re.compile(r'(?<![\.\d])(?:\d{1,3}\.){3}\d{1,3}(?![\.\d])')
#reg = re.compile(r'<td>(\d+)\.(\d+)\.(\d+)\.(\d+)</td>\s*<td>(\d+)</td>\s*<td>([/u4e00-/u9fa5]+)</td>')
reg = re.compile(r'<td>(\w+)</td>\s*<td>([\u4e00-\u9fa5]+)</td>')
l = re.findall(reg, aaa)
print l
getinfo(s1)结果是类似下面的,不一定是表格
|ip|端口号|位置|是否高匿|类型|速度|连接时间|验证时间|
|-|-|-|-|-|-|-|-|-|
|122.89.9.70|80|台湾|高匿|HTTP|1.27秒|0.325秒|15-08-28 16:30|
|123.69.48.45|8080|江苏南京|高匿|HTTPS|1.07秒|0.5秒|15-08-28 17:30|