- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
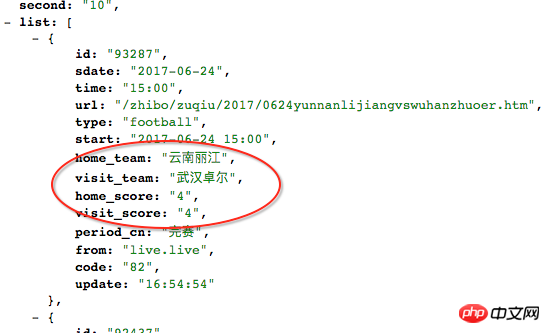
Je souhaite capturer les scores des événements diffusés en direct : liens de diffusion en direct, mais je ne peux capturer que la date, les équipes à domicile et à l'extérieur, etc. en utilisant Scrapy. Ma question est : les partitions sont-elles chargées via Script ? Est-ce dans bf4.js dans ce script ? Comment obtenir avec précision le score comme indiqué ci-dessous dans cette méthode de requête : situation GET ?
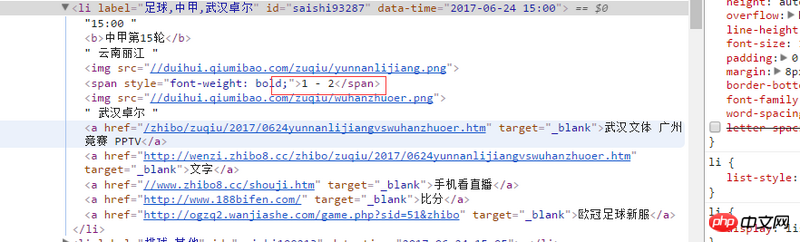
Le code source de la page web consultée via les outils de développement est le suivant : <li label="足球,中甲,武汉卓尔" id="saishi93287" data-time="2017-06-24 15:00">15:00 <b>中甲第15轮</b> 云南丽江 <img src="//duihui.qiumibao.com/zuqiu/yunnanlijiang.png" > <span> - </span> <img src="//duihui.qiumibao.com/zuqiu/wuhanzhuoer.png" > 武汉卓尔 <a href="/zhibo/zuqiu/2017/0624yunnanlijiangvswuhanzhuoer.htm" target="_blank">武汉文体 广州竞赛 PPTV</a> <a href="http://wenzi.zhibo8.cc/zhibo/zuqiu/2017/0624yunnanlijiangvswuhanzhuoer.htm" target="_blank">文字</a> <a href="//www.zhibo8.cc/shouji.htm" target="_blank">手机看直播</a> <a href="http://www.188bifen.com/" target="_blank">比分</a> <a href="http://ogzq2.wanjiashe.com/game.php?sid=51&zhibo" target="_blank">欧冠足球新服</a> </li>
C'est-à-dire que le score n'est pas affiché dans <span> - </span>. Comment puis-je capturer la page Web du score rendu ?